

Spectacular talk by SNL Early Career Award winner Esti Blanco Elorrieta! Much NeLLab pride, congratulations Esti! 🎉🎉 #SNL2025 @snlmtg.bsky.social
12.09.2025 14:45 — 👍 47 🔁 9 💬 1 📌 0
Spectacular talk by SNL Early Career Award winner Esti Blanco Elorrieta! Much NeLLab pride, congratulations Esti! 🎉🎉 #SNL2025 @snlmtg.bsky.social
12.09.2025 14:45 — 👍 47 🔁 9 💬 1 📌 0
Excited to present this (now-published) project at the 11am poster session today. Poster C36 for the elevator version! #SNL2025
www.nature.com/articles/s44...
Check it out:
📰 Paper: doi.org/10.48550/arX...
💾 Code + data: osf.io/frqbe/files
Let us know what you find!
There’s lots more work to be done here, including tinkering with prompts, model parameters, and extending to freely-available LLMs. In the meantime, we hope this is useful to folks and complements existing tools with something new: fast, scalable, and customizable VFF estimation.
31.07.2025 03:01 — 👍 0 🔁 0 💬 1 📌 0
Evaluating the LLM's, benepar's, and the Stanford Parser's VFF estimates by comparison to Gahl et al.'s (2004) database. The LLM produced the best fit, across 7 different verb frames.
📌 VFFs from Gahl et al. (2004)'s manually annotated (i.e. gold-standard) VFFs
📌 against preferences for competing frames (the dative alternation and NP/SC ambiguity) 🧵6/8

Accuracy for the GPT-4o (LLM) parser, Berkeley Neural Parser (benepar), and Stanford Parser on three manually-parsed verbs. The LLM consistently showed higher agreement with manual parses.
We benchmarked it thoroughly. The LLM consistently outperformed benepar & the Stanford Parser:
📌 300 human-annotated sentences (LLM accuracy = 79%, vs. 69% for benepar and 59% for Stanford) 🧵5/8
That’s particularly exciting because existing datasets don’t scale well. They’re hard to adapt to new verbs/contexts/languages according to experimental need. Our pipeline is simple, scalable, and adaptable. We release the full code + VFF norms for 476 English verbs. 🧵4/8
31.07.2025 03:01 — 👍 1 🔁 0 💬 1 📌 0So we got creative and tried asking an LLM to parse a bunch of sentences. As it turns out, not only did this work, but the LLM outperformed both the Stanford Parser and the Berkeley Neural Parser (benepar), a state-of-the-art deep-learning parser trained on treebanks. 🧵3/8
31.07.2025 03:01 — 👍 1 🔁 0 💬 1 📌 0We needed syntactic norms for an experiment -- specifically Verb Frame Frequencies (VFFs), or how often particular verbs appear in different syntactic frames (e.g., intransitive, prepositional object, etc.). Nothing in the literature quite fit. 🧵2/8
31.07.2025 03:01 — 👍 0 🔁 0 💬 1 📌 0
📊 New Preprint! A Scalable Pipeline for Estimating Verb Frame Frequencies Using Large Language Models. We introduce another unexpected use for LLMs: custom treebanks via automated corpus annotation 🧵1/8
doi.org/10.48550/arX...
Very cool opportunity here!!
26.06.2025 00:55 — 👍 2 🔁 0 💬 0 📌 0I am #hiring for a #postdoc in #aphasia to join me at IU! www.linkedin.com/jobs/view/42...
25.06.2025 15:02 — 👍 14 🔁 9 💬 2 📌 2Thank you, Florence!!
05.06.2025 15:21 — 👍 0 🔁 0 💬 0 📌 0P.S. Yes, we know, Frankenstein wasn't the monster's name. 🤣
05.06.2025 14:08 — 👍 6 🔁 0 💬 2 📌 0
Read more here:
doi.org/10.1038/s442...
Work with my PI Adeen Flinker and our clinical team. So many thanks to labmates and everyone else who helped along the way! 🧵✂️
More broadly, the field has largely assumed that the representations we study with single word production tasks are the same as those involved in sentences. By successfully using models trained on picture naming to decode words in sentences, we verify this 🔑 point. 🧵8/9
05.06.2025 14:08 — 👍 4 🔁 0 💬 1 📌 0These findings show that word processing doesn't always look like it does in picture naming: it depends on task demands. This complexity may even help explain why languages globally prefer placing subjects before objects! 🧵7/9
05.06.2025 14:08 — 👍 5 🔁 0 💬 1 📌 0
Density plots for the number of detections of subjects (left) and objects (right) during the production of subjects and objects in passive sentences, split by two prefrontal regions: IFG (top) and MFG (bottom). IFG sustained representations of subjects throughout both words while MFG sustained representations of objects.
We took a closer look at what was going on in prefrontal cortex. This revealed that these sustained representations traced back to different regions depending on a word's sentence position: when it was a subject, it was encoded in IFG, while MFG encoded objects. 🧵6/9
05.06.2025 14:08 — 👍 5 🔁 0 💬 1 📌 0
Decoding results from middle frontal gyrus during passive sentences showed sustained encoding of the object noun.
In passive sentences like "Frankenstein was hit by Dracula", we observed sustained neural activity encoding BOTH nouns simultaneously throughout the entire utterance. This was particularly true in prefrontal cortex. 🧵5/9
05.06.2025 14:08 — 👍 6 🔁 0 💬 1 📌 0
Decoding results from sensorimotor cortex for active sentences: the subject noun is predicted above chance while it is being said, and the object noun while it is being said.
For straightforward active sentences ("Dracula hit Frankenstein"), the brain activated words sequentially, matching their spoken order. But things changed dramatically for more complex sentences... 🧵4/9
05.06.2025 14:08 — 👍 4 🔁 0 💬 1 📌 0
Word-specific patterns of neural activity: electrodes that selectively responded to each of the six words.
We trained machine learning classifiers to identify each word's specific neural pattern. 🔑We ONLY used data from picture naming (single word production) to train the models. We then used the models to predict what word patients were saying in real time as they said sentences.🧵3
05.06.2025 14:08 — 👍 4 🔁 0 💬 1 📌 0
Task screenshots (picture naming: a cartoon picture of Frankenstein; scene description: cartoon image of Dracula hitting Frankenstein) and mean neural activity per word for one electrode in middle temporal gyrus.
We recorded brain activity directly from cortex in neurosurgical patients (ECoG) while they used 6 words in two tasks: picture naming ("Dracula") and scene description ("Dracula hit Frankenstein"). 🧵2/9
05.06.2025 14:08 — 👍 4 🔁 0 💬 1 📌 0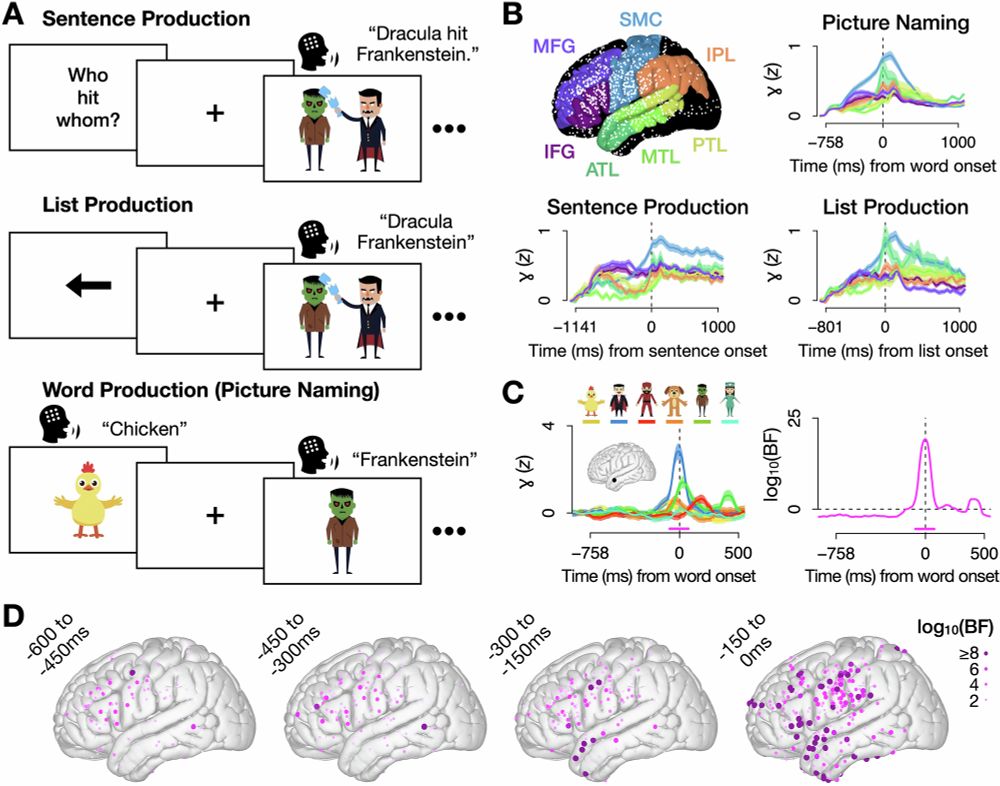
🧠 Newly out: Paper-with-a-way-too-long-name-for-social-media! How does the brain turn words into sentences? We tracked words in participants' brains while they produced sentences, and found some unexpectedly neat patterns. 🧵1/9
rdcu.be/epA1J in @commspsychol.nature.com
Super proud of this! Thread to come soon…
04.06.2025 15:55 — 👍 13 🔁 4 💬 1 📌 0Wow, thanks Laurel! Honestly one of the best compliments I’ve ever gotten given the quality of the other talks!
29.03.2025 19:37 — 👍 1 🔁 0 💬 1 📌 0Work with Jenny Yu, Lyn Ögate, Ismael Dono, and Hannah Sarvasy
29.03.2025 16:40 — 👍 0 🔁 0 💬 0 📌 0
Towet Village, Papua New Guinea
For folx at #HSP2025, tune in at 2:15 for our talk on the processing of Switch-Reference Marking in Nungon, a language spoken by ~1000 ppl that requires speakers to inflect the verb not just for features of its subject, but also for the UPCOMING subject!
hsp2025.github.io/abstracts/15...
Also just want to acknowledge how incredibly cool the other talks in this session were - Shota Momma showed evidence for null structure using really clever priming experiments & Ella Bohlman & Jessica Montag showed (that) (unnecessary) adjectives can make production easier by buying speakers time
29.03.2025 16:25 — 👍 3 🔁 0 💬 2 📌 0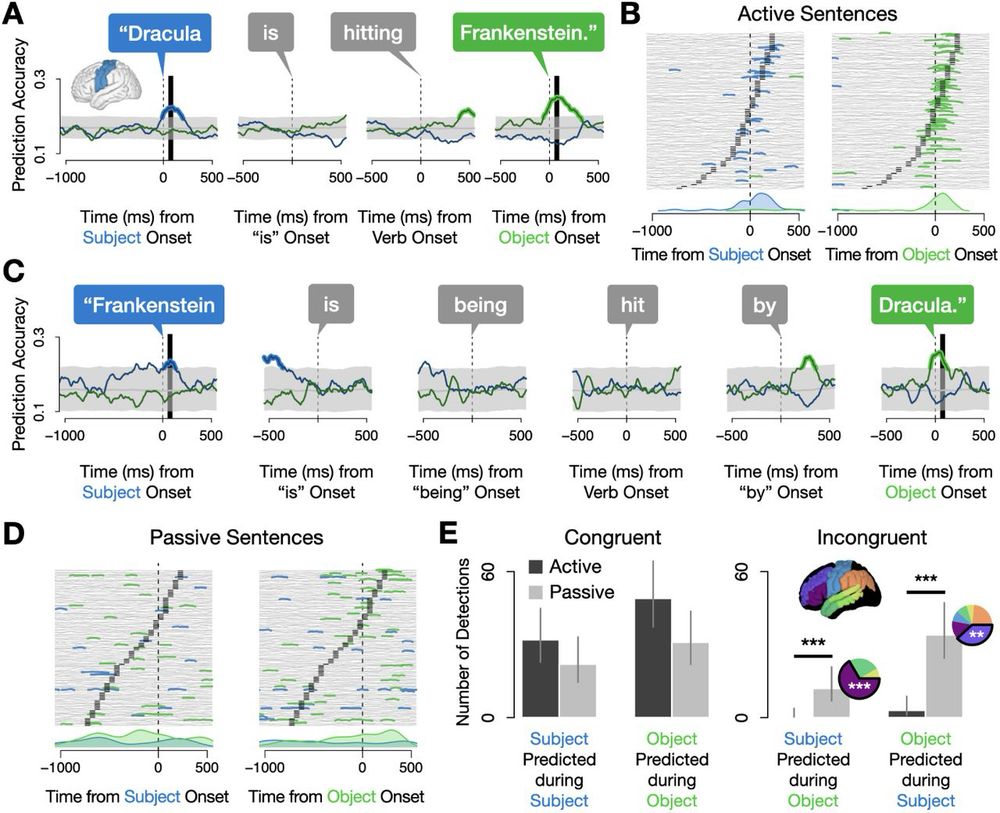
Results of decoding words during the production of active and passive sentences. In actives, nouns were decoded in the order they were said, whereas in passives, prefrontal cortex sustained representations of both the subject and the object throughout the duration of the sentence while sensorimotor areas patterned with actives (showing “congruent” temporal representations).
Just presented our work using #ECoG to decode words during sentence production at #HSP2025. Really grateful for all the great feedback. I got more clever ideas for future directions than I can possibly follow up on. Love this conference!
doi.org/10.1101/2024...

Little late here but this talk at #hsp2025 yesterday was SO neat. Literacy effects disappear when you control for differences in SES. Work by Jessica Vélez Avilés and Paola (Giuli) Dussias
hsp2025.github.io/abstracts/26...