
How important are LLM evaluations to you?
A) Who cares?
B) Somewhat important (I guess?)
C) I'm an LLM, I evaluate myself.
D) Enough to join the pack
Lets talk about LLM evals here: go.bsky.app/DJpp8cy
How important are LLM evaluations to you?
A) Who cares?
B) Somewhat important (I guess?)
C) I'm an LLM, I evaluate myself.
D) Enough to join the pack
Lets talk about LLM evals here: go.bsky.app/DJpp8cy
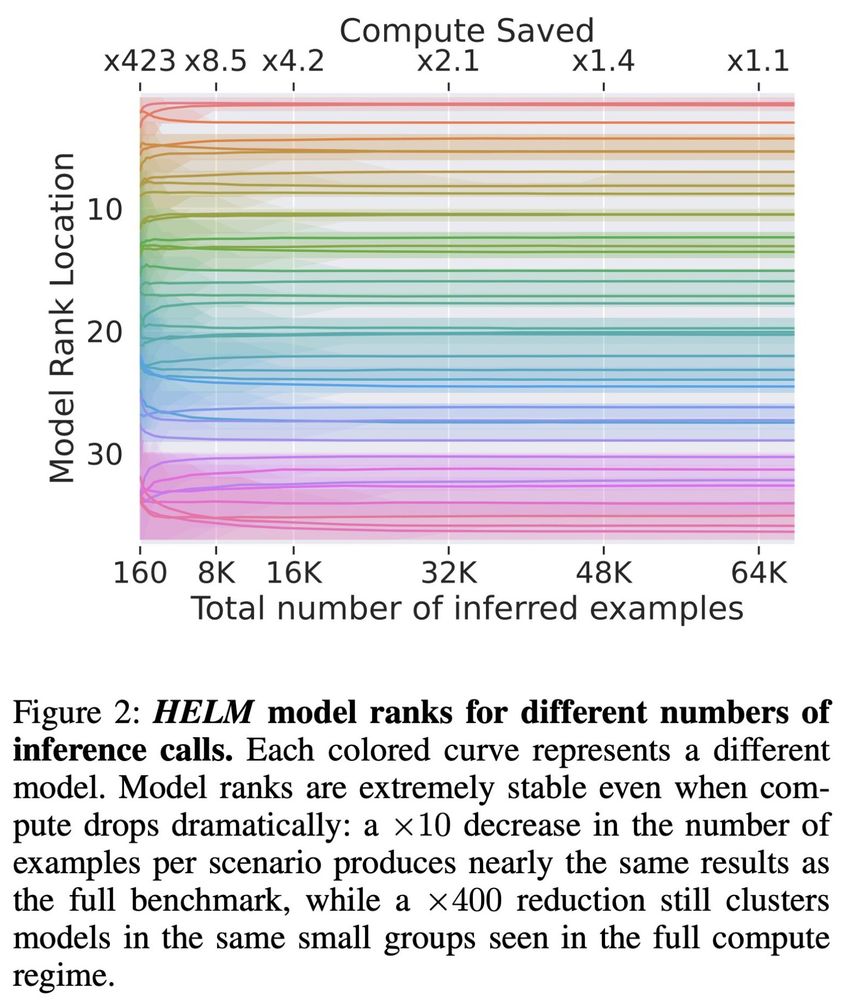
Save yourselves the hours (or days) inferring all 64K examples, when using HELM
In arxiv.org/pdf/2308.116... we show that 160 examples 🤯🤯🤯 is enough to get a very good picture, #ComputeIsForTraining.
with
@lchoshen.bsky.social and more
Thanks!
12.11.2024 19:51 — 👍 0 🔁 0 💬 0 📌 0@yamadashy
12.11.2024 19:50 — 👍 0 🔁 0 💬 0 📌 0
If you haven't tried it yet:
github.com/yamadashy/re...
will can turn your repo into one file,
making it super easy to feed to a chatbot asking questions

✨ Developed a new benchmark or dataset for language models? ✨
Want the community to trust and adopt it? 🤔
Show that it (dis)agrees with common benchmarks
BenchBench makes it easy. Check it out:
👉 huggingface.co/spaces/ibm/b...
hi @mariaa.bsky.social
Can I be added to the pack?
Mostly posting about AI evaluations and benchmarking :)
hi @maosbot.bsky.social can I be added to the AI pack?
mostly posting on Evaluations of AI but other things as well
Seems like it indeed measure what it claims to :)
Kudus to the authors
A faster, automatic (no annotators) alternative to the Chatbot arena https://t.co/WNk3UmXRSq
https://t.co/TZlMiQdgWR
22.10.2024 12:57 — 👍 0 🔁 0 💬 0 📌 0
we've now added the decentralized arena to benchbench,
check out how it fares with other benchmarks
https://t.co/pjhtr8CPZD
Get your benchmark game on: https://t.co/yY0swLQOHZ https://t.co/3qzkcIOd7u https://t.co/5Y7QUz0Ype
17.09.2024 18:42 — 👍 0 🔁 0 💬 0 📌 0
Me trying to choose the right LLM benchmark without BenchBench:
https://t.co/TZlMiQdgWR https://t.co/DQEttklUGQ
Shoutout to @streamlit, our framework of choice! Shoutout to @huggingface for hosting our space 🤗 https://t.co/z8LFw6ZQG7
17.09.2024 11:16 — 👍 0 🔁 0 💬 0 📌 0
Explore the BenchBench Leaderboard to explore and visualize how established benchmarks compare: https://t.co/yY0swLQgSr
Use our Python package to perform your own BAT analysis: https://t.co/iU8favWVT6
And read the paper: https://t.co/RvCp3R6gU5 https://t.co/poHpewZkS3
BenchBench can prove your benchmark measures unique skills ❄️(disagreement with existing benchmarks)
Or prove it captures the essence of others aimed at (agreement), for example, agreeing with @lmsys, but efficiently. https://t.co/KwtHtTRESc
✨ Developed a new benchmark or dataset for language models? ✨
Want the community to trust and adopt it? 🤔
So, demonstrate its validity by comparing it to established benchmarks!
BenchBench makes it easy. Check it out:
👉 https://t.co/yY0swLQgSr
Shout-out to the amazing team at IBM behind Unitxt: @ElronBandel, @MatanOrbach, yoavkatz, eladv, @LChoshen, @yotamperlitz & more!
IBM is betting big on it (IBM Research AI VP 👇) https://t.co/BKfK0JriYB
HELM just got a great upgrade!
We've integrated with Unitxt for:
Easy dataset addition
2x the datasets
Sharable & reproducible pipelines
Check out the blogpost: https://t.co/UJXwfPKzGN
And the unitxt repo
https://t.co/GeqMCoQhjv
@ElronBandel @YifanMai
Everyone knows you never have to use the full test set
We shows how much they were right 🤯!
Check out our presentation at @naacl
in Efficient/Low-Resources and Evaluation Methods for NLP (18 June 2024 @ 02:12)
or watch our video here:
https://t.co/pPOpKyLbhT
See you! https://t.co/ocVvmVBBlW
It is a great figure
and a great thing you did by sharing all your meta-data!
it had enabled a lot of great work
ours as well :)
https://t.co/9lGi8aW8IG https://t.co/Lz62fTdn7O
Bored with all benchmarks ranking models the same?
HOLMES doesn't 💪
Probing LMs for linguistic abilities is a fresh idea, @AndreasWaldis took it to the extreme 🦸
Give it a read!
or check out the leaderboard https://t.co/Byc1Nhp3nV https://t.co/zH0RLddkID
I've been working internally with this dataset
and let me tell you...
Its great! https://t.co/MOwn0OyVS3
like the color scheme 🏅 https://t.co/sdAosgxypV
13.02.2024 18:49 — 👍 0 🔁 0 💬 0 📌 0
Using contrastive representation for optimized human evaluation 👁️👁️👁️
Nice! https://t.co/49leLodOAQ
Check out the paper for more insights :) https://t.co/7zhb8mGtQ0
01.02.2024 21:35 — 👍 0 🔁 0 💬 0 📌 0
variance in evaluation has many sources,
this work really does a good job at profiling one of these https://t.co/nAf7zYDSd7
these models keeps changing 💩
tomorrow this figure will have no meaning https://t.co/OsA2WfiLHn
this is a nice to have link :) https://t.co/DYApcasZen
19.12.2023 14:33 — 👍 0 🔁 0 💬 0 📌 0seems like there are more latest findings similar to that, BTW @adinamwilliams , where can I find the full paper? https://t.co/sl1Jqa1R1R
12.12.2023 10:03 — 👍 0 🔁 0 💬 0 📌 0