AstroVisbench · AstroVisBench
My amazing co-authors: Syed Murtaza Husain, Stella Offner, @stephajuneau.bsky.social, Paul Torrey, Adam Bolton, Juan Frias, @niall2.bsky.social, @gregdnlp.bsky.social, and @jessyjli.bsky.social.
Full support from @nsfsimonscosmicai.bsky.social.
🌐: astrovisbench.github.io
📄: arxiv.org/abs/2505.20538
02.06.2025 15:41 —
👍 3
🔁 0
💬 0
📌 0
We think this dataset is a great target for AI for science efforts. It zeroes in on an important part of the scientific workflow that is achievable near term and aims to produce tools used by astronomers, not aiming to replace them or automate all of science.
02.06.2025 15:41 —
👍 1
🔁 0
💬 1
📌 0
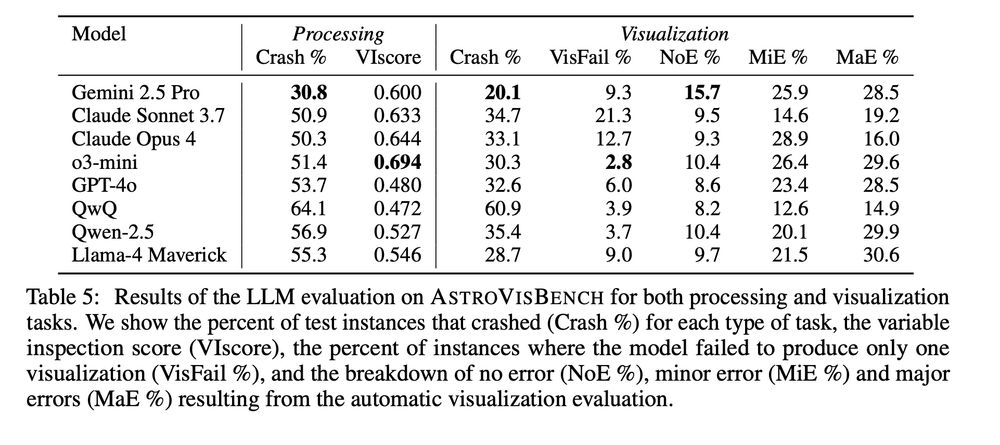
Even the best LLMs struggle to execute scientific workflows.
SOTA models including Gemini 2.5 Pro, Claude Opus 4, o3-mini and QwQ crash 30-60% of the time and only produce visualizations without error in less than 16% of the cases.
02.06.2025 15:41 —
👍 1
🔁 0
💬 1
📌 0

We generate code from a model, run it, and evaluate the following:
Processing tasks: we compare key variable values.
Visualizations: we use a VLM judge (well correlated w/ pro astronomers) that compares a visualization’s scientific utility to that of the ground truth.
02.06.2025 15:41 —
👍 1
🔁 0
💬 1
📌 0
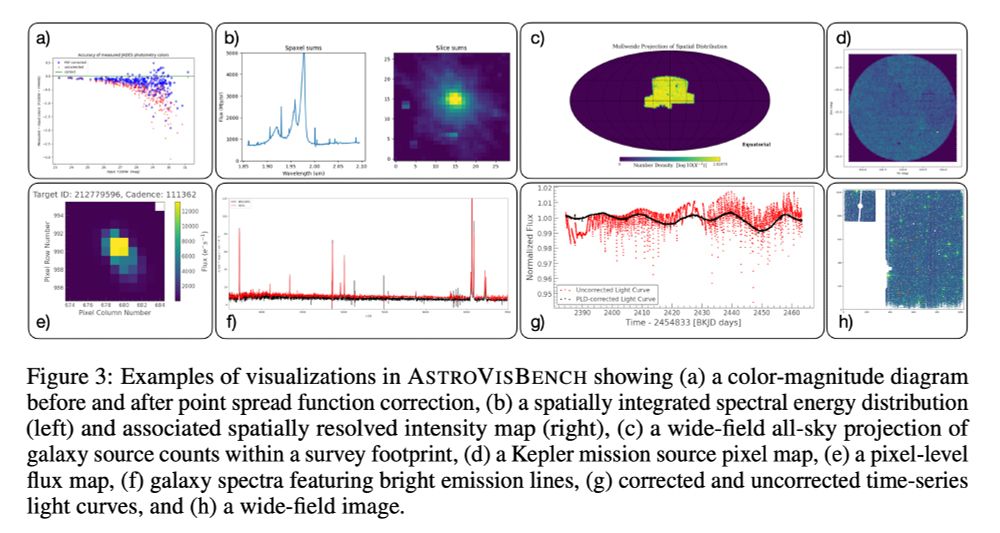
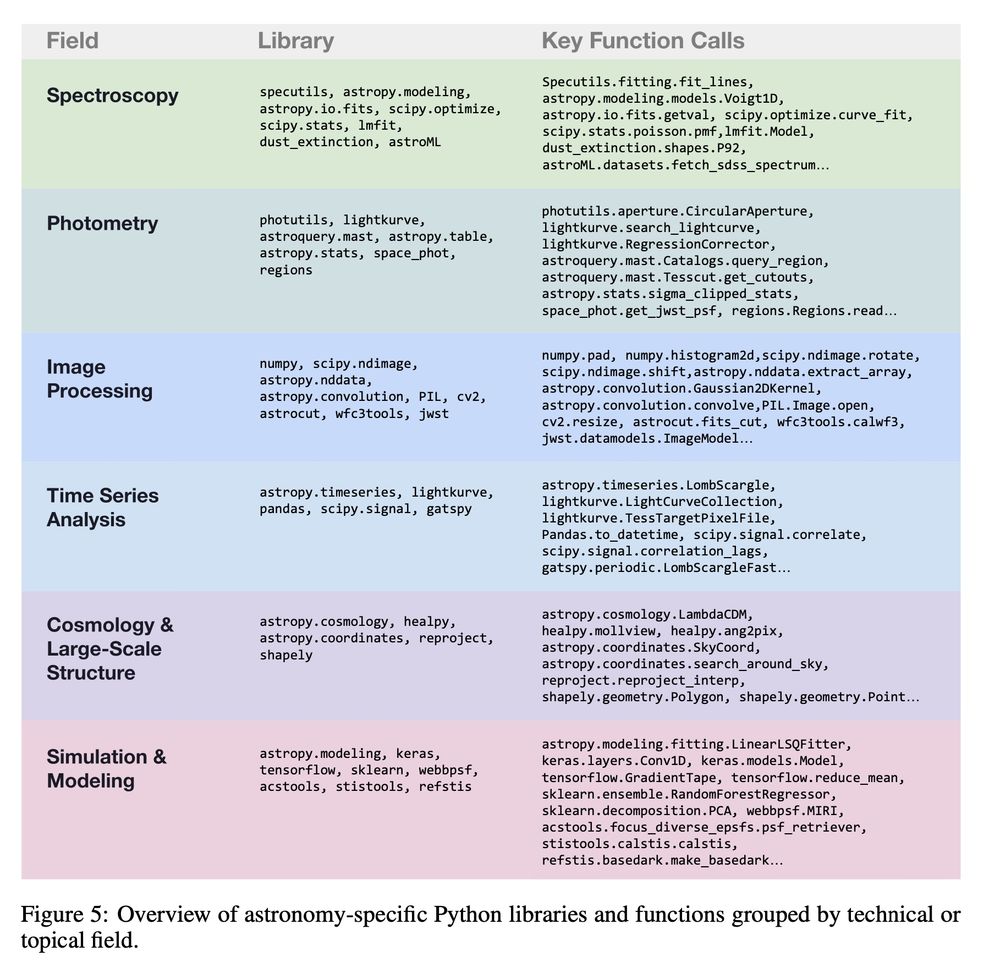
We created AstroVisBench from expert-curated jupyter notebooks for astronomy tasks, from which we constructed 432 sets of processing and plotting tasks. It tests a diverse set of visualizations and long-tail API use.
02.06.2025 15:41 —
👍 1
🔁 0
💬 1
📌 0


How good are LLMs at 🔭 scientific computing and visualization 🔭?
AstroVisBench tests how well LLMs implement scientific workflows in astronomy and visualize results.
SOTA models like Gemini 2.5 Pro & Claude 4 Opus only match ground truth scientific utility 16% of the time. 🧵
02.06.2025 15:41 —
👍 10
🔁 2
💬 1
📌 4
