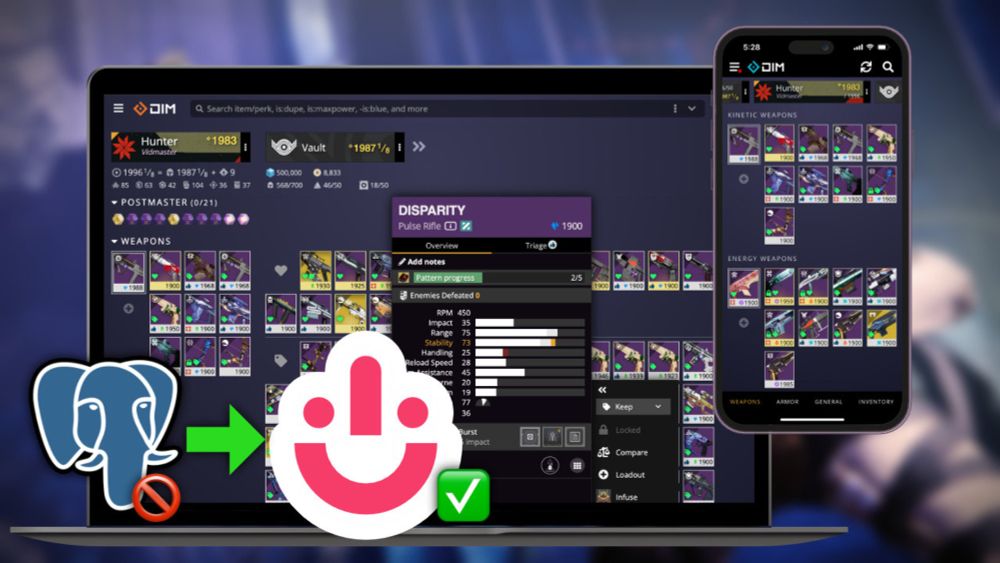
What do you think? Using a SQL database with those magic design patterns (no foreign keys, no joins, JSON documents). This slide is from Canva at #AWSreInvent keynote
🤔 Why not using a document database then?
05.12.2024 17:50 — 👍 4 🔁 1 💬 2 📌 0
Reducing DynamoDB read costs by 60% using Sync
As a NoSQL database, StatelyDB exposes all the classic CRUD APIs you’re used to - Put, Get, Delete, and List. But there’s one other core API that we think is a game changer - SyncList. To explain why ...
What's the best way to reduce cloud costs? Stop doing unnecessary work! I cut read costs for my application by 60% by syncing data instead of reloading it all. This is such a common and effective pattern that it was one of the first things we built into StatelyDB.
stately.cloud/blog/reducin...
21.04.2025 17:09 — 👍 0 🔁 1 💬 0 📌 0
No, for example if you have a temp volume mounted for some shared (ephemeral) state between pods, it thinks the pod isn't safe to remove ever. You have to add the 'cluster-autoscaler.kubernetes.io/safe-to-evict: "true"' annotation.
24.02.2025 19:50 — 👍 0 🔁 0 💬 0 📌 0
Oh, totally, but that's why it's autoscaling. Having someone turn a knob manually is a bad idea.
17.02.2025 22:32 — 👍 0 🔁 0 💬 0 📌 0

A screenshot of the paper "Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service"
https://www.usenix.org/conference/atc22/presentation/elhemali
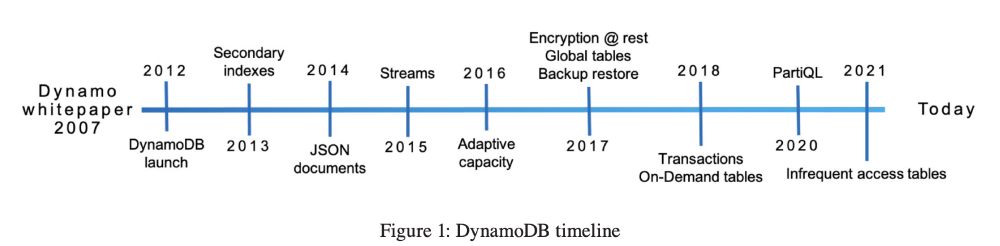
Figure 1 from the paper: DynamoDB timeline.
A good read on how DynamoDB has evolved over the past decade. DynamoDB was originally launched in 2012, and this retrospective paper was published in 2022. www.usenix.org/conference/a...
Some takeaways after reading it 🧵
09.02.2025 19:33 — 👍 37 🔁 9 💬 1 📌 0
That graph is after the 50% cost cut. Before it wasn’t even a contest.
Even in your example autoscaling helps - it will scale up during events and down when they’re not running. The only downside is you can’t scale all the way to zero, but you can scale to 1.
10.02.2025 16:45 — 👍 0 🔁 0 💬 1 📌 0
Don't forget to document all the reasons it *won't* evict pods even when you want it to...
09.02.2025 00:29 — 👍 2 🔁 0 💬 1 📌 0
Easy pagination is lowkey one of the best things about DynamoDB
06.02.2025 18:59 — 👍 1 🔁 0 💬 1 📌 0
Data modeling in DynamoDB is awkward.
DynamoDB provides an incredible set of no-frills features for building apps and services. It has consistent performance at any scale. Very low operational pain. Simple cost model. Missing from that li...
DynamoDB is great for consistent performance, but getting started on it (or changing anything afterwards) can be difficult. What if it was easier to model your data in a way that sets you up for success and lets you sleep through the night?
stately.cloud/blog/data-mo...
06.02.2025 18:56 — 👍 0 🔁 0 💬 0 📌 0
And that's just writes - for reads provisioned capacity is still 50% the cost of on-demand.
06.02.2025 18:27 — 👍 0 🔁 0 💬 1 📌 0
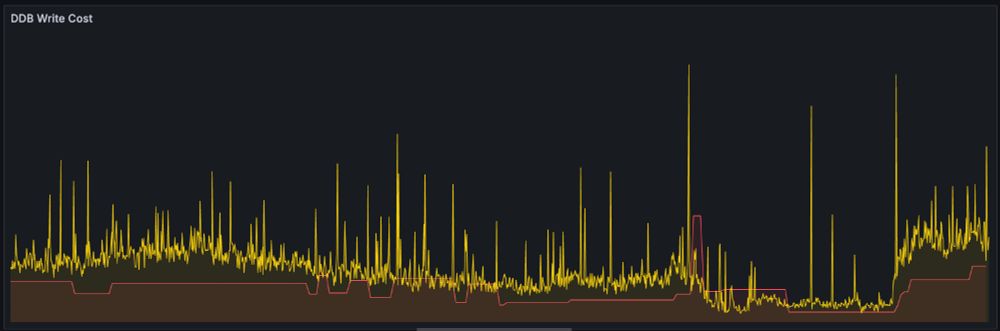
That's fair, but provisioned capacity autoscaling is similarly set it and forget it.
What I'm amazed at is that even relatively "spiky" loads are cheaper with autoscaled provisioned capacity. In this graph yellow is the on-demand dollar cost, while the red is provisioned capacity cost.
06.02.2025 18:26 — 👍 0 🔁 0 💬 1 📌 0
DIM's been doing great since switching from Postgres to StatelyDB - costs are down and it's rock solid. I have a followup post coming soon that takes the wins even further.
04.02.2025 18:03 — 👍 1 🔁 0 💬 0 📌 0
I use a slightly different version saved as `~/bin/git-delete-merged-branches` so I can run it with "git delete-merged-branches":
#!/bin/sh
git branch --merged | grep -v "\*" | grep -v "^\s*\(master\|main\)$" | xargs -n 1 git branch -d
The `git branch --merged` is the most important bit.
04.02.2025 17:59 — 👍 1 🔁 0 💬 1 📌 0
They mention it briefly but a big gotcha is that the default hop limit for IMDSv2 is 1, but containers running in Kubernetes need it to be 2. So you must use a custom launch template in EKS to be able to use it at all.
26.01.2025 21:32 — 👍 2 🔁 0 💬 0 📌 0
I’m interested in your analysis here. Even with the recent price drop, we’ve found that any system that’s getting real traffic is probably still better off (read: gonna pay less) using autoscaling provisioned capacity.
26.01.2025 21:29 — 👍 0 🔁 0 💬 1 📌 0
Realistically I’d probably start with using tenant ID as a PK prefix rather than by itself - tenant is unlikely to be granular enough to be partitioned well.
26.01.2025 21:28 — 👍 1 🔁 0 💬 1 📌 0
I see what you meant initially, then. I was thinking about it more like how I gather requirements - as a subject matter expert, but using it as a tool to organize my thinking and then communicate what I’m doing to customers.
26.01.2025 18:14 — 👍 1 🔁 0 💬 1 📌 0
That AI generated nonsense diagram does not make me confident about trusting any of the information behind that link….
26.01.2025 18:05 — 👍 0 🔁 0 💬 0 📌 0
Obsessed probably isn’t good, but figuring out the actual requirements for a solution is - often moreso than the actual form of the solution. It’s also a great way to communicate, by asking “did I forget anything important this has to do?” Agreed that this shouldn’t take a lot of time and effort.
26.01.2025 17:58 — 👍 0 🔁 0 💬 1 📌 0
Glad it’s working out for you!
24.01.2025 16:47 — 👍 1 🔁 0 💬 0 📌 0
Yeah, it's basically just removing some of the constraints on the final transactional write.
21.01.2025 19:18 — 👍 1 🔁 0 💬 0 📌 0
We started with serializable (and optimistic concurrency control) - we figure it's the "most correct" and we can always expose looser levels later if there's a need.
21.01.2025 18:39 — 👍 1 🔁 0 💬 1 📌 0
We'd love to have your feedback! And I'm definitely interested in what you're storing that hits a 10GB limit. Partitioning by user is definitely the first recommendation we tend to make.
17.01.2025 19:19 — 👍 2 🔁 0 💬 0 📌 0
Part of the problem is that the web frameworks and databases folks are using when they're just getting started don't have any built-in guidance away from things like this. So if you don't know, what's to stop you from copy-pasting the wrong example from the Postgres docs or StackOverflow?
17.01.2025 19:15 — 👍 0 🔁 0 💬 1 📌 0
Independent AI researcher, creator of datasette.io and llm.datasette.io, building open source tools for data journalism, writing about a lot of stuff at https://simonwillison.net/
distributed systems, storage, compute, and databases.
Redux maintainer, building time-travel devtools at Replay.io. I blog about React, Redux, and TS at https://blog.isquaredsoftware.com . Answering questions anywhere there's a textbox on the internet, and otherwise out on the golf course!
Cloudflare is the world’s leading connectivity cloud, and we have our eyes set on an ambitious goal — to help build a better Internet.
Servers as they should be. https://oxide.computer/bio
I want you to win and be happy. Code, OSS, STEM, Beyoncé, T1D, open source artificial pancreases, Portland, 3D printing, sponsorship http://hanselminutes.com inclusive tech podcast! VP of Developer Community @ Microsoft 🌮
http://hanselman.com/about
CEO of System Initiative, Co-Founder of Chef. Open source. Heavy metal and music. Comics. @adamhjk on Twitter, @adamhjk@hachyderm.io on Masotodon.
ScyllaDB is the database for data-intensive applications that require predictable performance at scale (like @Bsky.app)!
Context Designer. Skill acquisition geek. Helping humans and horses do hard things.
(Created the Head First book series)
gp at spark capital ✨ databases, infra, dev tools
Serverless, databases, and serverless databases at AWS. Views my own.
Check out my blog: https://brooker.co.za/blog/
#golang performance, runtime, concurrency. Talks, blogposts and open source projects for #gophers (mail: hello@go-perf.dev). Not affiliated with Go team.
https://go-perf.dev/
Field CTO @ Antithesis
https://akshayshah.org
Kafka and gRPC for the modern age. | buf.build | connectrpc.com
Director of Research at CloudZero, AWS Serverless Hero, and founder @getampt.com. I build, blog, speak, and publish OffByNone.io.
ex pro windsurfer 🇲🇹 🌊 AI engineer. I work on streamlining access to large data sources, agents and retrieval - other interests in mech interp and data efficient fine-tuning.
Yelling into the camera for @AWSCloud Welcome to some cloud and retro tech tweets. ☁ 💾 Opinions and ... skeets(?)... are my own! (he/him)
https://rup12.net
:wq!
Engineering @ AWS. Views are my own.
WarpStream, the Kafka-compatible data streaming platform, is now a part of @confluent.io. We’re joining forces to advance next-gen BYOC data streaming. Learn more at warpstream.com.