Personal programs for ICCV 2025 are now available at:
www.scholar-inbox.com/conference/i...

@xingyu-chen.bsky.social
PhD Student at Westlake University, working on 3D & 4D Foundation Models. https://rover-xingyu.github.io/
Personal programs for ICCV 2025 are now available at:
www.scholar-inbox.com/conference/i...
Look, 4D foundation models know about humans – and we just read it out!
08.10.2025 11:19 — 👍 1 🔁 0 💬 0 📌 0Glad to be recognized as an outstanding reviewer!
05.10.2025 15:25 — 👍 2 🔁 0 💬 0 📌 0🔗Page: rover-xingyu.github.io/TTT3R
📄Paper: arxiv.org/abs/2509.26645
💻Code: github.com/Inception3D/...
Big thanks to the amazing team!
@xingyu-chen.bsky.social @fanegg.bsky.social @xiuyuliang.bsky.social @andreasgeiger.bsky.social @apchen.bsky.social
Instead of updating all states uniformly, we incorporate image attention as per-token learning rates.
High-confidence matches get larger updates, while low-quality updates are suppressed.
This soft gating greatly extends the length generalization beyond the training context.
#VGGT: accurate within short clips, but slow and prone to Out-of-Memory (OOM)
#CUT3R: fast with constant memory usage, but forgets.
We revisit them from a Test-Time Training (TTT) perspective and propose #TTT3R to get all three: fast, accurate, and OOM-free.
Let's keep revisiting 3D reconstruction!
01.10.2025 07:20 — 👍 2 🔁 0 💬 0 📌 0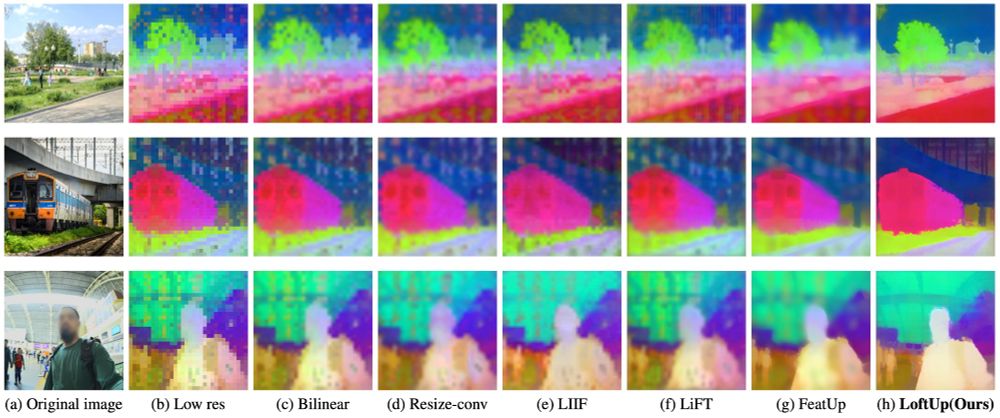
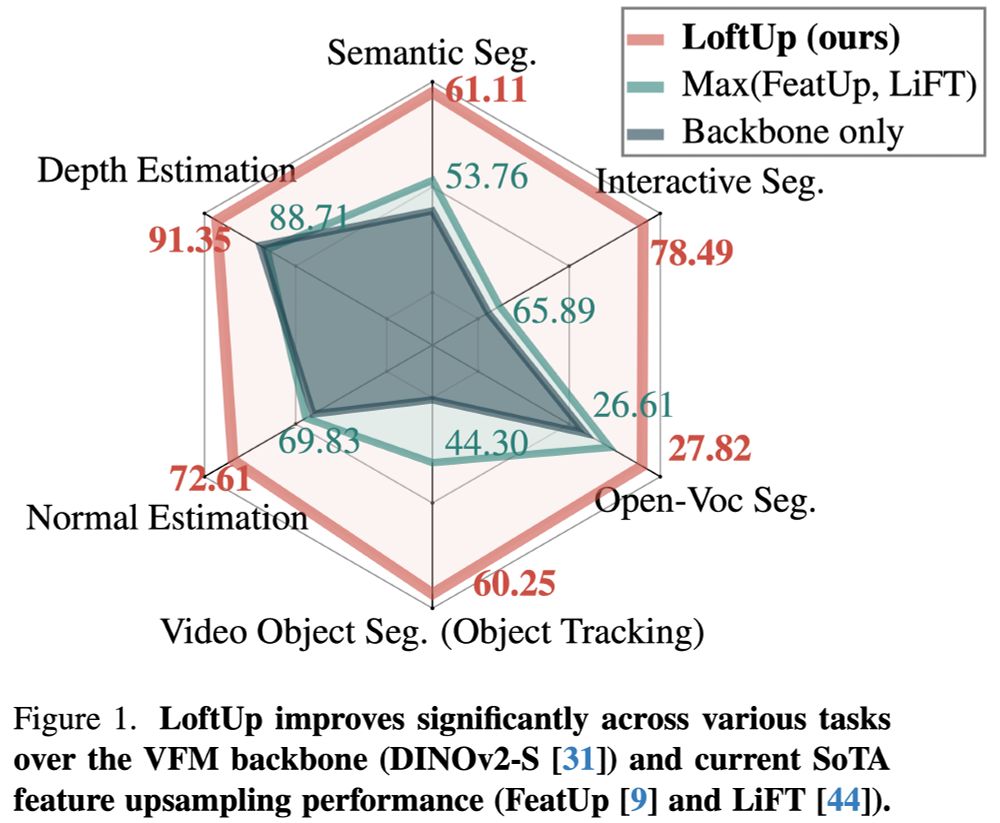
Excited to introduce LoftUp!
A strong (than ever) and lightweight feature upsampler for vision encoders that can boost performance on dense prediction tasks by 20%–100%!
Easy to plug into models like DINOv2, CLIP, SigLIP — simple design, big gains. Try it out!
github.com/andrehuang/l...
If you're a researcher and haven't tried it yet, please give it a try! It took me a while to adjust, but now it's my favorite tool. You can read, bookmark, organize papers, and get recommendations based on your interests!
15.04.2025 05:37 — 👍 1 🔁 0 💬 0 📌 0



Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
@xingyu-chen.bsky.social, @fanegg.bsky.social, @xiuyuliang.bsky.social, @andreasgeiger.bsky.social, @apchen.bsky.social
arxiv.org/abs/2503.24391


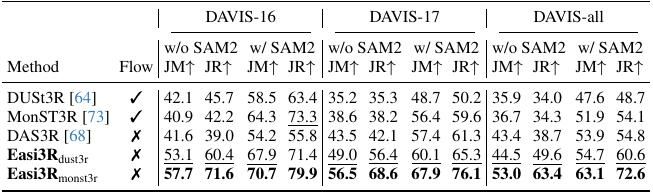
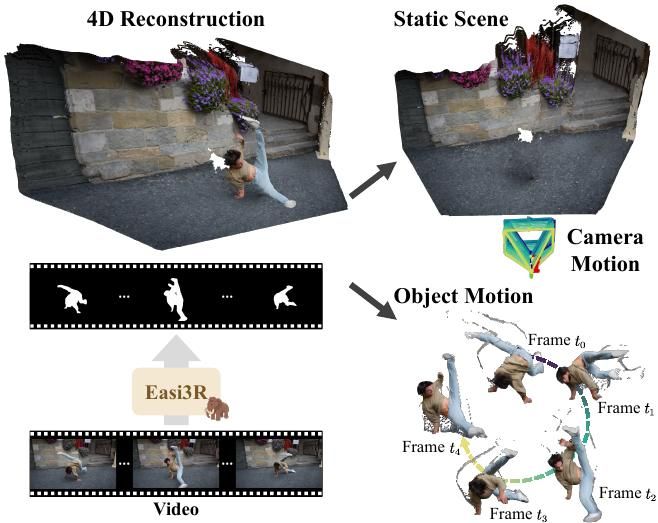
𝗘𝗮𝘀𝗶𝟯𝗥: 𝗘𝘀𝘁𝗶𝗺𝗮𝘁𝗶𝗻𝗴 𝗗𝗶𝘀𝗲𝗻𝘁𝗮𝗻𝗴𝗹𝗲𝗱 𝗠𝗼𝘁𝗶𝗼𝗻 𝗳𝗿𝗼𝗺 𝗗𝗨𝗦𝘁𝟯𝗥 𝗪𝗶𝘁𝗵𝗼𝘂𝘁 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴
Xingyu Chen, Yue Chen, Yuliang Xiu ... Anpei Chen
arxiv.org/abs/2503.24391
Trending on www.scholar-inbox.com
DUSt3R was never trained to do dynamic segmentation with GT masks, right? It was just trained to regress point maps on 3D datasets—yet dynamic awareness emerged, making DUSt3R a zero-shot 4D estimator!😀
02.04.2025 07:59 — 👍 4 🔁 0 💬 1 📌 0I was really surprised when I saw this. Dust3R has learned very well to segment objects without supervision. This knowledge can be extracted post-hoc, enabling accurate 4D reconstruction instantly.
01.04.2025 18:45 — 👍 31 🔁 2 💬 1 📌 0🔗Page: easi3r.github.io
📄Paper: arxiv.org/abs/2503.24391
💻Code: github.com/Inception3D/...
Big thanks to the amazing team!
@xingyu-chen.bsky.social, @fanegg.bsky.social, @xiuyuliang.bsky.social, @andreasgeiger.bsky.social, @apchen.bsky.social
With our estimated segmentation masks, we perform a second inference pass by re-weighting the attention, enabling robust 4D reconstruction and even outperforming SOTA methods trained on 4D datasets, with almost no extra cost compared to vanilla DUSt3R.
01.04.2025 15:25 — 👍 4 🔁 0 💬 1 📌 0We propose an attention-guided strategy to decompose dynamic objects from the static background, enabling robust dynamic object segmentation. It outperforms the optical-flow guided segmentation, like MonST3R, and the model trained on dynamic mask labels, like DAS3R.
01.04.2025 15:24 — 👍 3 🔁 0 💬 1 📌 0💡Humans naturally separate ego-motion from object-motion without dynamic labels. We observe that #DUSt3R has implicitly learned a similar mechanism, reflected in its attention layers.
01.04.2025 15:23 — 👍 3 🔁 0 💬 1 📌 1🦣Easi3R: 4D Reconstruction Without Training!
Limited 4D datasets? Take it easy.
#Easi3R adapts #DUSt3R for 4D reconstruction by disentangling and repurposing its attention maps → make 4D reconstruction easier than ever!
🔗Page: easi3r.github.io
How much 3D do visual foundation models (VFMs) know?
Previous work requires 3D data for probing → expensive to collect!
#Feat2GS @cvprconference.bsky.social 2025 - our idea is to read out 3D Gaussains from VFMs features, thus probe 3D with novel view synthesis.
🔗Page: fanegg.github.io/Feat2GS