

Read all the details in our ICLR 2026 paper
arxiv.org/abs/2512.14954
authored by Buu Phan, Ashish Khisti and myself
Read all the details in our ICLR 2026 paper
arxiv.org/abs/2512.14954
authored by Buu Phan, Ashish Khisti and myself

LLMs are largely memory bound!
Tokenizers can eat >30% of on‑device memory for small (<1B) models, because we reuse the huge vocabularies from big models.
Our method lets you distill large models into small ones with much smaller vocabulary, reducing overall memory footprint.

If “getting started with agents” feels like setup hell — same.
So we made a starter tutorial:
First agent running in <14 minutes, no Docker/AWS.
Laptop + API key only.
👇 www.youtube.com/watch?v=gzNW...
Want to teach AI agents to use apps like humans? Get started with digital agents research using OpenApps, our new Python-based environment.
10.12.2025 15:44 — 👍 4 🔁 3 💬 1 📌 0
⭐️ facebookresearch.github.io/OpenApps/
📖 arxiv.org/abs/2511.20766
🛠️ Want to build new apps or tasks? Contributions welcome.
Let’s push UI agents forward — together. 🚀
This isn’t just a benchmark — it’s a generator. 🏭
With simple YAML configs, you can spawn thousands of variants of 6 fully functional apps.
Swap themes, scramble layouts, inject “challenging” fonts…
If your agent really understands UIs, this will show it.
Why OpenApps?
✅ Unlimited data for evaluation and training
✅ Lightweight — single CPU, no Docker, no OS emulators
✅ Reliable rewards from ground-truth app state
✅ Plug-and-play with any RL Gym or multimodal LLM agent
Release Day 🎉
Meet OpenApps — a pure-Python, open-source ecosystem for stress-testing UI agents at scale.
Runs on a single CPU. Generates thousands of unique UI variations. And it reveals just how fragile today’s SOTA agents are.
(Yes, even GPT-4 and Claude struggle.)

Excited to be attending NeurIPS 2025 — my 10-year anniversary since I first walked into NeurIPS back in 2015, just before starting my PhD in Amsterdam.
Grateful for a decade of learning, growing, and being part of this incredible community.
If you’re around this year, would love to meet.

One can manipulate LLM rankings to put any model in the lead—only by modifying the single character separating demonstration examples. Learn more in our new paper arxiv.org/abs/2510.05152
w/ Jingtong Su, Jianyu Zhang, @karen-ullrich.bsky.social , and Léon Bottou.
🧵

Y’all, I am at #COLM this week, very excited to learn, and meet old and new friends. Please reach out on Whova!
06.10.2025 22:40 — 👍 5 🔁 0 💬 0 📌 0Check out the full paper here: www.arxiv.org/pdf/2506.17052 🎓 Work by Jingtong Su, @kempelab.bsky.social, @nyudatascience.bsky.social , @aiatmeta.bsky.social
08.07.2025 13:49 — 👍 1 🔁 0 💬 0 📌 0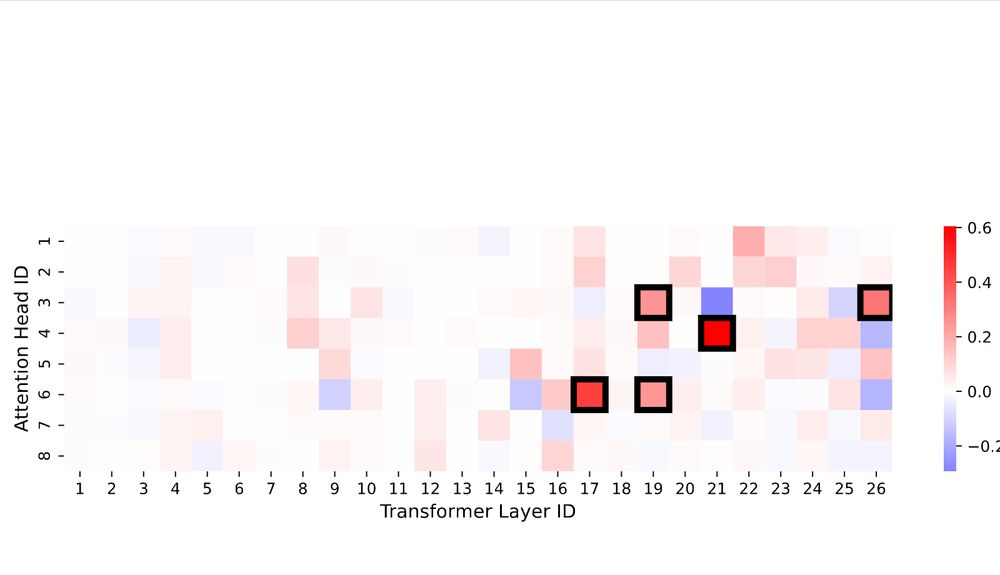
Plus, we generate importance maps showing where in the transformer the concept is encoded — providing interpretable insights into model internals.
08.07.2025 13:49 — 👍 0 🔁 0 💬 1 📌 0
SAMI: Diminishes or amplifies these modules to control the concept's influence
With SAMI, we can scale the importance of these modules — either amplifying or suppressing specific concepts.
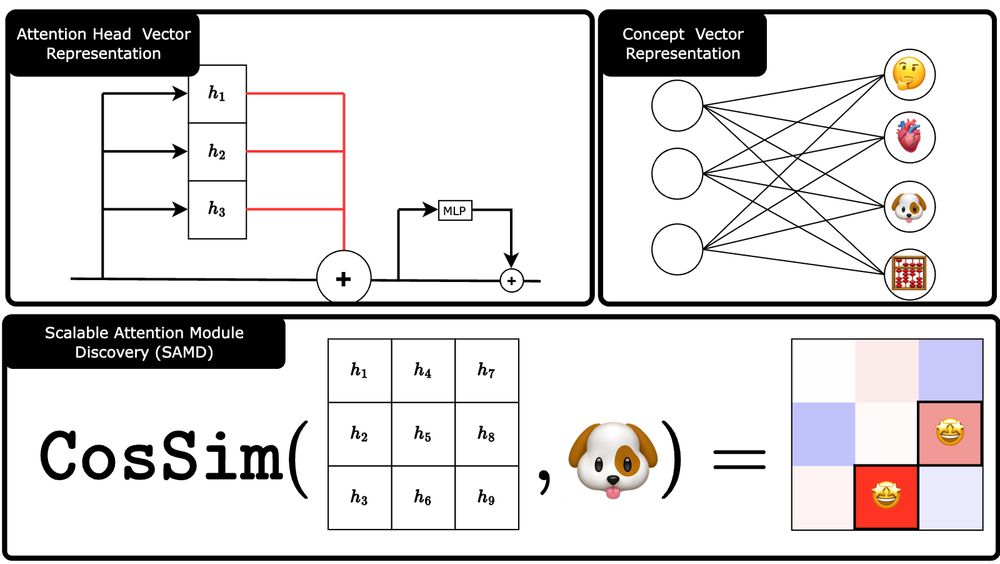
SAMD: Finds the attention heads most correlated with a concept
Using SAMD, we find that only a few attention heads are crucial for a wide range of concepts—confirming the sparse, modular nature of knowledge in transformers.


How would you make an LLM "forget" the concept of dog — or any other arbitrary concept? 🐶❓
We introduce SAMD & SAMI — a novel, concept-agnostic approach to identify and manipulate attention modules in transformers.

Aligned Multi-Objective Optimization (A-🐮) has been accepted at #ICML2025! 🎉
We explore optimization scenarios where objectives align rather than conflict, introducing new scalable algorithms with theoretical guarantees. #MachineLearning #AI #Optimization

Screenshot of arxiv paper "EXACT BYTE-LEVEL PROBABILITIES FROM TOKENIZED LANGUAGE MODELS FOR FIM-TASKS AND MODEL ENSEMBLES."
🎉🎉 Our paper just got accepted to #ICLR2025! 🎉🎉
Byte-level LLMs without training and guaranteed performance? Curious how? Dive into our work! 📚✨
Paper: arxiv.org/abs/2410.09303
Github: github.com/facebookrese...
Thursday is busy:
9-11am I will be at the Meta AI Booth
12.30-2pm
Mission Impossible: A Statistical Perspective on Jailbreaking LLMs (neurips.cc/virtual/2024...)
OR
End-To-End Causal Effect Estimation from Unstructured Natural Language Data (neurips.cc/virtual/2024...)
Starting with Fei-Fei Li’s talk 2.30, after that I will mostly be meeting people and wonder the poster sessions.
11.12.2024 19:39 — 👍 5 🔁 0 💬 0 📌 0
Folks, I am posting my NeurIPS schedule daily in hopes to see folks, thanks @tkipf.bsky.social for the idea ;)
11-12.30 WiML round tables
1.30-4 Beyond Decoding, Tutorial
I will be at #Neurips2024 next week to talk about these two papers and host a workshop on #NeuralCompression.
06.12.2024 16:54 — 👍 3 🔁 0 💬 0 📌 0next one on the list is Yury Polyanskiy's "Information Theory: From Coding to Learning" which will hopefully hit the shelfs in February... can not wait
28.11.2024 15:49 — 👍 3 🔁 0 💬 0 📌 0
Pro-tip: Use massive black Friday deals at scientific publishing houses to for example buy a copy of @jmtomczak.bsky.social
book on generative modeling (long overdue)
🫠
20.11.2024 20:57 — 👍 0 🔁 0 💬 1 📌 0Me
18.11.2024 18:10 — 👍 2 🔁 0 💬 0 📌 0Me
18.11.2024 11:21 — 👍 0 🔁 0 💬 1 📌 0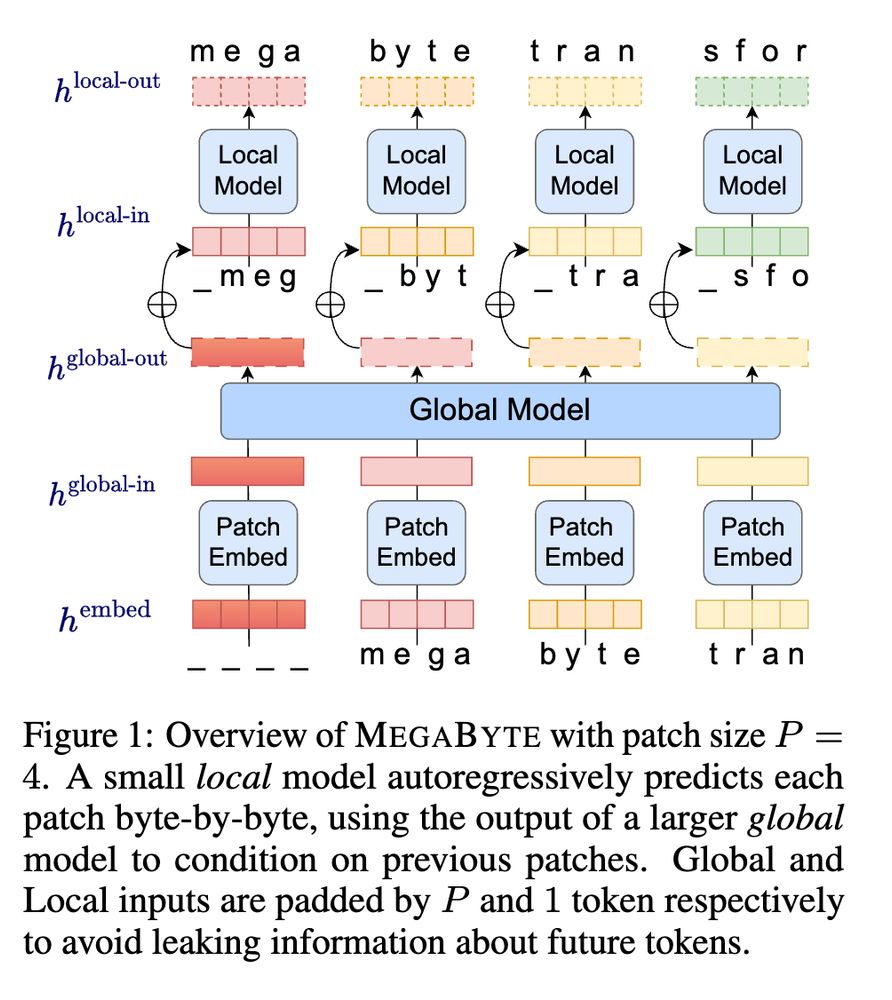
What do you think do we need to sharpen our understanding of tokenization? Or will we soon be rid of it by developing models such as "MegaByte" by
Yu et al?
And add more paper to the threat!
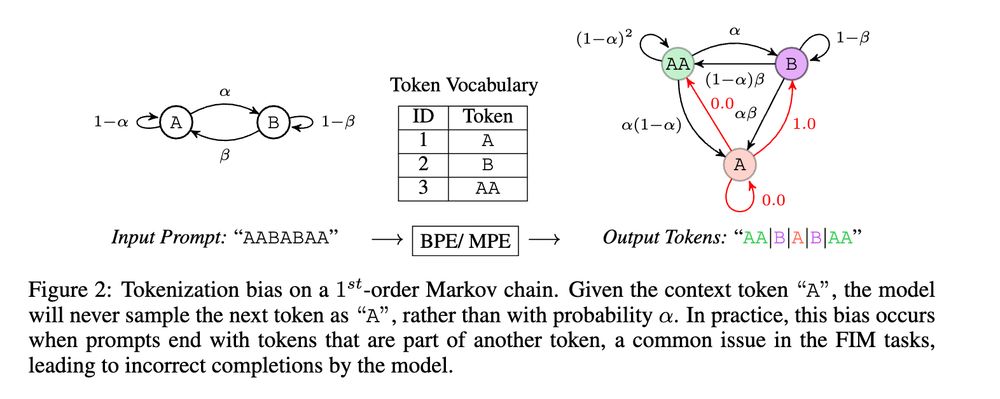
Phan et al, found a method to mitigate some of the tokenization problems Karpathy mentioned by projecting tokens into byte space. The key to their method is to develop a map between statistically equivalent token and byte-level models.
30.10.2024 18:29 — 👍 3 🔁 1 💬 0 📌 0
In "The Foundations of Tokenization:
Statistical and Computational Concerns", Gastaldi et al. try to make first steps towards defining what a tokenizer should be and define properties it ought to have.

