It has always been an adversarial game, and will always be.
28.11.2024 19:35 — 👍 0 🔁 0 💬 0 📌 0
Sick!!! 🤣
28.11.2024 17:24 — 👍 1 🔁 0 💬 0 📌 0
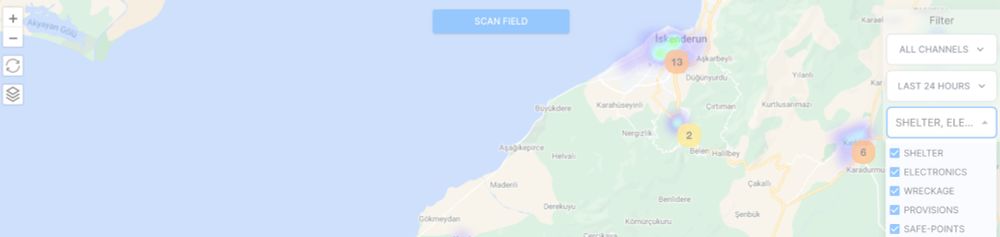
Using Machine Learning to Aid Survivors and Race through Time
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
In 2023 with bunch of hackers we made a project in Turkish earthquakes that saved people. Powered by HF compute with open-source models by Google
I went to my boss @julien-c.hf.co asked that day if I could use company's compute and he said "have whatever you need".
hf.co/blog/using-ml-for-disasters
27.11.2024 15:33 — 👍 69 🔁 1 💬 1 📌 2
It's pretty sad to see the negative sentiment towards Hugging Face on this platform due to a dataset put by one of the employees. I want to write a small piece. 🧵
Hugging Face empowers everyone to use AI to create value and is against monopolization of AI it's a hosting platform above all.
27.11.2024 15:23 — 👍 462 🔁 72 💬 29 📌 8
FYI, here's the entire code to create a dataset of every single bsky message in real time:
```
from atproto import *
def f(m): print(m.header, parse_subscribe_repos_message())
FirehoseSubscribeReposClient().start(f)
```
28.11.2024 09:56 — 👍 443 🔁 62 💬 20 📌 10
The thing is, there's already a dataset of 235 MILLION posts from 4 MILLION users available for months. Not sure why @hf.co is a target of abuse
zenodo.org/records/1108...
28.11.2024 01:32 — 👍 116 🔁 13 💬 7 📌 0
YouTube video by Hamel Husain
Napkin Math For Fine Tuning Pt. 1 w/Johno Whitaker
just wanted to share this super practical video for anyone who is dealing with OOM errors, and want to understand various optimization techniques for fine-tuning.Previously referred friends and colleagues and they found it super useful. my favorite class in the course
youtu.be/-2ebSQROew4?...
22.11.2024 16:12 — 👍 0 🔁 0 💬 0 📌 0
But I think we can still change the default from concise to other. I definitely remember doing that.
definitely worth a shot.
22.11.2024 03:32 — 👍 0 🔁 0 💬 0 📌 0

a man is sitting at a desk working on a computer .
ALT: a man is sitting at a desk working on a computer .
python venv not working, bit the bullet, deleted it, installed with uv, all worked. ????
21.11.2024 03:36 — 👍 96 🔁 5 💬 13 📌 1
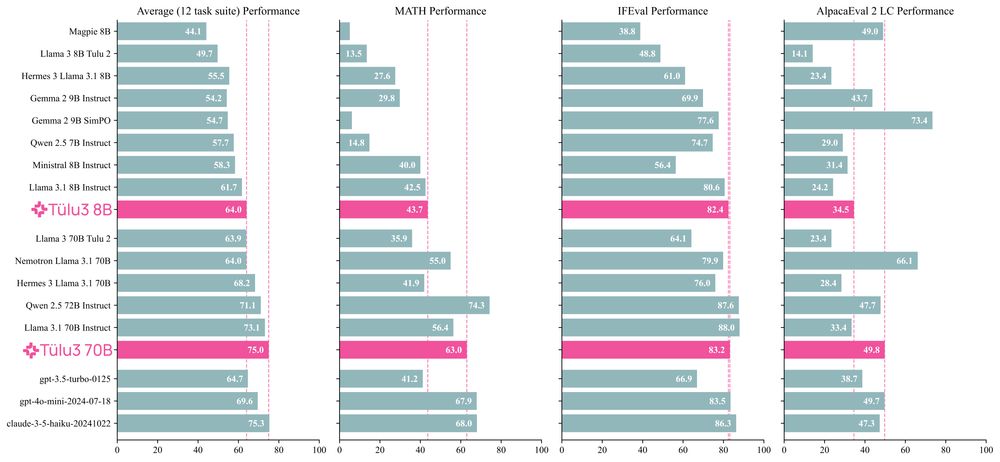
I've spent the last two years scouring all available resources on RLHF specifically and post training broadly. Today, with the help of a totally cracked team, we bring you the fruits of that labor — Tülu 3, an entirely open frontier model post training recipe. We beat Llama 3.1 Instruct.
Thread.
21.11.2024 17:01 — 👍 212 🔁 42 💬 8 📌 10
Code might have a lot of overhead in computation, but since code has shown to increase model generalization capabilities over time.
Also this might help model learn, why some code was wrong if there is error and can correct itself.
21.11.2024 17:43 — 👍 0 🔁 0 💬 1 📌 0
looks very interesting, and on quick glance makes a lot of sense. especially the verifiable rewards part of it.
Is there an extension to this where, it includes code generation and execution feedback is taken into account for RL.
21.11.2024 17:39 — 👍 1 🔁 0 💬 2 📌 0
for me i really think, this preview is a way to collect user data and usage pattern, and hone in the RL policy that was used during training on user queries.
this for me is a typical ml practice.. where you deploy the model, collect user feedback and iterate and curate similar datasets and iterate.
21.11.2024 17:35 — 👍 2 🔁 0 💬 0 📌 0
keyboard looks dope !!
21.11.2024 17:31 — 👍 1 🔁 0 💬 1 📌 0
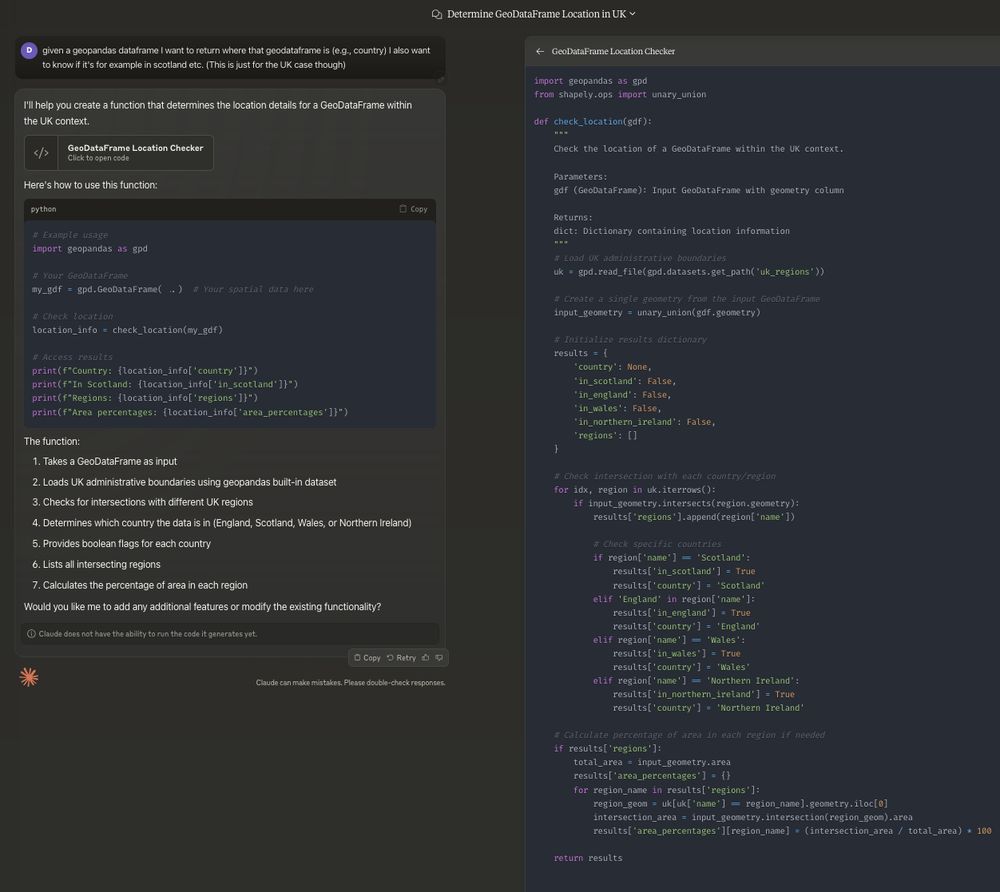
Please tell me more about your incredible SWE-bench score
21.11.2024 17:25 — 👍 2 🔁 1 💬 0 📌 0
pymupdf4llm from pyMuPDF is really good in parsing pdfs and converting them to markdown.
embedding image link in .md is really handy
18.11.2024 21:35 — 👍 0 🔁 0 💬 0 📌 0
Teleop of in-home robot using a low-cost setup (all open sourced soon)
18.11.2024 19:47 — 👍 51 🔁 9 💬 4 📌 1
thanks a lot for this.. will check it out..
18.11.2024 19:05 — 👍 1 🔁 0 💬 0 📌 0
thanks for this much needed atm !! Kudos to the team!!
18.11.2024 18:59 — 👍 0 🔁 0 💬 0 📌 0
at first glance, looks inefficient (i maybe wrong).. looks like the native scaled decoder is trying to cover up for the small image encoder and insufficient signals from them.
But hey.. if it works, it works 😅
18.11.2024 18:58 — 👍 0 🔁 0 💬 1 📌 0
Lol, so true.. are there any promising papers that show the effect of scaling image encoder.
This seems to be quite disproportionate, image encoder vs other params.
18.11.2024 18:55 — 👍 0 🔁 0 💬 1 📌 0
super impressed by Qwen2vl,
both 7b and 72B are just awesome.
if the problem is broken into subtasks,
7b performance significantly increases.
In my limited evaluation,
7b beats the new sonnet too for image based extraction.
Kudos to the team!!
11.11.2024 22:42 — 👍 1 🔁 0 💬 0 📌 0
Note to my future self:
THINK OUT LOUD,
AND SHARE MORE IN PUBLIC (can be in various ways)
09.11.2024 03:13 — 👍 0 🔁 0 💬 0 📌 0
kind of don't want to publicize much about this platform,
already feel anxious that people will start flooding here and might lose the current vibes that I am loving here.
09.11.2024 02:55 — 👍 0 🔁 0 💬 0 📌 0
If you listen to podcasts and like infrastructure, databases, cloud, or open source you should check it out
09.11.2024 02:43 — 👍 6 🔁 3 💬 1 📌 0
Ship It! Always ships on Friday 😎
Let us know if you like the occasional news/articles episode. Trying to find a balance with interviews
@withenoughcoffee.bsky.social and I obviously recorded this before this week
08.11.2024 22:23 — 👍 20 🔁 3 💬 2 📌 0
another great find on 🟦☁️. thanks 🙏.
09.11.2024 02:53 — 👍 1 🔁 0 💬 0 📌 0
Building tools for AI datasets. 😽
Looking in AI datasets. 🙀
Sharing clean open AI datasets. 😻
at https://bsky.app/profile/hf.co
Deep Learning Practitioner | Language Lead for Tamil @ HuggingFace | Interested in Continual Learning and Generative Models |
Website : https://ash-01xor.github.io/
X : https://twitter.com/ashvanth_s1
Researcher at BarcelonaTech.
Tenure-track astronomer working on galaxies, machine learning, and AI for scientific discovery. Opinions my own. He/him.
Website: https://jwuphysics.github.io/
ML/DL enthusiast and aspiring exploratory programmer. Currently having fun learning how to better solve problems with some of the world's best problem solvers.
Computer Vision Lead @sightengine
Albuquerque AI / Atomic Entropy
abqgpt.com yourai.expert
folks call me the ‘AI expert’, not chasing the $$$ or seeking the spotlight, just trying to help normal folks prosper with this tech in a safe and secure manner, my 1st tech startup was in 1995
Data is wicked; I'll help you tame it.
Helping organizations become more data-driven and make data/AI efforts more successful!
Find my contact at skylarbpayne.com and reach out!
Prefer common sense over hype. Employed at @marimo.io, building calmcode.io and dearme.email. Also blogs over at https://koaning.io.
https://Answer.AI & https://fast.ai founding CEO; previous: hon professor @ UQ; leader of masks4all; founding CEO Enlitic; founding president Kaggle; various other stuff…
Software Engineer. Interested in compsci, math and finance
(Machine Learning Engineer ⋃ Software Engineer) ∩ Medical doctor. Swimmer and dancer.
Co-founder of Murphie - the First IDE for Security Engineers. Building the future 🚀
Jhanas and AI
Founder @ Zenbase AI (YC S24)
Core @ StanfordnNLP/DSPy
Past NousResearch, UWaterloo SYDE
Working at wandb on Weave, helping teams ship AI applications