We therefore advocate for caution when making or evaluating claims about LLM reasoning and beyond with GRPO and PPO, ideally using algorithms like RLoo or REBEL instead. Check out our blog post for links to our code and W&B logs if you'd like to reproduce our experiments.
15.07.2025 17:46 — 👍 1 🔁 0 💬 0 📌 0
While this worked out for the better on some seeds, it doesn't have to in general. After all, an algorithm that behaves unexpectedly *well* in one setting can perform unexpectedly *poorly* in another, perhaps more important, setting.
15.07.2025 17:46 — 👍 1 🔁 0 💬 1 📌 0
We see similar results on a didactic bandit problem -- i.e. a problem that has nothing to do with LLMs or reasoning! This implies that PPO / GRPO are fundamentally *not* following the true policy gradient.
15.07.2025 17:46 — 👍 1 🔁 0 💬 1 📌 0
We find that RLoo (an unbiased estimate of the vanilla PG) and REBEL (a regression-based approximation of online mirror descent) preserve performance as expected. In contrast, algorithms like PPO / GRPO that include heuristics (e.g. clipping) show a marked and unexpected change in performance.
15.07.2025 17:46 — 👍 1 🔁 0 💬 1 📌 0
So, with a truly random reward function, all policies look equally good. Thus, the *true* policy gradient is zero, as the initial policy is optimal by construction. So, we'd expect performance to flatline. We use random rewards as a *diagnostic task* to compare different RL algs.
15.07.2025 17:46 — 👍 1 🔁 0 💬 1 📌 0
Lead by Owen Oertell & Wenhao Zhan, joint w/ Steven Wu, Kiante Brantley, Jason Lee, and Wen Sun. If a project has got Wen, Owen, Wenhao, and Qwen on it, you know it's gotta be good 😛.
15.07.2025 17:46 — 👍 1 🔁 0 💬 1 📌 0

Heuristics Considered Harmful: RL With Random Rewards Should Not Make LLMs Reason | Notion
Owen Oertell*, Wenhao Zhao*, Gokul Swamy, Zhiwei Steven Wu, Kiante Brantley, Jason Lee, Wen Sun
Recent work has seemed somewhat magical: how can RL with *random* rewards make LLMs reason? We pull back the curtain on these claims and find out this unexpected behavior hinges on the inclusion of certain *heuristics* in the RL algorithm. Our blog post: tinyurl.com/heuristics-c...
15.07.2025 17:46 — 👍 6 🔁 2 💬 1 📌 0
very nice lectures, watch them from time to time
20.06.2025 06:07 — 👍 6 🔁 1 💬 0 📌 0
Want to learn about online learning, game solving, RL, imitation learning with applications to robotics, and RLHF with applications to language modeling? Check out this course! 👍
20.06.2025 13:11 — 👍 6 🔁 1 💬 0 📌 0
While I can't promise everything will be crystal-clear after going though the lectures (especially because of my handwriting :p), I hope that if nothing else, you can tell how beautiful we all find these ideas. If that feeling comes across, I'll feel like I have succeeded! :)
20.06.2025 03:53 — 👍 3 🔁 0 💬 1 📌 0
The second was being able to teach this course with my amazing advisors, Drew Bagnell and Steven Wu -- the folks I learned all of this stuff from. Fun fact: because of parking fees, Drew actually *paid* to lecture. And I'm always grateful to ZSW for pushing me out of the nest.
20.06.2025 03:53 — 👍 3 🔁 0 💬 1 📌 0
Two other things made this course particularly special. The first was the students and their *incredible* questions -- there were so many times where I was like wow, it took me *YEARS* before I realized that was the right question to be asking.
20.06.2025 03:53 — 👍 4 🔁 0 💬 1 📌 0
YouTube video by Gokul Swamy
Algorithmic Foundations of Interactive Learning SP25: Lecture 17
We also had wonderful guest lectures from Yuda Song
on hybrid RL (youtu.be/1B2XGXQ2hfA), Sanjiban Choudhury on scaling imitation (youtu.be/KnXSeTuCgFI), and Wen Sun on RLHF algorithms (youtu.be/qdkBZJywi_4).
20.06.2025 03:53 — 👍 6 🔁 0 💬 1 📌 0
YouTube video by Gokul Swamy
Algorithmic Foundations of Interactive Learning SP25: Lecture 19
My favorite lectures to give were on the value of interaction in imitation / RLHF! youtu.be/uESAXg-CXFs, youtu.be/N8-Nh_iTmps, youtu.be/qHvB30J5gyo, youtu.be/ZzFjoH47GIg. It took 5 years, but I finally have an answer at least I find compelling :p.
20.06.2025 03:53 — 👍 6 🔁 0 💬 1 📌 0
To do so, we worked backwards from things like ChatGPT and RMA and "backed out" a "dependency graph". We then did a "forward pass" over the semester, going from online learning, to game solving, to core RL, to imitation learning / robot learning, to RLHF / LLM fine-tuning.
20.06.2025 03:53 — 👍 5 🔁 0 💬 1 📌 0
I think in a field as fast-paced as machine learning, a good course gives students a conceptual framework for understanding new developments quickly + what is actually "new" vs. the classical algorithms. We also wanted to explain *when* scale isn't "all you need."
20.06.2025 03:53 — 👍 6 🔁 0 💬 1 📌 0
Home
Website for AFIL course.
You can access all the content here:
Course Website: interactive-learning-algos.github.io
Lecture Playlist: youtube.com/playlist?lis...
Scribe Notes "Book": interactive-learning-algos.github.io/assets/pdfs/....
Homeworks / class competition material are also public!
20.06.2025 03:53 — 👍 14 🔁 1 💬 1 📌 0
It was a dream come true to teach the course I wish existed at the start of my PhD. We built up the algorithmic foundations of modern-day RL, imitation learning, and RLHF, going deeper than the usual "grab bag of tricks". All 25 lectures + 150 pages of notes are now public!
20.06.2025 03:53 — 👍 47 🔁 10 💬 3 📌 2
Shortcut models enable scaling offline RL, both at train-time at test-time! We beat so many other algorithms on so many tasks we had to stick most of the results in the appendix 😅. Very proud of @nico-espinosa-dice.bsky.social for spearheading this project, check out his thread!
12.06.2025 23:14 — 👍 1 🔁 1 💬 0 📌 0
Boston friends: I'll be in the Cambridge area for the next few days, shoot me a message if you'd like to catch up :).
27.04.2025 21:28 — 👍 2 🔁 0 💬 0 📌 0

I won't be at #ICLR2025 myself this time around but please go talk to lead authors Nico, Zhaolin, and Runzhe about their bleeding-edge algorithms for imitation learning and RLHF!
22.04.2025 14:05 — 👍 4 🔁 0 💬 0 📌 0
I am also incredibly grateful to @nico-espinosa-dice.bsky.social for sticking with me through the many iterations it took us to figure out what the "right questions" were to ask here. Nico basically rewrote the whole paper / did a new set of experiments *after* it had been accepted 😱. [16/n]
07.04.2025 19:03 — 👍 1 🔁 0 💬 1 📌 0
There's a bunch of other fancy theory in the paper but at the highest level, one reason I am proud of this paper is that I finally understand how we can close embodiment / sensory gaps without needing a queryable expert/ global RL, which should making scaling IL easier. [15/n]
07.04.2025 19:03 — 👍 0 🔁 0 💬 1 📌 0
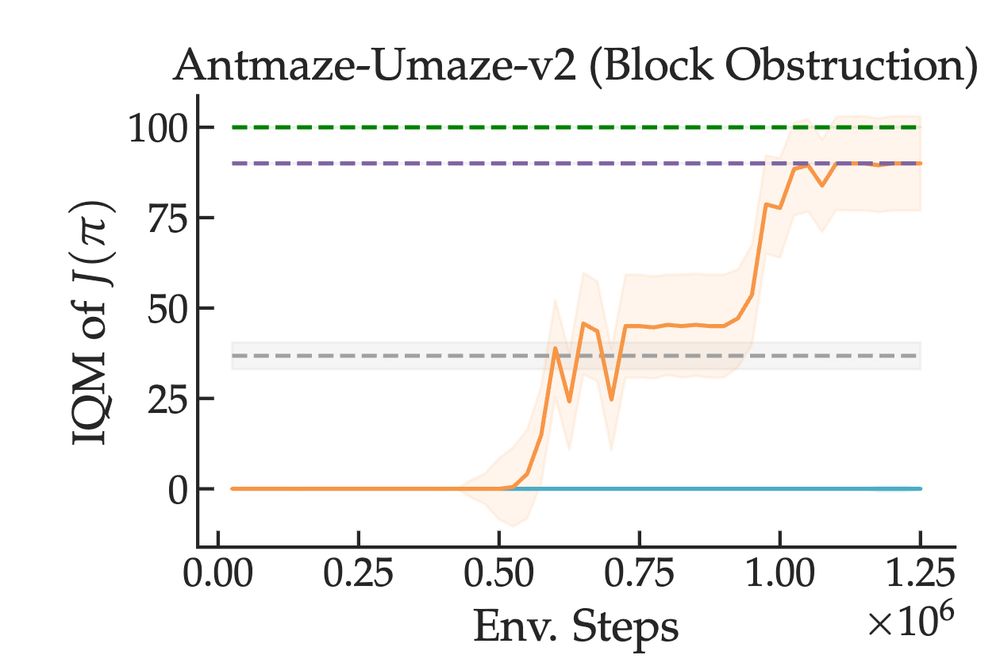
We then show that this sort of suboptimal, offline data can help significantly with speeding up local search on challenging maze-based exploration problems where the learner needs to act meaningfully different from the expert (our method in orange). [14/n]
07.04.2025 19:03 — 👍 0 🔁 0 💬 1 📌 0

Among our contributions, we give a precise (and rather aesthetically pleasingly typeset if I don't say so myself) theoretical condition under which the use of suboptimal data to help with figuring out *where* to locally search from is helps with policy performance! [13/n]
07.04.2025 19:03 — 👍 0 🔁 0 💬 1 📌 0
Intuitively, we likely want to explore from a "wider" set of states that covers policies we can actually choose, not just the unrealizable "tightrope-walking" expert. In practice, we can use suboptimal / failure / play data to "broaden" where we perform local search. [12/n]
07.04.2025 19:03 — 👍 0 🔁 0 💬 1 📌 0
Second, we may be unable to "follow-through" the same way the expert does (e.g. insert a peg even when its close to the hole due to no haptic feedback). Together, this begs the question of *where* we should actually perform local search from. [11/n]
07.04.2025 19:03 — 👍 0 🔁 0 💬 1 📌 0
First, we might be unable to actually reach the expert states in the first place (e.g. a humanoid might not be able to do the first half of a backflip). [10/n]
07.04.2025 19:03 — 👍 0 🔁 0 💬 1 📌 0
However, in the misspecified setting where we can't imitate the expert in the first place, it's much less clear that locally exploring from *expert* states on "tightrope" like problems is the right thing to do. More explicitly, this is basically for two reasons. [9/n]
07.04.2025 19:03 — 👍 0 🔁 0 💬 1 📌 0
PhD @ltiatcmu.bsky.social
previously @eleutherai.bsky.social
🌐 lintang.sutawika.com
Co-founder & Chief Scientist at Yutori. Prev: Senior Director leading FAIR Embodied AI at Meta, and Professor at Georgia Tech.
Assistant Prof. at Georgia Tech | NVIDIA AI | Making robots smarter
Associate Professor at #MIT, SPARK Lab Director, Roboticist, interested in how machines see and understand the world
lucacarlone.mit.edu
Assistant Professor at University of Pennsylvania.
Robot Learning.
https://www.seas.upenn.edu/~dineshj/
AI Pioneer, AI+Science, Professor at Caltech, Former Senior Director of AI at NVIDIA, Former Principal Scientist at AWS AI.
VP of Research, GenAI @ Meta (Multimodal LLMs, AI Agents), UPMC Professor of Computer Science at CMU, ex-Director of AI research at @Apple, co-founder Perceptual Machines (acquired by Apple)
Professor of Natural and Artificial Intelligence @Stanford. Safety and alignment @GoogleDeepMind.
Security and Privacy of Machine Learning at UofT, Vector Institute, and Google 🇨🇦🇫🇷🇪🇺 Co-Director of Canadian AI Safety Institute (CAISI) Research Program at CIFAR. Opinions mine
Asst. Prof. in Machine Learning at UofT. #LongCOVID patient.
https://www.cs.toronto.edu/~cmaddis/
Machine learning prof at U Toronto. Working on evals and AGI governance.
Assistant Professor at UC Berkeley
Postdoc at Berkeley AI Research. PhD from ETH Zurich.
Robotics, Artificial Intelligence, Humanoids, Tactile Sensing.
https://sferrazza.cc
Research at Google DeepMind. Ex-Physicist. Controllable World Simulators (GNNs, Structured World Models, Neural Assets). TLM Veo Capabilities (Ingredients & more).
📍 San Francisco, CA
OpenAI and MIT faculty (on leave)
Research Scientist at DeepMind. Opinions my own. Inventor of GANs. Lead author of http://www.deeplearningbook.org . Founding chairman of www.publichealthactionnetwork.org
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.
sampling reality | feeling the gradients























