
De Stiil for translated fiction, and the owner, Aude, who is fabulous and has great taste. The word for used books. Drawn and Quarterly for comics 💥 worth the carry-on space!
17.02.2026 01:47 — 👍 1 🔁 0 💬 1 📌 0De Stiil for translated fiction, and the owner, Aude, who is fabulous and has great taste. The word for used books. Drawn and Quarterly for comics 💥 worth the carry-on space!
17.02.2026 01:47 — 👍 1 🔁 0 💬 1 📌 0
Open-source code on github, models and *every* intermediate checkpoint is live on huggingface.
huggingface.co/allenai/Olmo...
huggingface.co/allenai/Olmo...
There's a lot of improvement still to be made. Think your RL submission for ICML is solid? Try it out on Olmo 3 RL-Zero!

A lot of people are still using DAPO's solid benchmark with Qwen 2.5 32B. Olmo 3 RL-Zero is equally effective but much lighter on compute!
12.12.2025 20:42 — 👍 0 🔁 0 💬 1 📌 0
Previously Olmo 3 RL-Zero Math got ~40% on AIME 2024 at 2k steps, current improvements get us above 50% and doesn't plateau til ~3k steps!
12.12.2025 20:42 — 👍 0 🔁 0 💬 1 📌 0
Olmo 3.1: even more RL = even more RL-Zero!
@saurabhshah2.bsky.social and I tweaked some hyperparams and prompts, @hamishivi.bsky.social and @finbarr.bsky.social improved the code and boom!
New Olmo 3.1 RL-Zero 👾 An updated, solid baseline for your RL and reasoning research
Train and repro everything yourself! Everything is open and PRs / issues welcome! github.com/allenai/open...
20.11.2025 20:38 — 👍 0 🔁 0 💬 0 📌 0This was a big effort with peeps at Ai2 who put in a lot of work including putting up with the weird memes I post in slack, #1 manager @natolambert.bsky.social, @finbarr.bsky.social @saurabhshah2.bsky.social @hamishivi.bsky.social Teng Hanna and @vwxyzjn.bsky.social who advised behind the scenes
20.11.2025 20:38 — 👍 0 🔁 0 💬 1 📌 0
Finally, for those studying midtraining and cognitive behaviours, you can ablate different midtraining mixes to see how they affect the ability to learn reasoning in the RL-Zero setup
20.11.2025 20:38 — 👍 0 🔁 0 💬 1 📌 0
It's also a great setup for multi-objective RL! @saurabhshah2.bsky.social
and I created four data domains: math, code, instruction-following, and general chat, so you can study their interaction during RL finetuning

Olmo 3 RL-Zero is also a great setup for studying RL Infra. We use it to ablate active sampling and find it really stabilizes loss!
20.11.2025 20:38 — 👍 1 🔁 0 💬 1 📌 0
But with RLVR on our curated datasets Dolci (huggingface.co/datasets/all...), Olmo 3 base can really improve on reasoning. Look at those AIME curves go!
20.11.2025 20:38 — 👍 0 🔁 0 💬 1 📌 0
Because Olmo 3 is fully open, we decontaminate our evals from our pretraining and midtraining data. @stellali.bsky.social proves this with spurious rewards: RL trained on a random reward signal can't improve on the evals, unlike some previous setups
20.11.2025 20:38 — 👍 1 🔁 1 💬 1 📌 0
Check out Olmo 3 RL-Zero: a clean and scientific setup to benchmark RLVR
Everyone is finetuning with Qwen but its hard to know whether your eval is contaminated and skewing your RLVR results. Olmo 3 has a solution.
I think recent technologies generally trade off big capabilities for stability and robustness. Websites are an easier way to get information compared to phone lines but we expect them to go down once in a while and its ok.
I think people are naturally adapting to LLMs giving them half-truths



We present Olmo 3, our next family of fully open, leading language models.
This family of 7B and 32B models represents:
1. The best 32B base model.
2. The best 7B Western thinking & instruct models.
3. The first 32B (or larger) fully open reasoning model.

Manitokan are images set up where one can bring a gift or receive a gift. 1930s Rocky Boy Reservation, Montana, Montana State University photograph. Colourized with AI
Preprint Alert 🚀
Multi-agent reinforcement learning (MARL) often assumes that agents know when other agents cooperate with them. But for humans, this isn’t always the case. For example, plains indigenous groups used to leave resources for others to use at effigies called Manitokan.
1/8

@dnllvy.bsky.social @oumarkaba.bsky.social presenting cool work at #ICLR2025 on generative models for crystals leveraging symmetry ❄️🪞, repping @mila-quebec.bsky.social
24.04.2025 07:07 — 👍 5 🔁 1 💬 0 📌 0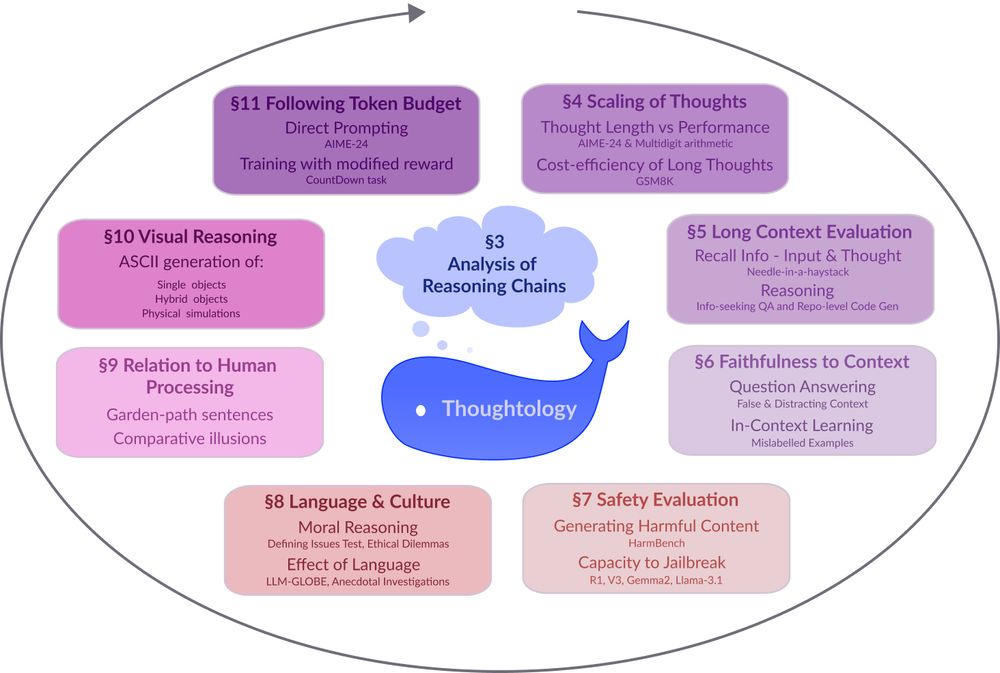
A circular diagram with a blue whale icon at the center. The diagram shows 8 interconnected research areas around LLM reasoning represented as colored rectangular boxes arranged in a circular pattern. The areas include: §3 Analysis of Reasoning Chains (central cloud), §4 Scaling of Thoughts (discussing thought length and performance metrics), §5 Long Context Evaluation (focusing on information recall), §6 Faithfulness to Context (examining question answering accuracy), §7 Safety Evaluation (assessing harmful content generation and jailbreak resistance), §8 Language & Culture (exploring moral reasoning and language effects), §9 Relation to Human Processing (comparing cognitive processes), §10 Visual Reasoning (covering ASCII generation capabilities), and §11 Following Token Budget (investigating direct prompting techniques). Arrows connect the sections in a clockwise flow, suggesting an iterative research methodology.
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/
Hope the Llama team releases more details. Until then check out my paper on async RLHF and feel free to message me to chat about it at ICLR!
bsky.app/profile/mnou...
And to reviewer 2, I guess it does work in large scale distributed training! I am really curious how they did the resource balancing to account for different computational speed
07.04.2025 19:39 — 👍 0 🔁 0 💬 1 📌 0
Llama 4 uses async RLHF and I would just like to announce that I called it t.co/w9qJxr944C
07.04.2025 19:39 — 👍 6 🔁 0 💬 1 📌 0Classic Benno, hanging out with his human friends John, Ṃ̵̢͍̬̘ͧ̉͆ͤ̈͆̂ä́t̢̢̡̫̻̰͈̣͚͆͛͗̈ͭ̉̕͟ͅt̛̹̰̑̓ͭ͗h̸̷̛̛̥̱͉͎̯̻̼͕͉̻̄̅̾ͣ̉̈͌̀ͮ͋ͯ͐ͮͥ̿͛ͪ͜͠͝ẹ̱̞̬̅͂ͯ̈́̆̎ͣw̵̨̧̧̥̩͔͎̬̭͚̩͉ͤ̌͢͝, and Cͧͯ_̸̨̱͙̦͍̉̒͐͐͂͋̎̂ͬ̑͜͝h͐_̮͒͢r̸̛̳̘̠̯ͣͧͦ̏͑ͯ͡i̷̡̡͔̪̟͙͖̫̩̭̳̤͕̞͙̯͚̫̯ͭͤ̌̽͋ͯ̉ͥ́ͭͧͥͦͬ̀ͨ͌̒͢͞s̺̹͛ͭ̐͗ͤͫ́̃ͤ͢͠
18.03.2025 21:57 — 👍 4 🔁 0 💬 0 📌 0
Thanks again to my collaborators:
@vwxyzjn.bsky.social
@sophie-xhonneux.bsky.social
@arianh.bsky.social
Rishabh and Aaron who have not yet migrated 🦋
DMs open📲let's chat about about everything LLM + RL @ ICLR and check out
Paper 📰 arxiv.org/abs/2410.18252
Code 🧑💻 github.com/mnoukhov/asy...
We also have an appendix full of fun details like "How to make RLOO work off-policy" and "Why synchronous RLHF is not feasible in the long term" from an engineering perspective 👷🛠️
Would love critiques from any engineers working on RLHF if they feel I missed something!

We showed great results on RLHF but reviewers wanted reasoning + math 🧠🤔 Thanks my labmates Amirhossein and Milad, we got Rho-1B training on GSM8k!
Online DPO slightly outperforms PPO on GSM8k but more importantly 1-step Async runs 68% faster than Sync and matches performance🔥

Recap⌛️RL training of LLMs is frequently online and *on-policy* but training and generation alternate and idle while waiting for the other to finish.
We run training and generation at the same time, but now we're training on samples from a previous timestep aka *off-policy* RL!
Our work on Asynchronous RLHF was accepted to #ICLR2025 ! (I was so excited to announce it, I forgot to say I was excited)
Used by @ai2.bsky.social for OLMo-2 32B 🔥
New results show ~70% speedups for LLM + RL math and reasoning 🧠
🧵below or hear my DLCT talk online on March 28!
Reminds me of a very similar shift towards open science by machine learning in 1999 (jmlr.org/statement.html). Nowadays we've got really great infrastructure in the form of @openreview.bsky.social! Reach out if you're considering shifting to open science and check out jmlr.org/tmlr/ for inspo :)
12.02.2025 22:47 — 👍 2 🔁 0 💬 0 📌 0
Programming using an AI assistant in order to improve AI assistants is giving me strong sci-fi vibes. Specifically Isaac Asimov, who clearly invented vibe coding in 1956 users.ece.cmu.edu/~gamvrosi/th...
11.02.2025 00:17 — 👍 2 🔁 0 💬 0 📌 0I'm at #NeurIPS2024 this week if anyone wants to talk about RLHF while drinking an overpriced (but excellent) pourover coffee or tea!
11.12.2024 02:19 — 👍 5 🔁 0 💬 1 📌 0