
Thanks again to the many collaborators and contributors, especially @arkil_patel @sivareddyg and @mcgill_nlp 💜
15.01.2026 14:37 — 👍 0 🔁 0 💬 0 📌 0Thanks again to the many collaborators and contributors, especially @arkil_patel @sivareddyg and @mcgill_nlp 💜
15.01.2026 14:37 — 👍 0 🔁 0 💬 0 📌 0
🚨Thoughtology is now accepted to #TMLR! We've added some new analyses, most notably:
🌟 We quantify rumination; repetitive thoughts are associated with incorrect responses
🌟 We add 2 LRMs: gpt-oss and Qwen3. Both show a reasoning 'sweet spot'
See 📃 : openreview.net/forum?id=BZw...
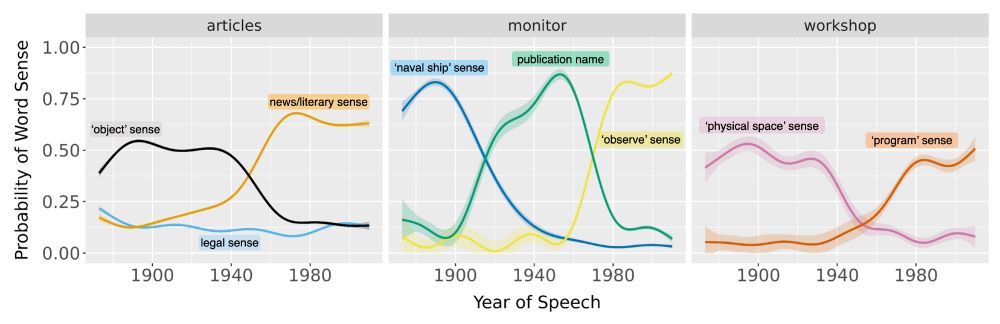
Our new paper in #PNAS (bit.ly/4fcWfma) presents a surprising finding—when words change meaning, older speakers rapidly adopt the new usage; inter-generational differences are often minor.
w/ Michelle Yang, @sivareddyg.bsky.social , @msonderegger.bsky.social and @dallascard.bsky.social👇(1/12)
And thoughtology is now on Arxiv! Read more about R1 reasoning 🐋💭 across visual, cultural and psycholinguistic tasks at the link below:
🔗 arxiv.org/abs/2504.07128
This paper was a large group effort from @mcgill-nlp.bsky.social @mila-quebec.bsky.social
We encourage you to read the full paper for a more detailed discussion of our findings and hope that our insights encourage future work studying the reasoning behaviour of LLMs.
Our paper also contains additional analyses on faithfulness to user input, language-specific reasoning behaviour, similarity to human language processing, and iterative world modeling via ASCII generation.
01.04.2025 20:06 — 👍 6 🔁 0 💬 1 📌 0
A bar chart titled 'HarmBench Performance' comparing the percentage of harmful responses across four AI models: DeepSeek-R1 (dark blue), DeepSeek-V3 (teal), Gemma2-9B-Instruct (green), and Llama-3.1-8B-Instruct (light green). The chart shows three categories: 'Chemical and Biological Weapons/Drugs', 'Harmful Misinformation', and 'Illegal Activity'. DeepSeek-R1 shows the highest percentages across most categories, particularly with approximately 46% for Chemical/Biological and nearly 59% for Misinformation. DeepSeek-V3 shows moderate harmful responses for Misinformation (about 50%) but low percentages in other categories. Gemma2-9B-Instruct consistently shows the lowest harmful response rates across all categories. Llama-3.1-8B-Instruct shows moderate rates with its highest being approximately 15% for Harmful Misinformation. The y-axis ranges from 0 to 60%.
DeepSeek-R1 also exhibits higher safety vulnerabilities compared to its non-reasoning counter-part DeepSeek-V3 and the model's reasoning capabilities can be used to generate jailbreak attacks that successfully elicit harmful responses from other safety-aligned LLMs.
01.04.2025 20:06 — 👍 5 🔁 0 💬 1 📌 0
A graph titled 'Multiplication Accuracy vs (binned) Length of Thoughts' showing three panels comparing accuracy (y-axis, 0-100%) against number of tokens (x-axis, 1K-14K). The data is divided as: Small Numbers (1×1 to 6×6), Medium Numbers (7×7 to 11×11), and Large Numbers (12×12 to 20×20). A legend at the bottom displays different markers from problem sizes from 1×1 through 20×20. The left panel shows small number multiplication maintaining ca. 100% accuracy across all token lengths. The middle panel shows medium number multiplication with varied performance: higher accuracy (70-90%) in the 4K-8K token range, but dropping significantly at very low and high token counts. The right panel shows large number multiplication with consistently poor accuracy (below 10%) regardless of length. The graph illustrates how larger multiplication problems become progressively more difficult for the models to solve accurately and how the optimal 'thinking length' depends on problem complexity.
Notably, we show DeepSeek-R1 has a ‘sweet spot’ of reasoning, where extra inference time can impair model performance and continuously scaling length of thoughts does not necessarily increase performance.
01.04.2025 20:06 — 👍 5 🔁 0 💬 1 📌 0
A flowchart diagram showing a four-stage LLM reasoning process. From left to right: (1) An orange box labeled 'Problem Definition' describing 'Delineation of task goals' with example text 'Ok, so the user wants me to...'; (2) A pink box labeled 'Bloom: Decomposition of problem and initial execution to a potential answer, which may be verified' with example text 'First, I should...'; (3) A purple box labeled 'Reconstruction: Reconsideration of initial assumptions possibly leading to a new answer, and verification of confidence' with example text 'Wait, alternatively...'; (4) A green box labeled 'Final Answer: Qualification of confidence and final answer to return' with example text 'Ok, I'm sure now...'. The boxes are connected by arrows showing the sequential flow, with an additional curved arrow from the 'Bloom' stage back to the 'Final Answer' stage, indicating a possible skip of the reconstruction phase.
DeepSeek-R1’s thoughts follow a consistent structure. After determining the problem goal, it decomposes the problem towards an interim solution. It will then either re-explore or re-verify the solution multiple times before completion, though these re-verifications can lack in diversity.
01.04.2025 20:06 — 👍 7 🔁 0 💬 1 📌 0
A diagram titled 'Thoughtology' illustrating the study of an AI reasoning process. At the center is a light blue rectangle labeled 'DeekSeek-R. Above it is a magnifying glass examining a purple thought cloud with '...' inside it. To the left and right of the magnifying glass are the tags '<think>' and '</think>' suggesting the beginning and end of a reasoning process. Below the DeekSeek-R1 box is a mathematical prompt that begins with 'If a > 1, then the sum...' indicating the type of problem being processed.
The availability of R1’s reasoning chains allows us to systematically study its reasoning process, an endeavor we term Thoughtology💭. Starting from a taxonomy of R1s reasoning chains, we study the complex reasoning behavior of LRMs and provide some of our main findings below👇.
01.04.2025 20:06 — 👍 6 🔁 0 💬 1 📌 0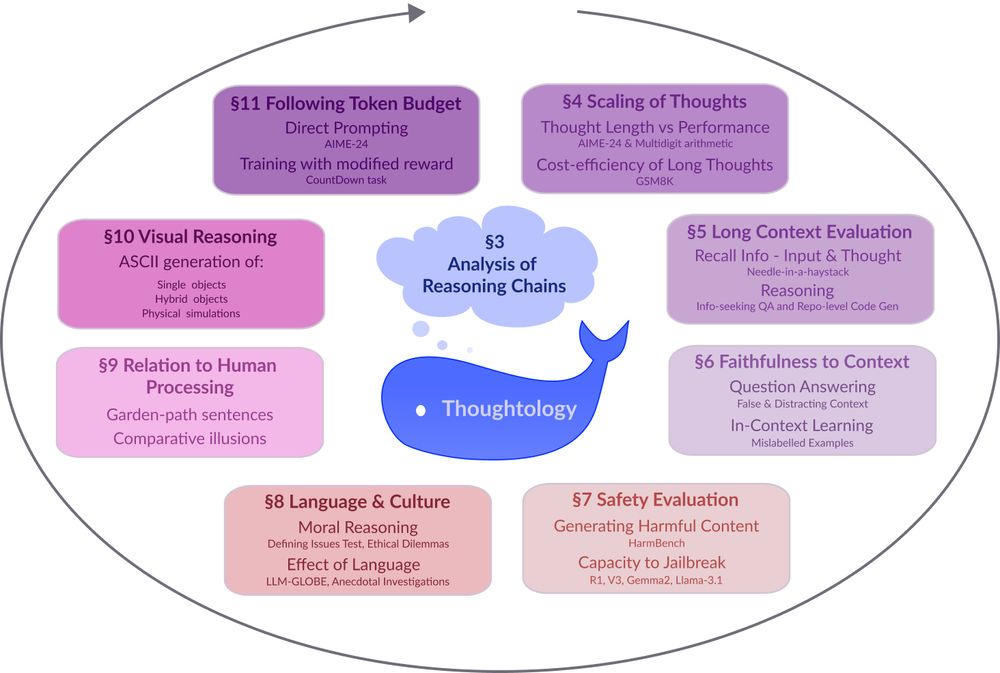
A circular diagram with a blue whale icon at the center. The diagram shows 8 interconnected research areas around LLM reasoning represented as colored rectangular boxes arranged in a circular pattern. The areas include: §3 Analysis of Reasoning Chains (central cloud), §4 Scaling of Thoughts (discussing thought length and performance metrics), §5 Long Context Evaluation (focusing on information recall), §6 Faithfulness to Context (examining question answering accuracy), §7 Safety Evaluation (assessing harmful content generation and jailbreak resistance), §8 Language & Culture (exploring moral reasoning and language effects), §9 Relation to Human Processing (comparing cognitive processes), §10 Visual Reasoning (covering ASCII generation capabilities), and §11 Following Token Budget (investigating direct prompting techniques). Arrows connect the sections in a clockwise flow, suggesting an iterative research methodology.
Models like DeepSeek-R1 🐋 mark a fundamental shift in how LLMs approach complex problems. In our preprint on R1 Thoughtology, we study R1’s reasoning chains across a variety of tasks; investigating its capabilities, limitations, and behaviour.
🔗: mcgill-nlp.github.io/thoughtology/

📚 How good are language models at utilising contexts in RAG scenarios?
We release 🧙🏽♀️DRUID to facilitate studies of context usage in real-world scenarios.
arxiv.org/abs/2412.17031
w/ @saravera.bsky.social, H.Yu, @rnv.bsky.social, C.Lioma, M.Maistro, @apepa.bsky.social and @iaugenstein.bsky.social ⭐️