It's time to build AI-era products that were impossible before.
Batch processing recalculates everything, even when 99.9% of your data didn’t change.
Feldera fixes that w/ incremental compute.
Bring your existing SQL and get millisecond freshness instead of hours-long (or days-long) batch jobs.
12.02.2026 16:55 — 👍 0 🔁 0 💬 0 📌 0
We ran it on Feldera:
- 200ms update latency on input changes
- Single machine (16 CPU cores)
- 15GB RAM steady state
How?
Feldera does work proportional to your changes, not your table size. When you update one or many rows, we recompute only answers that changed and nothing else.
05.02.2026 22:51 — 👍 0 🔁 0 💬 1 📌 0

Query plan for a complex, real-world SQL program
This is a query plan for a real customer’s production SQL.
- 61 input tables -> 33 output views
- 217 joins
- 27 aggregations
- 218 projections and filters
Most systems would either do an expensive full recomputation or flat out fail.
05.02.2026 22:51 — 👍 3 🔁 0 💬 1 📌 0

Your pipeline was disrupted.
Feldera’s Health Page tells you why in seconds. No K8s access. No waiting on DevOps.
Details -> www.feldera.com/blog/introdu...
26.01.2026 21:15 — 👍 1 🔁 0 💬 0 📌 0
Introducing Feldera Health 🩺
A lightweight health monitoring solution built directly into Feldera. See the real-time status of your compiler, API server, and runner at a glance.
✅ Available today on try.feldera.com and Enterprise Feldera
📝 Detailed technical blog coming soon
22.01.2026 19:00 — 👍 2 🔁 1 💬 0 📌 0

January Edition 2026
The past many months have been busy for us at Feldera. We continue to ship compounding improvements for our customers when it comes to usability, performance and efficiency.
Incremental Updates - January 2026 edition is here! 🚀
This edition covers:
- Product updates: adaptive join rebalancing, GC for ASOF joins and more
- New blogs: deep dive into our profiler, constant folding in Calcite, and a look back at our progress in 2025
www.linkedin.com/pulse/januar...
15.01.2026 17:50 — 👍 2 🔁 1 💬 0 📌 0
🩻 X-ray vision for your SQL pipeline in Feldera.
-Click any node -> see metrics across all cores.
-Heat map shows bottlenecks instantly.
-Expand to trace back to your SQL code.
⚡ Seconds to see what used to take hours to find.
Dive deeper: www.feldera.com/blog/introdu...
23.12.2025 21:38 — 👍 2 🔁 1 💬 0 📌 0

Feldera in 2025: Building the Future of Incremental Compute
Feldera's 2025 year in review: comprehensive SQL support, state-of-the-art infrastructure, advanced connectors, and the future of real-time analytics.
2025:
📦 166 unique releases, 1,162 changes, avg. new release every 2.4 days
📊 10x cost reduction for users, hours old insights into sub-second latency
⚡ 70-node Spark clusters -> single digit Feldera instances
2026: Make incremental compute inevitable
Full story: www.feldera.com/blog/feldera...
19.12.2025 18:59 — 👍 5 🔁 2 💬 1 📌 0
📊 Real-time metrics per operator: execution time, memory, data volumes, disk I/O
🎨 Visual dataflow graphs with color-coded performance heatmaps
🔍 Interactive exploration - click any operator to see detailed breakdowns
11.12.2025 17:44 — 👍 0 🔁 0 💬 1 📌 0
That’s why we built the Feldera profiler. It shows exactly where your computation time and resources are going.
11.12.2025 17:44 — 👍 0 🔁 0 💬 1 📌 0
You can’t optimize what you can’t profile.
Which operators are a bottleneck? Are there skewed joins? Why is storage use spiking?
Our engineering team used to spend hours trying to answer these questions when performance problems would show up in the wild.
11.12.2025 17:44 — 👍 1 🔁 1 💬 1 📌 0
They’re all available today. Now go build something fast. 🏎️
03.12.2025 18:54 — 👍 2 🔁 1 💬 0 📌 0
Modifying a Pipeline While Preserving its State | Feldera Documentation
This feature is only available in Feldera Enterprise Edition.
Backfill avoidance: modifying a query used to mean having to recompute & backfill all over again. With backfill avoidance, you can avoid another backfill by reusing existing states when applicable, & recomputing only what’s new. Much faster than starting over.
docs.feldera.com/pipelines/mo...
03.12.2025 18:54 — 👍 0 🔁 0 💬 1 📌 0
Efficient Bulk Data Processing using Transactions | Feldera Documentation
Transaction support is an experimental feature and may undergo significant
Fast backfill (HUGE steps): you know backfilling historical data can take forever. That's why we shipped a transaction API where you control the batch size - whether small or HUGE - for efficient bulk ingests.
docs.feldera.com/pipelines/tr...
03.12.2025 18:54 — 👍 0 🔁 0 💬 1 📌 0
Parallel Compilation | Feldera Documentation
Parallel compilation allows Feldera to compile multiple pipelines concurrently by distributing the workload across several compiler server pods. This dramatically reduces total compile time for large ...
Parallel compilation: we used to compile pipelines one at a time. Now we distribute the workload across multiple servers. Pipeline builds that were queued back-to-back can now complete simultaneously within minutes. It shaved an hour off of our CI pipeline!
docs.feldera.com/get-started/...
03.12.2025 18:54 — 👍 0 🔁 0 💬 1 📌 0
Rust Compilation can be slow. Backfills can take days. And no one likes to wait. ⏳
We’ve recently shipped features that will get you deploying faster and scaling more efficiently:
- Parallel Compilation
- Fast Backfill
- Backfill Avoidance
03.12.2025 18:54 — 👍 3 🔁 1 💬 1 📌 0
Jobs
If you’re excited about hard technical problems and want to shape the future of real-time systems, Feldera is hiring (remotely!) for a Solutions Engineer (Enterprise) and a Software Engineer (Reliability, Performance)
jobs.ashbyhq.com/feldera/544a...
06.09.2025 00:57 — 👍 4 🔁 0 💬 0 📌 1

Hi Ben,
I wanted to follow up on my recent note about your containerized solutions. If Feldera is exploring ways to improve mobility or streamline deployment, our container wheels could be a great fit.
Here’s what our solutions offer:
Increased flexibility
Reduced operating costs
Safe and practical mobility
A more sustainable option
With logistics hubs in both the US and EU, our casters are already helping teams in container rental, storage, and logistics cut down on equipment costs, labor, and time.
Some of my work at @feldera.bsky.social involves containers. I keep getting spam from some vendor who wants to sell me casters to put on the containers 🤣
02.09.2025 15:22 — 👍 1 🔁 1 💬 0 📌 0

How Feldera Customers Slash Cloud Spend (10x and beyond)
By only needing compute resources proportional to the size of the change, instead of the size of the whole dataset, businesses can dramatically slash compute spend for their analytics.
"This is the true power of incremental compute. By only needing compute resources proportional to the size of the change, instead of the size of the whole dataset, businesses can dramatically slash compute spend for their analytics."
👇
www.feldera.com/blog/how-fel...
20.08.2025 17:01 — 👍 6 🔁 2 💬 0 📌 0
At @feldera.bsky.social I've been doing a lot of performance work. I needed an easy way to watch the Prometheus metrics for a pipeline, so I wrote a simple tool for the Feldera CLI that shows the pipeline metrics. Here's the progress of a pipeline that runs in about 30 seconds.
20.08.2025 00:27 — 👍 6 🔁 3 💬 2 📌 0

Stream Integration
In this blog post we informally introduce one core streaming operation: integration. We show that integration is a simple, useful, and fundamental stream processing primitive, which is used not only…
If you've written even the most basic compute program, you've likely already written programs that "integrate".
Integration is central to Feldera and its underlying theory of incremental compute. It is also all around us in the real world! 👇
18.08.2025 15:14 — 👍 5 🔁 1 💬 0 📌 1
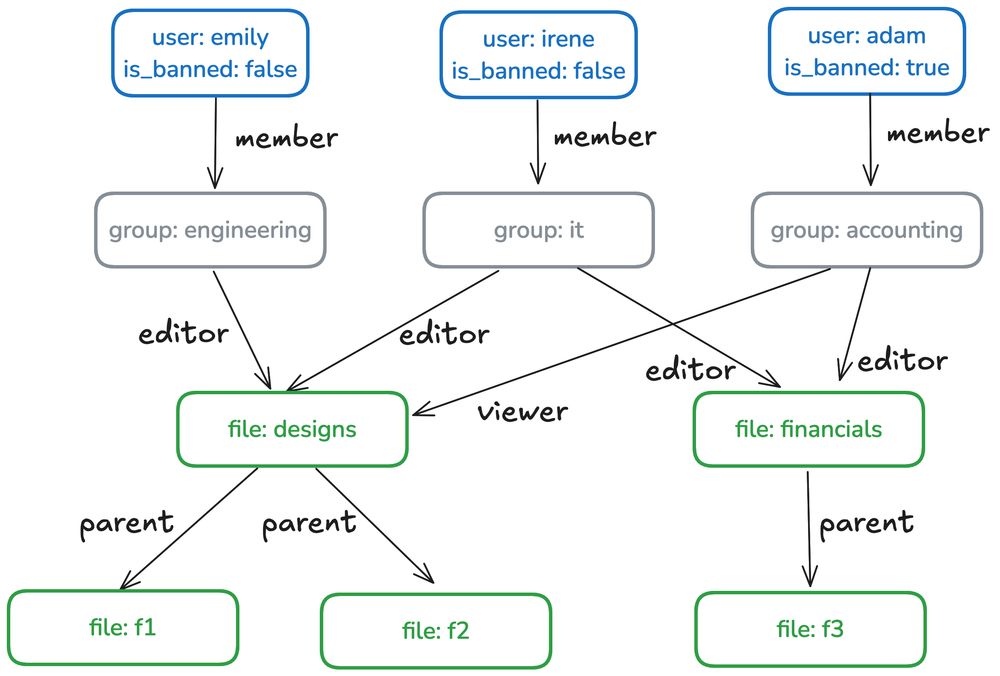
The future of data security isn't about choosing between compliance and performance. It's about making security a performance feature.
Learn how to implement fine-grained authorization without performance penalties: docs.feldera.com/use_cases/fi...
05.08.2025 14:30 — 👍 2 🔁 0 💬 0 📌 0
What if you could have both security AND speed?
Modern fine-grained authorization embeds security directly into data processing, delivering:
- Microsecond authorization decisions
- Real-time row/column-level filtering
- Automated compliance reporting
- Actually improved query performance
05.08.2025 14:30 — 👍 0 🔁 0 💬 1 📌 0
What are some the the typical challenges?
- 300-500ms latency added per query
- Complex compliance audits taking weeks
- Manual permission tracking via spreadsheets
- Performance degradation with granular controls
05.08.2025 14:30 — 👍 0 🔁 0 💬 1 📌 0
Traditional authorization systems force an impossible trade-off: secure data access OR fast query performance. With SOX compliance audits intensifying and data breach costs averaging $4.45M, this choice is becoming a business risk.
05.08.2025 14:30 — 👍 0 🔁 0 💬 1 📌 0
"We chose performance over security" - a dilemma no data team should face.
#DataEngineering #DataSecurity #RealTimeAnalytics
05.08.2025 14:30 — 👍 3 🔁 1 💬 1 📌 0
YouTube video by Feldera, Inc.
How to Incrementally Get Results from Your Graph Data with Feldera
New tech talk:
How to Incrementally Get Results from Your Graph Data with Feldera.
Interested in practical techniques for incremental computation or want to see how this fits into modern data engineering workflows?
Check it out: youtu.be/vpVAZbaZ2Hg
18.06.2025 19:47 — 👍 2 🔁 1 💬 0 📌 0
Mihai Budiu, our exceptional Chief Scientist, won the 2025 #ACM #SIGCOMM Networking Systems Award for his groundbreaking work on #P4.
Details: www.sigcomm.org/awards/sigco...
17.06.2025 17:22 — 👍 1 🔁 0 💬 0 📌 0
Sharing 15+ years of software development experience on http://digitalbuff.dev.
Self-employed developer specialized in building data platforms and applications for clients.
Writing a book on Kafka Streams, follow me for updates!
Product Manager AWS. Golang. Distributed Systems.
Views and opinions are my own.
Black.
#opensource governance: @kubernetes.io, @openssf.org, TODO Group
Office of the CTO, Bloomberg — Opinions are my own
Bio and links: https://whois.auggie.dev/
#Blacksky
Formerly @stephenaugustus (Twitter), @justaugustus@hachyderm.io (Mastodon)
Distributed and Storage Systems. Apache Cassandra Committer and PMC member. Author of Database Internals. Mountain person. http://databass.dev/
Sr. Engineering Manager @ Apple. Distributed Systems and Data. Previously @ 1Password.
Homelabs, databases, and basketball.
✍🏾 @architecturenotes.co
Senior Principal Software Engineer at Red Hat AI | Open Source Leader at KServe, Argo, Kubeflow, Kubernetes, CNCF | Maintainer of XGBoost, TensorFlow | Keynote Speaker | Author | Technical Advisor
More info: http://terrytangyuan.xyz
We are hiring!
🌉 bridged from ⁂ https://hachyderm.io/@justinsheehy, follow @ap.brid.gy to interact
Partner at Redpoint focused on AI, infra, security, and developer tools ⚡️
LabHacker platform engineer and musician;
I'm drawn to hard problems, abstractions, and music;
I build code, hardware, and systems meanwhile overthinking with pen and paper until they’re simple. ps: I have more notebooks than is socially defensible.
AWS Serverless Hero & Principal Engineer @ PostNL
working on compute infra at LinkedIn.
ex-twitter/googlecloud/azure
dist sys enthusiast
github.com/ahmetb
Distributed Systems & databases person. Works at Microsoft on Orleans & Aspire
AWS EKS Specialist SA | @cncf.io Ambassador | CNCF Kubernetes Book Club organizer, GitOps, Argo SIG-scalability lead, Kubernetes, CNOE, Platform Engineering, Fleet Management, GenAI, AI, NVIDIA Jetson
A programming language empowering everyone to build reliable and efficient software.
Website: https://rust-lang.org/
Blog: https://blog.rust-lang.org/
Mastodon: https://social.rust-lang.org/@rust
Rust, Kubernetes, Elixir, Git, jj-vcs, Wheel of Time books, The Expanse books & show, board and video games
AI is a huge net negative and deserves as much scrutiny and skepticism as we can possibly muster
PhD student at @BerkeleySky + https://hydro.run, designing languages for modular and performant distributed systems. Co-organizer https://sfsystemsclub.com
More at https://shadaj.me!
Economics prof at the U. of Michigan. Editor, Journal of Financial Economics. Corporate finance, structural estimation. One-handed pull-ups, cooking, languages, stop harassing me about the mask. https://lsa.umich.edu/econ/people/faculty/toni-whited.html
@postgresql Expert & Freelance. Opinions are mine. Baremetal native
@anayrat@framapiaf.org
Straightforward PostgreSQL and SQL tips, tricks, and tools to get stuff done (no fluff).
SQL Renaissance Ambassador. Author, Trainer, Coach. PhD in Common Sense. Creator of http://use-the-index-luke.com and http://modern-sql.com.



























