
🚨 New paper on regression and classification!
Adding to the discussion on using least-squares or cross-entropy, regression or classification formulations of supervised problems!
A thread on how to bridge these problems:

@ozekri.bsky.social
ENS Saclay maths dpt + UW Research Intern. Website : https://oussamazekri.fr Blog : https://logb-research.github.io/
🚨 New paper on regression and classification!
Adding to the discussion on using least-squares or cross-entropy, regression or classification formulations of supervised problems!
A thread on how to bridge these problems:
You mean, we don’t stop at the frontier of the convex set but just a bit further ?
Wow, does this trick have a name?
Looks nice!! Will stop by your notebooks
05.02.2025 22:28 — 👍 1 🔁 0 💬 0 📌 0Working with him these past months has been both fun and inspiring. He’s an incredibly talented researcher! 🚀
If you haven’t heard of him, check out his work : he’s one of the pioneers of operator learning and pushing this field to new heights!
Thanks for reading !
❤️ Work done during my 3-months internship at Imperial College!
A huge thanks to Nicolas Boullé (nboulle.github.io) for letting me work on a topic that interested me a lot during the internship.

We fine-tuned a discrete diffusion model to respond to user prompts. In just 7k iterations (GPU poverty is real, haha), it outperforms the vanilla model ~75% of the time! 🚀
04.02.2025 15:42 — 👍 1 🔁 0 💬 1 📌 0
Building on this, we can correct the gradient direction to better **follow the flow**, using the implicit function theorem (cf @mblondel.bsky.social et al., arxiv.org/abs/2105.15183 )✨
The cool part? We only need to invert a linear system, whose inverse is known in closed form! 🔥

Inspired by Implicit Diffusion (@pierremarion.bsky.social @akorba.bsky.social @qberthet.bsky.social🤓, arxiv.org/abs/2402.05468), we sample using a specific CTMC, reaching the limiting distribution in an infinite time horizon. This effectively implements a gradient flow w.r.t. a Wasserstein metric!🔥
04.02.2025 15:42 — 👍 2 🔁 0 💬 1 📌 0
SEPO, like most policy optimization algorithms, alternates between sampling and optimization. But what if sampling itself was seen as an optimization procedure in distribution space? 🚀
04.02.2025 15:42 — 👍 2 🔁 0 💬 1 📌 0
If you have a discrete diffusion model (naturally designed for discrete data, e.g. language or DNA sequence modeling), you can finetune it with non-differentiable reward functions! 🎯
For example, this enables RLHF for discrete diffusion models, making alignment more flexible and powerful. ✅


The main gradient takes the form of a weighted log concrete score, echoing DeepSeek’s unified paradigm with the weighted log policy!🔥
From this, we can reconstruct any policy gradient method for discrete diffusion models (e.g. PPO, GRPO etc...). 🚀

The main bottleneck of Energy-Based Models is computing the normalizing constant Z.
Instead, recent discrete diffusion models skip Z by learning ratios of probabilities. This forms the concrete score, which a neural network models efficiently!⚡
The challenge? Using this score network as a policy.

🚀 Policy gradient methods like DeepSeek’s GRPO are great for finetuning LLMs via RLHF.
But what happens when we swap autoregressive generation for discrete diffusion, a rising architecture promising faster & more controllable LLMs?
Introducing SEPO !
📑 arxiv.org/pdf/2502.01384
🧵👇
Beautiful work!!
04.02.2025 11:59 — 👍 1 🔁 0 💬 0 📌 0
🚀Proud to share our work on the training dynamics in Transformers with Wassim Bouaziz & @viviencabannes.bsky.social @Inria @MetaAI
📝Easing Optimization Paths arxiv.org/pdf/2501.02362 (accepted @ICASSP 2025 🥳)
📝Clustering Heads 🔥https://arxiv.org/pdf/2410.24050
🖥️ github.com/facebookrese...
1/🧵

Happy to see Disentangled In-Context Learning accepted at ICLR 2025 🥳
Make zero-shot reinforcement learning with LLMs go brrr 🚀
🖥️ github.com/abenechehab/...
📜 arxiv.org/pdf/2410.11711
Congrats Abdelhakim (abenechehab.github.io) for leading it, always fun working with nice and strong people 🤗

For the French-speaking audience, S. Mallat's courses at the College de France on Data generation in AI by transport and denoising have just started. I highly recommend them, as I've learned a lot from the overall vision of his courses.
Recordings are also available: www.youtube.com/watch?v=5zFh...
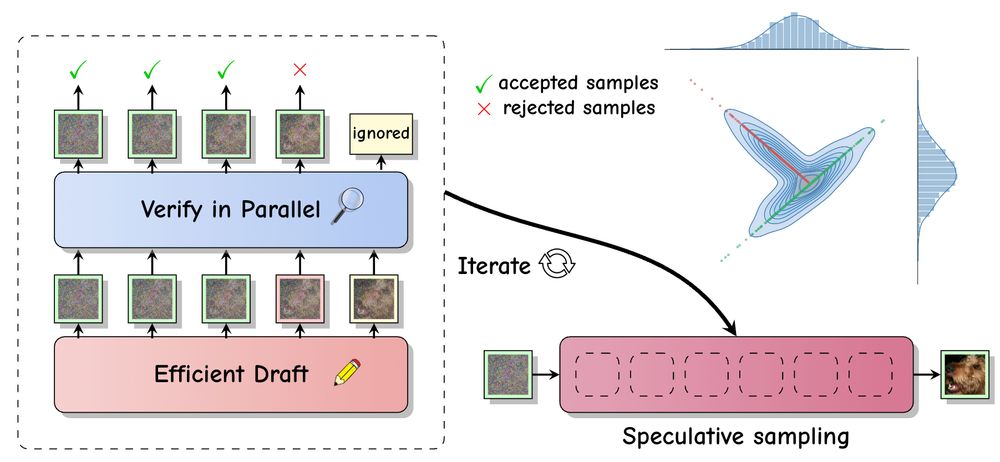
Speculative sampling accelerates inference in LLMs by drafting future tokens which are verified in parallel. With @vdebortoli.bsky.social , A. Galashov & @arthurgretton.bsky.social , we extend this approach to (continuous-space) diffusion models: arxiv.org/abs/2501.05370
10.01.2025 16:30 — 👍 45 🔁 10 💬 0 📌 0i couldn’t have say it better myself !
06.12.2024 16:09 — 👍 1 🔁 0 💬 0 📌 0The idea that one needs to know a lot of advanced math to start doing research in ML seems so wrong to me. Instead of reading books for weeks and forgetting most of them a year later, I think it's much better to try do things, see what knowledge gaps prevent you from doing them, and only then read.
06.12.2024 14:26 — 👍 9 🔁 2 💬 4 📌 0This equivalence between LLMs and Markov chains seems useless, but it isn't! Among the contributions, the paper highlights bounds established thanks to this equivalence, and verifies the influence of bound terms on recents LLMs !
I invite you to take a look at the other contributions of the paper 🙂
This number is huge, but **finite**! Working with markov chains in a finite state space really gives non-trivial mathematical insights (existence and uniqueness of a stationary distribution for example...).
04.12.2024 09:41 — 👍 1 🔁 0 💬 1 📌 0
This seems like… what we started with, no? arxiv.org/abs/2410.02724
03.12.2024 12:19 — 👍 167 🔁 9 💬 16 📌 1
🚨So, you want to predict your model's performance at test time?🚨
💡Our NeurIPS 2024 paper proposes 𝐌𝐚𝐍𝐨, a training-free and SOTA approach!
📑 arxiv.org/pdf/2405.18979
🖥️https://github.com/Renchunzi-Xie/MaNo
1/🧵(A surprise at the end!)
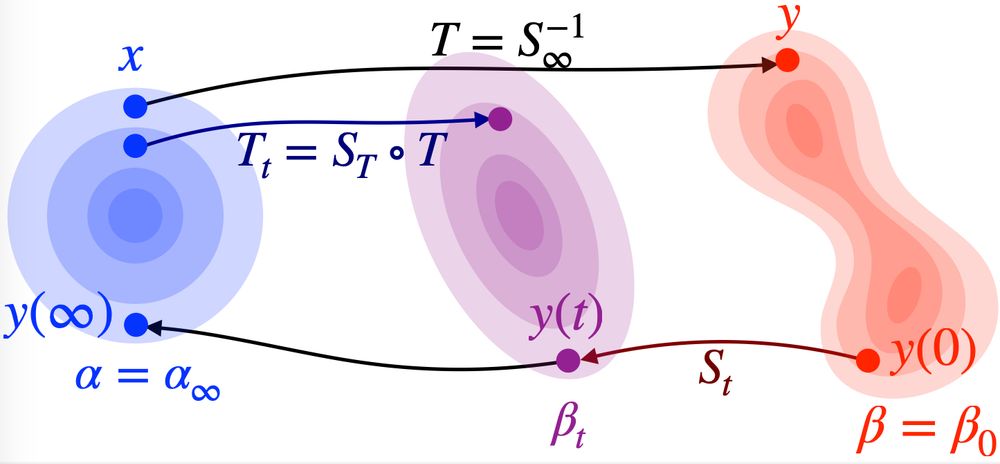
I wrote a summary of the main ingredients of the neat proof by Hugo Lavenant that diffusion models do not generally define optimal transport. github.com/mathematical...
30.11.2024 08:35 — 👍 240 🔁 45 💬 6 📌 5For more details, check out these papers:
👉 arxiv.org/pdf/2402.00795 — Introduces this method (to the best of my knowledge).
👉 arxiv.org/pdf/2410.02724 — Provides theoretical results and empirical validation on LLMs.

💡For a Markov chain with d states, the LLM-based method achieves an error rate of O(log(d)/N).
The frequentist approach, which is minimax optimal, achieves O(d/N). (see Wolfer et al., 2019, arxiv.org/pdf/1902.00080).
This makes it particularly efficient for MC with a large number of states! 🌟


‼️What’s even better is that you can derive bounds on the estimation error based on the number of samples N provided and specific properties of the Markov chain.
Tested and validated on recent LLMs!
🚀 Did you know you can use the in-context learning abilities of an LLM to estimate the transition probabilities of a Markov chains?
The results are pretty exciting ! 😄


















