New (revised) preprint with @thecharleywu.bsky.social
We rethink how to assess machine consciousness: not by code or circuitry, but by behavioral inference—as in cognitive science.
Extraordinary claims still need extraordinary evidence.
👉 osf.io/preprints/ps...
#AI #Consciousness #LLM
08.10.2025 09:02 — 👍 16 🔁 4 💬 0 📌 1

Curious about LLM interpretability and understanding ? We borrowed concepts from genetics to map language models, predict their capabilities, and even uncovered surprising insights about their training !
Come see my poster at #ICLR2025 3pm Hall 2B #505 !
26.04.2025 02:03 — 👍 5 🔁 0 💬 0 📌 0
In short, PhyloLM is a cheap and versatile algorithm that generates useful representations for LLMs that can have creative applications in pratice. 9/10
paper : arxiv.org/abs/2404.04671
colab : colab.research.google.com/drive/1agNE5...
code : github.com/Nicolas-Yax/...
ICLR : Saturday 3pm Poster 505
24.04.2025 13:15 — 👍 2 🔁 0 💬 1 📌 0

By using code related contexts we can obtain a fairly different map. For example we notice that Qwen and GPT-3.5 have a very different way of coding compared to the other models which was not visible on the reasoning map. 7/10
24.04.2025 13:15 — 👍 2 🔁 0 💬 1 📌 0

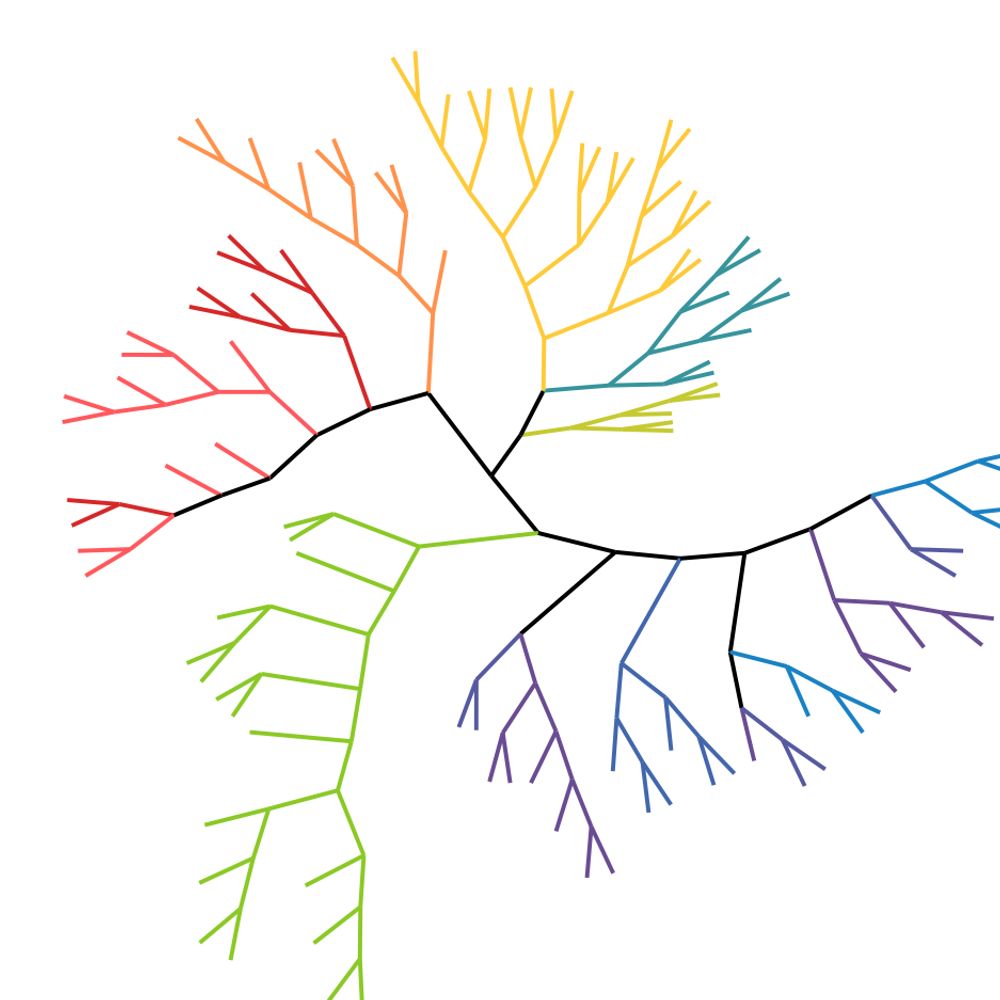
The contexts choice is important as it reflects different capabilities of LLMs. Here on a general reasoning type of context we can plot a map of models using UMAP. The larger the edge, the closer models are from each other. Models on the same cluster are even closer ! 6/10
24.04.2025 13:15 — 👍 2 🔁 0 💬 1 📌 0

It can also measure quantization efficiency by observing the behavioral distance between LLM and quantized versions. In the Qwen 1.5 release, GPTQ seems to perform best. This new concept of metric could provide additional insights to quantization efficiency. 5/10
24.04.2025 13:15 — 👍 2 🔁 0 💬 1 📌 0

Aside from plotting trees, PhyloLM similarity matrix is very versatile. For example, running a logistic regression on the distance matrix makes it possible to predict performance of new models even from unseen families with good accuracy. Here is what we got on ARC. 4/10
24.04.2025 13:15 — 👍 2 🔁 0 💬 1 📌 0

Not taking into account these requirements can still produce efficient distance vizualisation trees. However it is important to remember they do not represent evolutionary trees. Feel free to zoom in to see model names. 3/10
24.04.2025 13:15 — 👍 2 🔁 0 💬 1 📌 0

Phylogenetic algorithms often require common ancestors to not appear in the objects studied but are clearly able to retrieve the evolution of the family. Here is an example in the richness of open-access model : @teknium.bsky.social @maximelabonne.bsky.social @mistralai.bsky.social 2/10
24.04.2025 13:15 — 👍 2 🔁 0 💬 1 📌 0

We build a distance matrix from comparing outputs of LLMs to a hundred of different contexts and build maps and trees from this distance matrix. Because PhyloLM only requires sampling very few tokens after a very short contexts the algorithm is particularly cheap to run. 1/10
24.04.2025 13:15 — 👍 3 🔁 0 💬 1 📌 0

🔥Our paper PhyloLM got accepted at ICLR 2025 !🔥
In this work we show how easy it can be to infer relationship between LLMs by constructing trees and to predict their performances and behavior at a very low cost with @stepalminteri.bsky.social and @pyoudeyer.bsky.social ! Here is a brief recap ⬇️
24.04.2025 13:15 — 👍 16 🔁 5 💬 3 📌 2
we are recruiting interns for a few projects with @pyoudeyer
in bordeaux
> studying llm-mediated cultural evolution with @nisioti_eleni
@Jeremy__Perez
> balancing exploration and exploitation with autotelic rl with @ClementRomac
details and links in 🧵
please share!
27.11.2024 17:43 — 👍 6 🔁 6 💬 1 📌 0
Putting some Flow Lenia here too
22.11.2024 09:51 — 👍 4 🔁 1 💬 1 📌 0
1/⚡️Looking for a fast and simple Transformer baseline for your RL environment in JAX ?
Sharing my implementation of transformerXL-PPO: github.com/Reytuag/tran...
The implementation is the first to attain the 3rd floor and obtain advanced achievements in the challenging Craftax
22.11.2024 10:15 — 👍 3 🔁 1 💬 1 📌 0
It is part of a research agenda to open the LLM black box and provide tools for researchers to better interact with models in a more transparent manner. The last paper in this agenda was PhyloLM proposing methods to investigate the phylogeny of LLMs arxiv.org/abs/2404.04671 15/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0
This method was first introduced in our paper Studying and improving reasoning in humans and machines investigating the evolution of cognitive biases in language models. www.nature.com/articles/s44... 14/15
15.11.2024 13:47 — 👍 1 🔁 0 💬 1 📌 0
As such, LogProber can be a useful tool to check contamination in language models at a very low cost (one forward pass) given some very high level assumptions about the training method (that are very often verified in practice). 13/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0
Lastly, the A scenario is more common in instruction finetuning scenarios. In open access models finetuning databases are often shared making it possible to check directly if the item is found in the training set which is rarely the case for pretraining databases. 12/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0

On the other hand, if the score is high, both QA and Q are possible namely the model has seen the question but maybe not the answer during training. LogProber is not able to find which scenario happened but the item is suspicious. 11/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0

When testing a LLM on an item only one of these scenarios is possible. This means that if a model pretrained with a full language modelling method returns a low contamination score with LogProber on a given item, then the item is safe as only the STD scenario is possible. 10/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0

Most LLMs are pretrained in a full language modelling manner meaning they fit on all tokens (both question and answer tokens) meaning A type of training is not a likely scenario. 9/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0
Results indicate that LogProber is able to accurately predict contamination in QA and STD scenarios, Q leading to false positives and A, to false negatives. In practice some of these scenarios are not possible depending on how the LLM is trained. 8/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0

QA is when both appear, A when both are present but the model only fits on the tokens of the answer (usually happens in some finetuning methods) and STD when neither the question nor the answer appear in the training data. 7/15
15.11.2024 13:47 — 👍 0 🔁 0 💬 1 📌 0
Waiting on a robot body. All opinions are universal and held by both employers and family.
Literally a professor. Recruiting students to start my lab.
ML/NLP/they/she.
Postdoc in @summerfieldlab.bsky.social at Oxford studying learning in humans and machines
Interested in collective intelligence, metascience, philosophy of science
@oxforducu.bsky.social member
You can find me on Mastodon at neuromatch.social/@jess
assoc prof, uc irvine cogsci & LPS: perception+metacognition+subjective experience, fMRI+models+AI
phil sci, education for all
2026: UCI-->UCL!
prez+co-founder, neuromatch.io
fellow, CIFAR brain mind consciousness
meganakpeters.org
she/her💖💜💙views mine
Researcher at Inria. Simulating the origins of life, cognition and culture. Using methods from ALife and AI.
Publications: https://scholar.google.com/citations?hl=en&user=rBnV60QAAAAJ&view_op=list_works&sortby=pubdate
Prev. posts still on X same username
Cognitive Science postdoc. University of Geneva. Ex-HRL team (DEC, ENS, Paris)
human behavior/reinforcement learning/decision-making/computational modeling
PhD Student at the Paris Brain Institute | Creativity, Decision, Affects & Computational modelling
🔗 https://sites.google.com/view/frontlab-icm/people/phd-students/gino-battistello
PhD student at HCAI lab with @ericschulz.bsky.social
Language and thought in brains and in machines. Assistant Prof @ Georgia Tech Psychology. Previously a postdoc @ MIT Quest for Intelligence, PhD @ MIT Brain and Cognitive Sciences. She/her
https://www.language-intelligence-thought.net
Interested in natural and artificial minds.
https://akjagadish.github.io
PhD student in the Flowers team at INRIA-Bordeaux.
ai interpretability research and running • thinking about how models think • prev @MIT cs + physics
phd student in Munich, working on machine learning and cognitive science
Chercheur associé Inria Flowers et LEARN EPFL, IA et apprentissages
#Education #AI
PhD student at Flowers Inria, focusing on open-ended evolution in cellular automata
Research director @Inria, Head of @flowersInria
lab, prev. @MSFTResearch @SonyCSLParis
Artificial intelligence, cognitive sciences, sciences of curiosity, language, self-organization, autotelic agents, education, AI and society
http://www.pyoudeyer.com