8/ 🎉 Thanks to the incredible team that made this possible! 🙌
Ram Pasunuru, @pedro-rodriguez.bsky.social, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, @lukezettlemoyer.bsky.social, Gargi Ghosh, Mike Lewis, @ari-holtzman.bsky.social, Srinivasan Iyer
13.12.2024 16:53 — 👍 4 🔁 0 💬 0 📌 0
GitHub - facebookresearch/blt: Code for BLT research paper
Code for BLT research paper. Contribute to facebookresearch/blt development by creating an account on GitHub.
7/ BLT has direct access to bytes but at its core still has a Transformer that operates over patches - the best of both worlds. But it’s just the beginning! We are releasing the training and inference code at github.com/facebookrese...
13.12.2024 16:53 — 👍 4 🔁 0 💬 1 📌 1
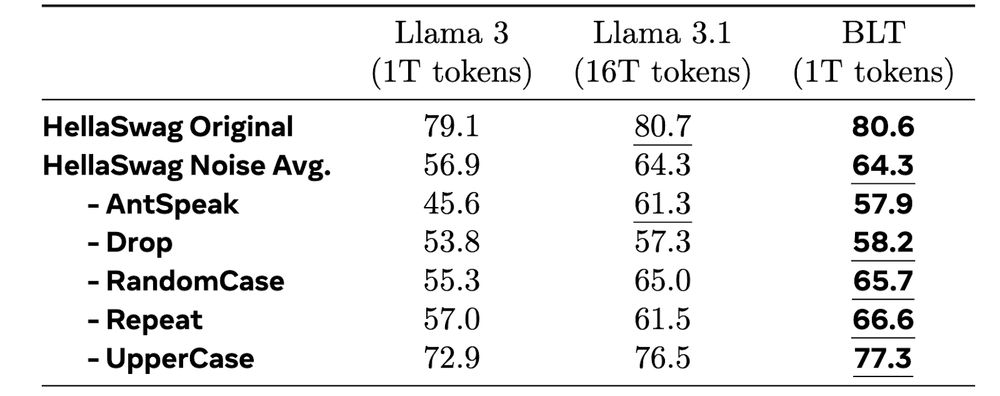
6/ Without direct modeling of bytes Llama 3.1 trained on 16x more data still lags behind on some of these tasks!
13.12.2024 16:53 — 👍 1 🔁 0 💬 1 📌 0
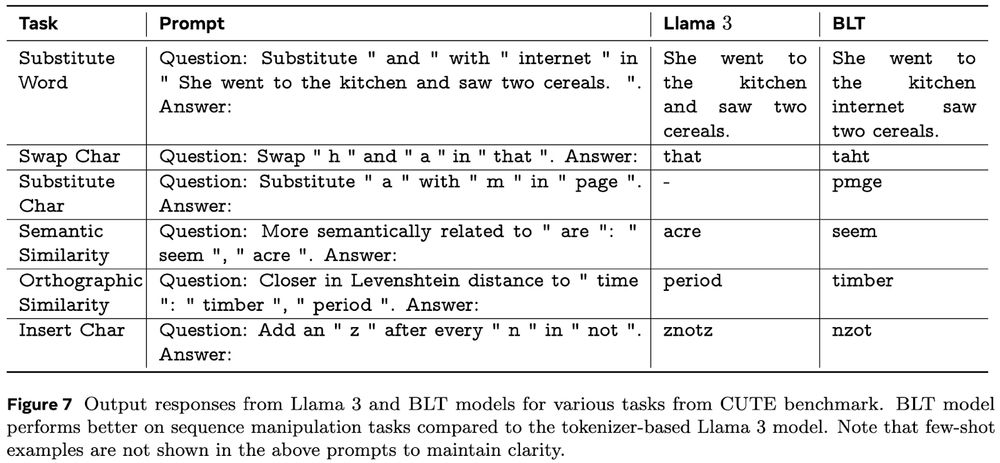
5/ 💪 But where BLT excels is at modeling the long-tail of data with better robustness to noise and improved understanding and manipulation of substrings.
13.12.2024 16:53 — 👍 2 🔁 0 💬 1 📌 1
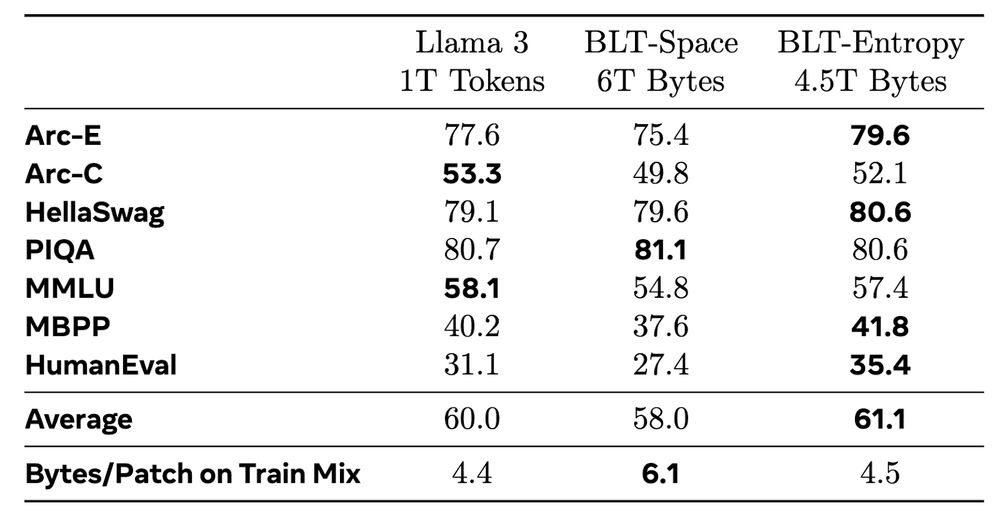
4/ ⚡ Parameter matched training runs up to 8B params and 4T bytes show that BLT performs well on standard benchmarks, and can trade minor losses in evaluation metrics for up to 50% reductions in inference flops.
13.12.2024 16:53 — 👍 1 🔁 0 💬 1 📌 0
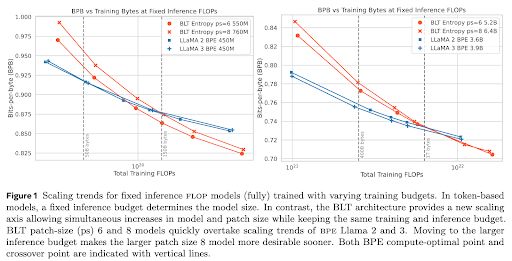
3/ 📈 BLT unlocks a new scaling dimension by simultaneously growing patch and model size without changing training or inference cost. Patch length scaling quickly overtakes BPE transformer scaling, and the trends look even better at larger scales!
13.12.2024 16:53 — 👍 1 🔁 0 💬 1 📌 0
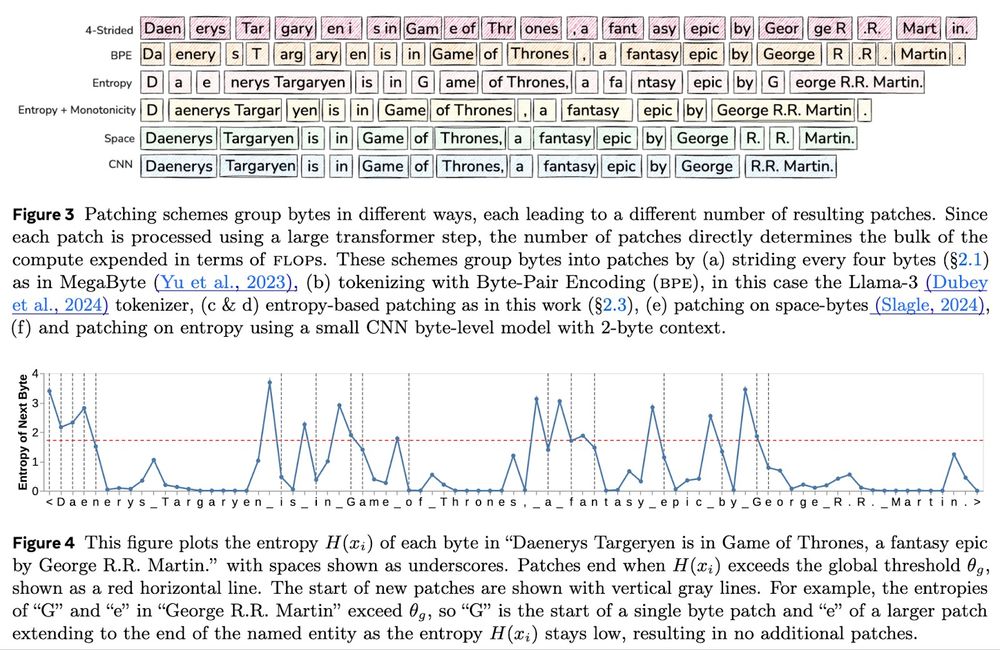
2/ 🧩 Entropy patching dynamically adjusts patch sizes based on data complexity, allowing BLT to allocate more compute to hard predictions and use larger patches for simpler ones. This results in fewer larger processing steps to cover the same data.
13.12.2024 16:53 — 👍 2 🔁 0 💬 1 📌 0
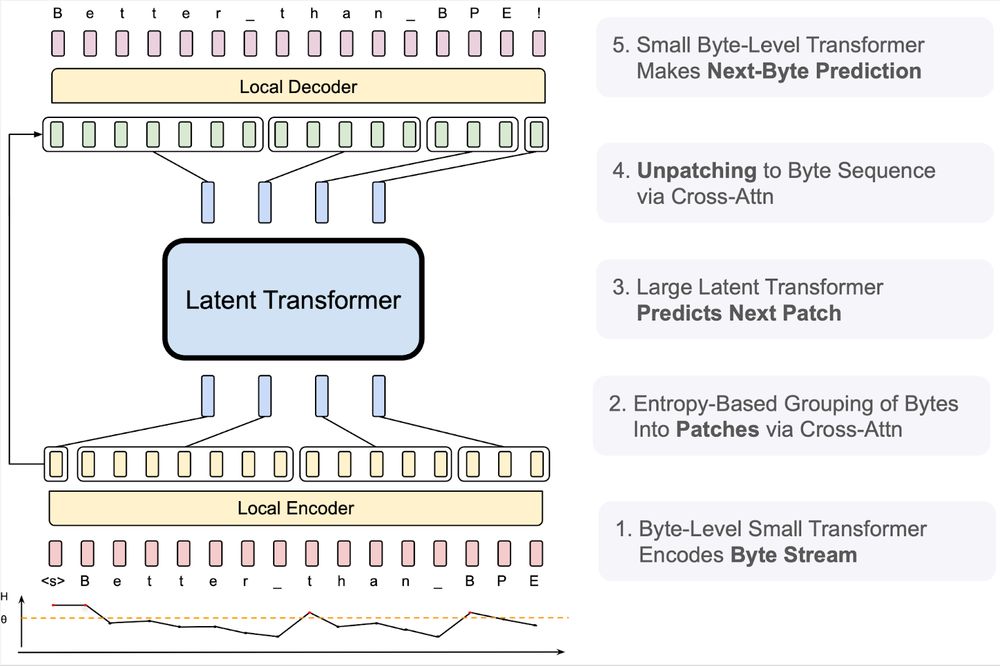
1/ 🧱 BLT encodes bytes into dynamic patches using light-weight local models and processes them with a large latent transformer. Think of it as a transformer sandwich! 🥪
13.12.2024 16:53 — 👍 2 🔁 0 💬 1 📌 0
🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
13.12.2024 16:53 — 👍 60 🔁 15 💬 5 📌 3




