
Overtrained Language Models Are Harder to Fine-Tune
Large language models are pre-trained on ever-growing token budgets under the assumption that better pre-training performance translates to improved downstream models. In this work, we challenge this ...
We also have so many other interesting details in the paper that have entirely changed the way I think about pre-training!
And thanks to my collaborators!
Sachin Goyal
Kaiyue Wen
Tanishq Kumar
@xiangyue96.bsky.social
@sadhika.bsky.social
@gneubig.bsky.social
@adtraghunathan.bsky.social
10/10
26.03.2025 18:35 — 👍 15 🔁 4 💬 1 📌 1
For the theorists in the room: we dive deeper into why this happens using a linear transfer learning setup, revealing that incremental learning leads to catastrophic overtraining.
9/10
26.03.2025 18:35 — 👍 1 🔁 0 💬 1 📌 0

Fine-tuning behaves similarly: using a fixed learning rate across different pre-training checkpoints, we see eventual degradation in both task performance and web-data perplexity. This often holds even after hyperparameter tuning. Overtraining = worse fine-tuning outcomes!
8/10
26.03.2025 18:35 — 👍 1 🔁 0 💬 1 📌 0

👉 Early in training: Models have low sensitivity & the base model improves quickly; performance improves 📈
👉 Late in training: Models become highly sensitive & the base model improves slowly; performance degrades! 📉
7/10
26.03.2025 18:35 — 👍 1 🔁 0 💬 1 📌 0
What's happening? Beyond Gaussian perturbations, extended pre-training increases model sensitivity to all types of parameter updates 👇
6/10
26.03.2025 18:35 — 👍 1 🔁 0 💬 1 📌 0

🔹 Early checkpoints: Robust to parameter changes.
🔸 Later checkpoints: Highly sensitive, leading to worse performance after perturbation! (Left plot: sensitivity increases over training, Right plot: final performance eventually degrades.)
5/10
26.03.2025 18:35 — 👍 1 🔁 1 💬 1 📌 0
Let’s step back and consider a simpler setting: we train our own 30M parameter models and test how Gaussian noise affects model parameters at different pre-training stages👇
4/10
26.03.2025 18:35 — 👍 0 🔁 0 💬 1 📌 0

Example: OLMo-1B trained on 3T tokens performs over 2% *worse* after instruction tuning than its 2.3T-token version—even though it saw 30% more data! We see similar observations for many other post-training setups.
Why does extended pre-training hurt fine-tuning performance? 🤔
3/10
26.03.2025 18:35 — 👍 0 🔁 0 💬 1 📌 0
The latest language models are pre-trained on more and more tokens while holding the number of model parameters fixed—and this trend isn't slowing down!
➡️ Better base models? Yes.
➡️ Better starting point for post-training? Let’s check!
2/10
26.03.2025 18:35 — 👍 0 🔁 0 💬 1 📌 0
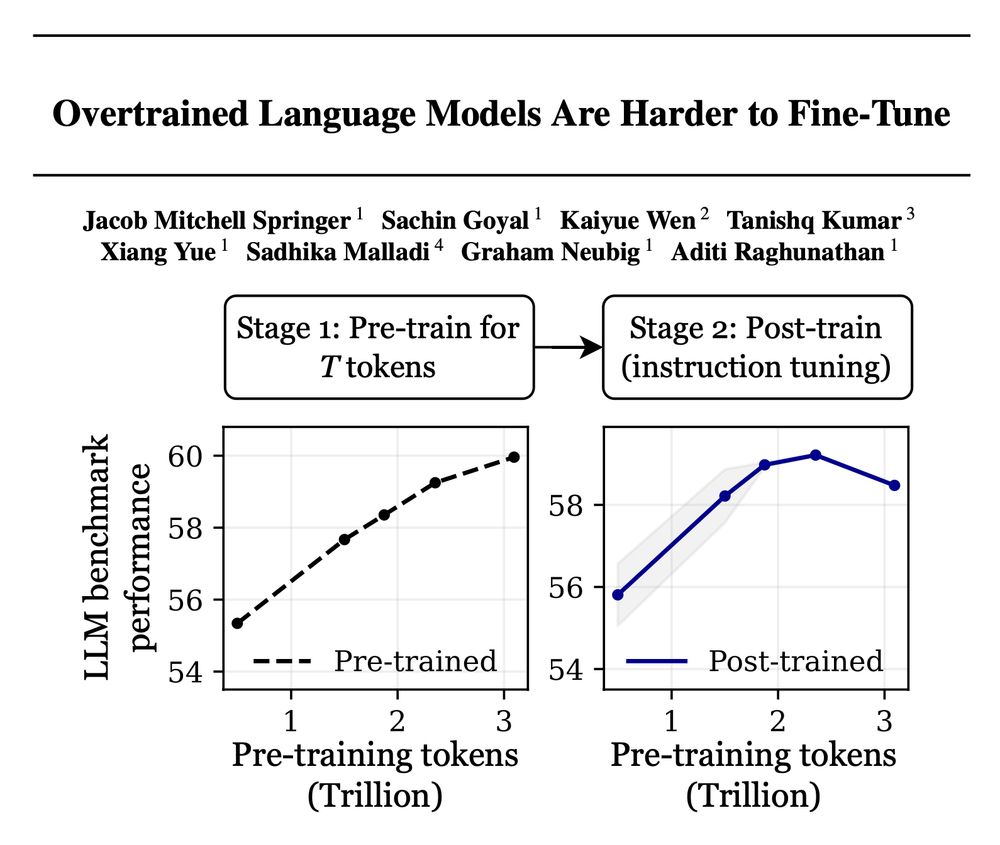
Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵👇
arxiv.org/abs/2503.19206
1/10
26.03.2025 18:35 — 👍 33 🔁 14 💬 1 📌 1
Machine Learning | Stein Fellow @ Stanford Stats (current) | Assistant Prof @ CMU (incoming) | PhD @ MIT (prev)
https://andrewilyas.com
Associate professor at CMU, studying natural language processing and machine learning. Co-founder All Hands AI
Postdoc @LTIatCMU. PhD from Ohio State @osunlp. Author of MMMU, MAmmoTH. Training & evaluating foundation models. Previously @MSFTResearch. Opinions are my own.
PhD student @ Carnegie Mellon University
I design tools and processes to support principled evaluation of AI systems.
lukeguerdan.com
The world's leading venue for collaborative research in theoretical computer science. Follow us at http://YouTube.com/SimonsInstitute.
Associate Professor at Princeton
Machine Learning Researcher
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
researching AI [evaluation, governance, accountability]
CS Ph.D. at CMU. Building Copilot Arena. Editor at http://blog.ml.cmu.edu
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.
Mathematician, writer, Cornell professor. All cards on the table, face up, all the time. www.stevenstrogatz.com
UC Berkeley/BAIR, AI2 || Prev: UWNLP, Meta/FAIR || sewonmin.com
VP of Research, GenAI @ Meta (Multimodal LLMs, AI Agents), UPMC Professor of Computer Science at CMU, ex-Director of AI research at @Apple, co-founder Perceptual Machines (acquired by Apple)
PhD student at @cmurobotics.bsky.social working on efficient algorithms for interactive learning (e.g. imitation / RL / RLHF). no model is an island. prefers email. https://gokul.dev/. on the job market!
Ph.D. Student at Carnegie Mellon,
Student Research at Google
Formerly Applied Science Intern Amazon, Undergrad at Delhi Technological University
📈 Foundation Models for Structured Data (Time Series, Tabular), applications in healthcare.
PhD student @CMU / Curiosity&Love / Dynamics to ASI
PhD student in machine learning @ CMU




















