
Natural Language Processing
How do you build Large Language Models? How do humans experience Natural Language Processing (NLP) applications in their daily lives? And how can we...
👀 Look what 🎅 has broght just before Christmas 🎁: a brand new Research Master in Natural Language Processing at @facultyofartsug.bsky.social @rug.nl
Program: www.rug.nl/masters/natu...
Applications (2026/2027) are open! Come and study with us (you will also learn why we have a 🐮 in our logo)
18.12.2025 11:28 — 👍 25 🔁 15 💬 0 📌 0

🧑🔬I’m recruiting PhD students in Natural Language Processing @unileipzig.bsky.social Computer Science, together with @scadsai.bsky.social!
Topics include, but aren’t limited to:
🔎Linguistic Interpretability
🌍Multilingual Evaluation
📖Computational Typology
Please share!
#NLProc #NLP
11.12.2025 13:36 — 👍 41 🔁 25 💬 1 📌 3

📢Out now in NEJLT!📢
In each of these sentences, a verb that doesn't usually encode motion is being used to convey that an object is moving to a destination.
Given that these usages are rare, complex, and creative, we ask:
Do LLMs understand what's going on in them?
🧵1/7
19.11.2025 13:56 — 👍 15 🔁 3 💬 2 📌 0

Screenshot of a figure with two panels, labeled (a) and (b). The caption reads: "Figure 1: (a) Illustration of messages (left) and strings (right) in toy domain. Blue = grammatical strings. Red = ungrammatical strings. (b) Surprisal (negative log probability) assigned to toy strings by GPT-2."
New work to appear @ TACL!
Language models (LMs) are remarkably good at generating novel well-formed sentences, leading to claims that they have mastered grammar.
Yet they often assign higher probability to ungrammatical strings than to grammatical strings.
How can both things be true? 🧵👇
10.11.2025 22:11 — 👍 91 🔁 20 💬 2 📌 3

I'm in Suzhou to present our work on MultiBLiMP, Friday @ 11:45 in the Multilinguality session (A301)!
Come check it out if your interested in multilingual linguistic evaluation of LLMs (there will be parse trees on the slides! There's still use for syntactic structure!)
arxiv.org/abs/2504.02768
06.11.2025 07:08 — 👍 27 🔁 7 💬 0 📌 0

accepted papers at main conference and findings

accepted papers at TACL and workshops
With only a week left for #EMNLP2025, we are happy to announce all the works we 🐮 will present 🥳 - come and say "hi" to our posters and presentations during the Main and the co-located events (*SEM and workshops) See you in Suzhou ✈️
27.10.2025 11:54 — 👍 16 🔁 5 💬 0 📌 3
BabyBabelLM
For more information check out the website, paper, and datasets:
Website: babylm.github.io/babybabellm/
Paper: arxiv.org/pdf/2510.10159
We hope BabyBabelLM will continue as a 'living resource', fostering both more efficient NLP methods, and opening ways for cross-lingual computational linguistics!
15.10.2025 10:53 — 👍 1 🔁 0 💬 0 📌 0

Next to our training resources, we also release an evaluation pipeline that assess different aspects of language learning.
We present results for various simple baseline models, but hope this can serve as a starting point for a multilingual BabyLM challenge in future years!
15.10.2025 10:53 — 👍 0 🔁 0 💬 1 📌 0

To deal with data imbalances, we divide languages into three Tiers. This better enables cross-lingual studies and makes it possible for low-resource languages to be a part of BabyBabelLM as well.
15.10.2025 10:53 — 👍 0 🔁 0 💬 1 📌 0

With a fantastic team of international collaborators we have developed a pipeline for creating LM training data from resources that children are exposed to.
We release this pipeline and welcome new contributions!
Website: babylm.github.io/babybabellm/
Paper: arxiv.org/pdf/2510.10159
15.10.2025 10:53 — 👍 1 🔁 1 💬 1 📌 0

🌍Introducing BabyBabelLM: A Multilingual Benchmark of Developmentally Plausible Training Data!
LLMs learn from vastly more data than humans ever experience. BabyLM challenges this paradigm by focusing on developmentally plausible data
We extend this effort to 45 new languages!
15.10.2025 10:53 — 👍 44 🔁 16 💬 1 📌 4
Wij speelden als kind (in Breda) vaak "1 keer tets", waar je een voetbal maximaal 1 keer mocht laten stuiteren; ik had ook geen idee dat dat een Brabants woord was.
01.09.2025 14:33 — 👍 1 🔁 0 💬 0 📌 0

Happening now at the SIGTYP poster session! Come talk to Leonie and me about MultiBLiMP!
01.08.2025 10:17 — 👍 20 🔁 2 💬 1 📌 0
I'll be in Vienna only from tomorrow, but today my star PhD student Marianne is already presenting some of our work:
BLIMP-NL, in which we create a large new dataset for syntactic evaluation of Dutch LLMs, and learn a lot about dataset creation, LLM evaluation and grammatical abilities on the way.
29.07.2025 09:46 — 👍 11 🔁 1 💬 1 📌 1
Congrats and good luck in Canada!
01.07.2025 23:05 — 👍 1 🔁 0 💬 0 📌 0

TurBLiMP: A Turkish Benchmark of Linguistic Minimal Pairs
We introduce TurBLiMP, the first Turkish benchmark of linguistic minimal pairs, designed to evaluate the linguistic abilities of monolingual and multilingual language models (LMs). Covering 16 linguis...
Proud to introduce TurBLiMP, the 1st benchmark of minimal pairs for free-order, morphologically rich Turkish language!
Pre-print: arxiv.org/abs/2506.13487
Fruit of an almost year-long project by amazing MS student @ezgibasar.bsky.social in collab w/ @frap98.bsky.social and @jumelet.bsky.social
19.06.2025 16:28 — 👍 11 🔁 2 💬 1 📌 3

Ik snap niet dat hier niet meer ophef over is:
Het binnenhalen van Amerikaanse wetenschappers wordt betaalt door Nederlandse academici geen inflatiecorrectie op hun salaris te geven.
1/2
13.06.2025 09:00 — 👍 66 🔁 35 💬 5 📌 7
Ohh cool! Nice to see the interactions-as-structure idea I had back in 2021 is still being explored!
12.06.2025 22:37 — 👍 3 🔁 0 💬 0 📌 0
My paper with @tylerachang.bsky.social and @jamichaelov.bsky.social will appear at #ACL2025NLP! The updated preprint is available on arxiv. I look forward to chatting about bilingual models in Vienna!
05.06.2025 14:18 — 👍 8 🔁 2 💬 1 📌 1

University: a good idea | Patrick Porter | The Critic Magazine
A former student of mine has penned an attack on universities, derived from their own disappointing experience studying Politics and International Relations at the place where I ply my trade. In short...
"A well-delivered lecture isn’t primarily a delivery system for information. It is an ignition point for curiosity, all the better for being experienced in an audience."
Marvellous defence of the increasingly maligned university experience by @patporter76.bsky.social
thecritic.co.uk/university-a...
28.05.2025 10:36 — 👍 59 🔁 19 💬 0 📌 2
Stellen OBP - Georg-August-Universität Göttingen
Webseiten der Georg-August-Universität Göttingen
Interested in multilingual tokenization in #NLP? Lisa Beinborn and I are hiring!
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
16.05.2025 08:23 — 👍 25 🔁 13 💬 2 📌 2

BlackboxNLP, the leading workshop on interpretability and analysis of language models, will be co-located with EMNLP 2025 in Suzhou this November! 📆
This edition will feature a new shared task on circuits/causal variable localization in LMs, details here: blackboxnlp.github.io/2025/task
15.05.2025 08:21 — 👍 21 🔁 8 💬 3 📌 4

Close your books, test time!
The evaluation pipelines are out, baselines are released & the challenge is on
There is still time to join and
We are excited to learn from you on pretraining and human-model gaps
*Don't forget to fastEval on checkpoints
github.com/babylm/evalu...
📈🤖🧠
#AI #LLMS
09.05.2025 14:20 — 👍 10 🔁 4 💬 0 📌 0
Scherp geschreven en geheel mee eens, maar beetje wrang wel dat de boodschap zich achter een paywall van 450 euro bevindt :') (dank voor de screenshots!)
23.04.2025 11:40 — 👍 1 🔁 0 💬 1 📌 0

✨ New Paper ✨
[1/] Retrieving passages from many languages can boost retrieval augmented generation (RAG) performance, but how good are LLMs at dealing with multilingual contexts in the prompt?
📄 Check it out: arxiv.org/abs/2504.00597
(w/ @arianna-bis.bsky.social @Raquel_Fernández)
#NLProc
11.04.2025 16:04 — 👍 4 🔁 5 💬 1 📌 1
That is definitely possible indeed, and a potential confounding factor. In RuBLiMP, a Russian benchmark, they defined a way to validate this based on LM probs, but we left that open for future work. The poor performance on low-res langs shows they're definitely not trained on all of UD though!
17.04.2025 19:03 — 👍 1 🔁 0 💬 1 📌 0
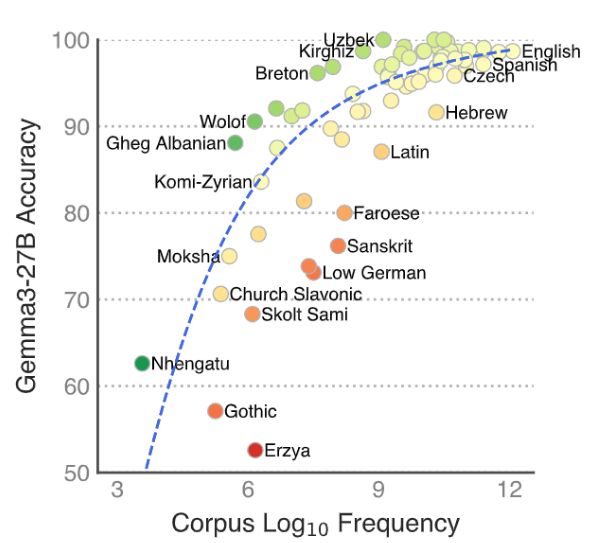
✨New paper ✨
Introducing 🌍MultiBLiMP 1.0: A Massively Multilingual Benchmark of Minimal Pairs for Subject-Verb Agreement, covering 101 languages!
We present over 125,000 minimal pairs and evaluate 17 LLMs, finding that support is still lacking for many languages.
🧵⬇️
07.04.2025 14:55 — 👍 78 🔁 22 💬 3 📌 4
PhD student at IT University of Copenhagen. NLP, linguistic evaluation.
NLP PhD Candidate at Tel Aviv University (Google PhD Fellow) | Working on LLM reasoning and Language Agents | Prev. Research intern at Meta FAIR and AI2
Science of language models @uwnlp.bsky.social and @ai2.bsky.social with @PangWeiKoh and @nlpnoah.bsky.social. https://ianmagnusson.github.io
PhD student at Brown interested in deep learning + cog sci, but more interested in playing guitar.
Baritone, researcher, designer
bascornelissen.nl
PhD Student @HelsinkiNLP / Low-resource, Machine Translation, Knowledge Distillation, Multilinguality
Founder/CEO of Zeta Alpha (@zeta-alpha.bsky.social) / Founder @Textkernel / AI for a Deep Understanding of Work / Machine Learning / NLP / Semantic Search / Signal / Noise
🔎 distributional information and syntactic structure in the 🧠 | 💼 postdoc @ Université de Genève | 🎓 MPI for Psycholinguistics, BCBL, Utrecht University | 🎨 | she/her
Deutsche Gesellschaft für Kognitive Linguistik / German Cognitive Linguistics Association https://www.dgkl-gcla.de/
Next conference: Bielefeld University, 31.08.-02.09.2026 https://t1p.de/dgkl2026
Sustainable Fashion Journalist | Climate Justice | focus on Latin America |
PhD candidate in Computational Linguistics, University of Groningen.
From 🇨🇱 Now in 🚩 Netherlands
Life is too short for bad wine, bad coffee and bad ontologies.
#NLProc PhD Student at EPFL
PhD Candidate @University of Amsterdam. Working on understanding language generation from visual events—particularly from a "creative" POV!
🔗 akskuchi.github.io
professor for natural language processing, head of
BamNLP @bamnlp.de
📍 Duisburg, Stuttgart, Bamberg
#NLProc #emotion #sentiment #factchecking #argumentmining #informationextraction #bionlp
Professor of Language Technology at the University of Helsinki @helsinki.fi
Head of Helsinki-NLP @helsinki-nlp.bsky.social
Member of the Ellis unit Helsinki @ellisfinland.bsky.social
Postdoctoral Scientist at University of Copenhagen. I am currently more focused on developing pixel language models. #nlproc #multilinguality #multimodality
PhD candidate @ University of Amsterdam
evgeniia.tokarch.uk
Computational sentence processing modeling | Computational psycholinguistics | PhD student at LLF, CNRS, Université Paris Cité | Currently visiting COLT, Universitat Pompeu Fabra, Barcelona, Spain
https://ninanusb.github.io/























