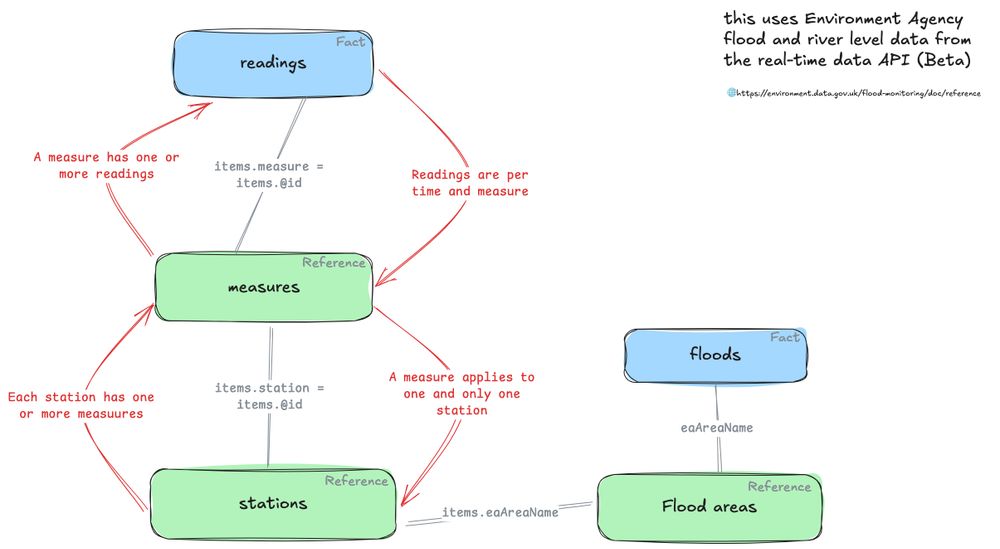
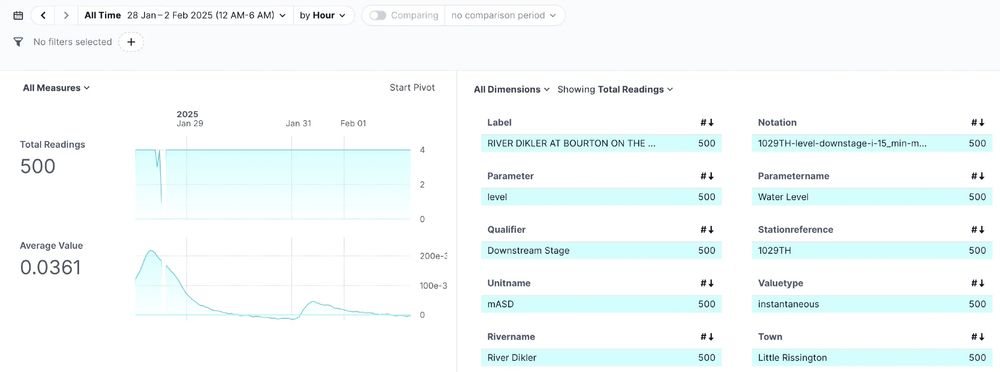
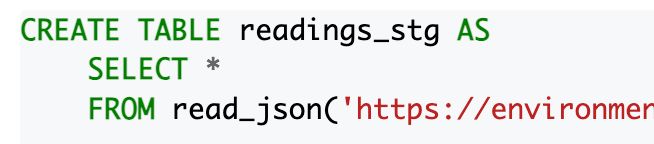
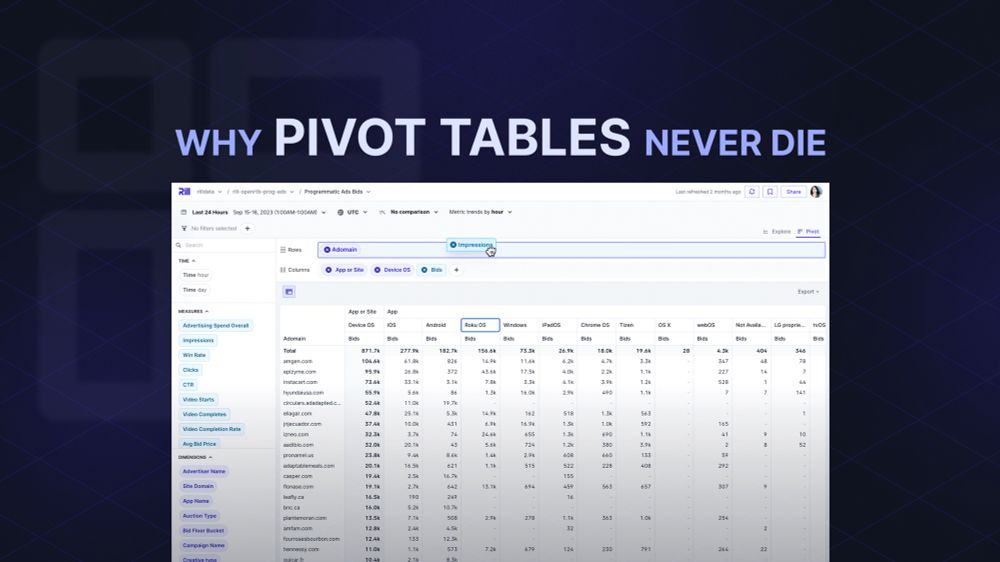
DuckLake is a simpler, SQL-friendlier alternative to Iceberg.
“There are no Avro or JSON files. There is no additional catalog server or additional API to integrate with. It’s all just SQL.“
That said, choose your catalog database — a single-point of failure — *very carefully*.
27.05.2025 21:33 — 👍 9 🔁 1 💬 0 📌 0

BI-as-Code with GenAI+DuckDB Real Use, Not Just Hype · Luma
Mehdi and Michael dive into how GenAI is reshaping BI-as-code.
And as always — it’s not just talk, it’s real code.
Get ready for pragmatic insights and…
Quack... Quack... and code!
@mehdio.com and @medriscoll.com from @rilldata.com are diving into how GenAI is reshaping BI-as-code — from idea to implementation.
This one’s for data folks who want to see beyond the hype.
Register : lu.ma/w4ncmttn
13.05.2025 19:09 — 👍 4 🔁 4 💬 0 📌 0

Real-time Roundtable Live from Data Council | Rill Data
Register now for Real-time Roundtable Live from Data Council.
And it's only fitting that we'll be hosting this event a true lakehouse, the Lake Chalet, the best waterfront restaurant on Lake Merritt, steps from the Data Council main event.
RSVP here while tickets last:
www.rilldata.com/events/data-...
15.04.2025 23:44 — 👍 1 🔁 0 💬 0 📌 0

With $21.8M in funding, Tobiko aims to build a modern data platform | TechCrunch
Tobiko aims to reimagine how teams work with data by offering a dbt-compatible data transformation platform.
Similarly, Toby and his team at Tobiko Data have built an powerful yet elegant transformation platform -- combining SQLMesh and SQL dialect transpilation (SQLGlot) to allow portability of pipelines between databases, warehouses, and lakehouses.
techcrunch.com/2024/06/05/w...
15.04.2025 23:44 — 👍 1 🔁 0 💬 1 📌 0
Why am I so excited to bring this crew together on stage? It's because real-time analytical databases like ClickHouse, Apache Pinot, and MotherDuck / DuckDB are reshaping data stacks the fastest-moving engineering teams on earth -- OpenAI, DoorDash, and
@stackblitz.com.
15.04.2025 23:44 — 👍 1 🔁 0 💬 1 📌 0
This legendary panel of technical founders includes Yury Izrailevsky (co-founder of ClickHouse), Kishore Gopalakrishna (founder of StarTree, creator of Apache Pinot), @jrdntgn.bsky.social (co-founder of MotherDuck), and @captaintobs.bsky.social (founder of Tobiko, creators of SQLMesh and SQLGlot).
15.04.2025 23:44 — 👍 2 🔁 1 💬 1 📌 0

Yo SF Bay Area #databs crew, want to talk lakehouses at a real Lake House? :)
Next week after Data Council, join the founders of @clickhouse.com, @motherduck.com, @startreedata.bsky.social, and @tobikodata.com to talk real-time databases and next-generation ETL.
www.rilldata.com/events/data-...
15.04.2025 23:44 — 👍 9 🔁 3 💬 1 📌 0

DuckCon 6 - A SQL-Based Metrics Layer Powered by DuckDB
INTRODUCING A SQL-BASED METRICS LAYER POWERED BY DUCKDB Mike Driscoll Co-Founder, CEO at Rill Data
At @rilldata.com, we've taken the step of shifting metric layers left from BI tools and pushing them into real-time analytical databases like ClickHouse and DuckDB -- to power insanely fast exploratory dashboards. (I'll be discussing at my Data Council in two weeks).
docs.google.com/presentation...
11.04.2025 21:35 — 👍 6 🔁 1 💬 2 📌 0
Now that SQL-on-data-lake frameworks are maturing (DuckDB SQL on Iceberg, Spark SQL on DeltaLake), and transpiling between SQL dialects is possible (thanks to SQLMesh and @tobikodata.com), it's possible to shift these SQL transformations left, out of the warehouse and onto object storage.
11.04.2025 21:35 — 👍 1 🔁 0 💬 1 📌 0
The advantage was that transformations could be written in SQL. The disadvantage is you pay the Snowflake tax for every compute cycle in their warehouse.
11.04.2025 21:35 — 👍 2 🔁 0 💬 1 📌 0
Transformation logic is another use case.
"Shifting left" is in some ways a reaction to the "ELT" pattern (or anti-pattern, in my opinion) that big data warehouses like Snowflake were pushing -- whereby you extract, load, and only *then* transform data in the warehouse.
11.04.2025 21:35 — 👍 1 🔁 0 💬 2 📌 0
Data validation is a great example: an eCommerce platform might validate that order prices contain no negative numbers after its loaded into the database. "Shifting left" means moving that validation to the ingestion or even the collection step in the pipeline, before it hits the database.
11.04.2025 21:35 — 👍 2 🔁 0 💬 1 📌 0

Data pipelines can be visualized as flowing data left to right, starting with raw sources, ingested and modeled into database tables, and eventually served out through user-facing applications and dashboards.
"Shifting left" means taking logic that lives on the right side and moving it leftward.
11.04.2025 21:35 — 👍 1 🔁 0 💬 1 📌 0

"Shifting left" is the new trend among in data stacks -- but what does it mean and what does it matter?
11.04.2025 21:35 — 👍 4 🔁 1 💬 2 📌 0
Apache Pinot is one of the world’s fastest and most scalable real-time analytical databases, relied on by LinkedIn, Uber, and Stripe. It was awesome diving into the secrets behind its unique architecture with creator and @startreedata.bsky.social founder Kishore Gopalakrishna.
04.04.2025 20:51 — 👍 12 🔁 1 💬 0 📌 0
I wish I could say "yes almost certainly" but if the levels of competence we're witnessing in other areas I'm not placing any bets on DOGE's data security practices.
15.03.2025 00:07 — 👍 1 🔁 0 💬 0 📌 0
So what are DOGE's true priorities?
As Maya Angelou wrote: "When someone shows you who they are, believe them the first time."
14.03.2025 23:47 — 👍 5 🔁 1 💬 0 📌 0
Cloud data centers have climate control, and more compute power than your MacBook Air!
This set up could be done by competent data engineer in less time than it took to run her query.
The DOGE tech wiz acknowledged this and wrote "it hasn't been a priority to get that done."
14.03.2025 23:46 — 👍 4 🔁 1 💬 1 📌 0
They should haved loaded this multi-terabytes contracts data set into a cloud database, or even better -- a database built for real-time analytics like @clickhouse.com, Pinot, or StarRocks (sorry @duckdb.org, this is more than you can handle).
14.03.2025 23:46 — 👍 9 🔁 0 💬 1 📌 0
But it doesn't absolve her, or her team, from ridicule.
The DOGE tech wiz kids shouldn't be toting federal databases around on USB-attached external hard drives in "hot, humid hotel rooms" (her literal words): that's what database servers were invented for.
14.03.2025 23:45 — 👍 7 🔁 1 💬 1 📌 0
What actually overheated was an USB external hard drive, with several terabytes of contract data, that she was reading into her MacBook Air and then filtering to find contracts matching her criteria. (High-speed reads on NVMe drives can heat up to 175 °F before thermal throttling kicks in).
14.03.2025 23:44 — 👍 5 🔁 1 💬 2 📌 0
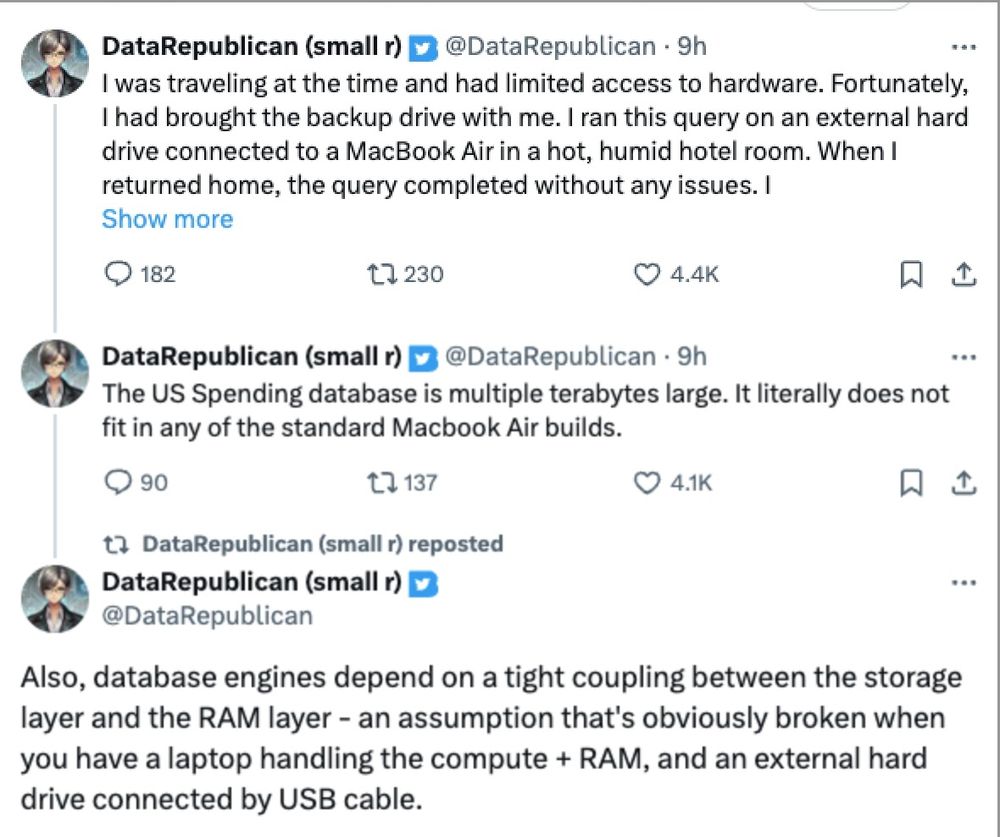
Like others, I jumped on the bandwagon to ridicule the DOGE analyst who "overheated her hard drive" by analyzing just 60k rows of data.
I was wrong.
The truth is even dumber.
🧵
14.03.2025 23:44 — 👍 9 🔁 3 💬 3 📌 1

Rill | Scaling Beyond Postgres: How to Choose a Real-Time Analytical Database
This blog explores how real-time databases address critical analytical requirements. We highlight the differences between cloud data warehouses like Snowflake and BigQuery, legacy OLAP databases like ...
Just published: Ever had to «Scale beyond Postgres»?
You may have started with a simple ETL pipeline and crunched critical business logic into useful dashboards, but speed and scale didn't grow with data at some point, and it's the concurrent user.
✨ Below are some highlights from the article.
11.03.2025 14:23 — 👍 4 🔁 3 💬 1 📌 0
Show HN: Open-source, browser-local data exploration using DuckDB-WASM and PRQL | Hacker News
How mature is DuckDB WASM these days? I recall reading on HN about a similar app last year, called Pretzel, but I think they pivoted:
news.ycombinator.com/item?id=3971...
04.03.2025 15:57 — 👍 3 🔁 0 💬 3 📌 0

This activity is sometimes called semantic data modeling. Actually, the task of capturing the meaning of data is a never-ending one. So the label “semantic” must not be interpreted in any absolute sense. – E.F. Codd, 1979
The father of relational databases understood semantic data models.
03.03.2025 21:56 — 👍 15 🔁 1 💬 1 📌 0
Google couldn’t create a competitive product because they profit directly from that ad spam and indirectly from data selling.
(Same reason Gmail doesn’t really want to clean up your Inbox, even though they could.)
05.02.2025 16:38 — 👍 1 🔁 0 💬 0 📌 0
Senior editor @propublica.org.
Former Washington Post deputy health & science editor and race & economy reporter. Former Boston Globe national political reporter.
https://www.propublica.org/people/tracy-jan
Senior Fellow, NYU Tax Law Center. Tax, economic, and climate policy. But mostly a travel hockey dad.
Principal Architect @posit.co, GP Composed Ventures, Co-founder Voltron Data. Open source: Apache Arrow, pandas, Ibis. "Python for Data Analysis" book
Scottish - American. Built a so-called career on data and analytics. Should have been a musician.
Creator of Flask • sentry.io ♥︎ writing and giving talks • Excited about AI • Husband and father of three • Inhabits Vienna; Liberal Spirit • “more nuanced in person” • More AI content on https://x.com/mitsuhiko
More stuff: https://mitsuhiko.at/
“Failed Blogger”
✉️ Newsletter: CrazyStupidTech.com
🔗 Blog: om.co
📸 Photos: PhotosbyOm.com
💻 Data enthusiast | 🧠 AI & LLM | 🔧 Passionate Engineer & Coder |💡Obsessed with coding, problem-solving, and tech innovation 🚀 | InzataAnalytics co-founder.
I have launched Excel once
Building https://www.twingdata.com and https://www.fastpentests.com
Before this spent 10+ years in adtech engineering at https://triplelift.com.
I hopefully fix more than I break.
Product Manager @rilldata.com
Data analyst and business consultant #ecommerce #cro #rstats #bi #etl
Aiguafreda, Barcelona. Ich lerne Deutsch.
@jrosell@mastodon.social
Rill is an operational BI tool that provides fast dashboards your team will actually use. Try Rill for free: curl https://rill.sh | sh
Co-founder & CEO https://databend.com
opensource + voip/rtc observability + duckdb quackscience
makers of #homer #sipcapture, #hepic, #qryn and #gigapipe
Amsterdam, The Netherlands
#qxip #qryn #quackscience #gigapipe #telecom #observability
Data Engineer - Cooking https://github.com/buremba/universql 🐥