
challenge!
21.12.2024 16:44 — 👍 22 🔁 3 💬 1 📌 0
@smithwinst0n.bsky.social
Graduate Student, ML, CV, Robotics
challenge!
21.12.2024 16:44 — 👍 22 🔁 3 💬 1 📌 0

Yesterday the hyped Genesis simulator released. But it's up to 10x slower than existing GPU sims, not 10-80x faster or 430,000x faster than realtime since they benchmark mostly static environments
blog post with corrected open source benchmarks & details: stoneztao.substack.com/p/the-new-hy...
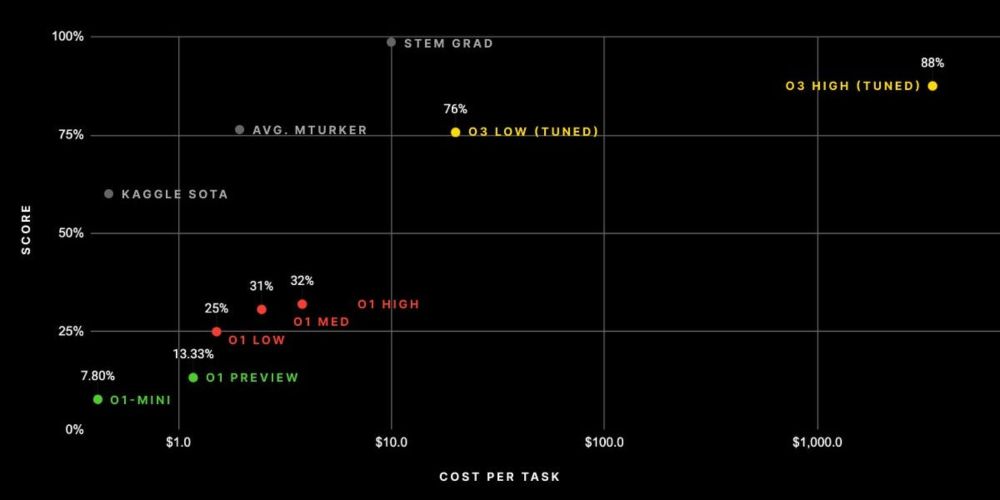
Excellent post about the recent OpenAI o3 results on ARC (& other benchmarks). I don't know how @natolambert.bsky.social manages to write these so quickly! I highly recommend his newsletter.
www.interconnects.ai/p/openais-o3...
I am (more slowly) writing my own take on all this, coming soon.
Waymo's "superhuman" crash rate is an indicator that the frequent argument that we need human-level intelligence to solve hard robotics tasks is seemingly wrong, we just need time and elbow grease
20.12.2024 01:44 — 👍 52 🔁 4 💬 8 📌 0
Just gave a talk on "Grounding LLMs in Code Execution" at the NeurIPS Hacker-Cup AI Competition, here are the slides docs.google.com/presentation...
14.12.2024 19:10 — 👍 22 🔁 4 💬 1 📌 0Interpreting CLIP: Insights on the Robustness to ImageNet Distribution Shifts
Jonathan Crabbé, Pau Rodriguez, Vaishaal Shankar, Luca Zappella, Arno Blaas
Action editor: Pavel Izmailov
https://openreview.net/forum?id=1SCptTFtmV
#imagenet #robust #robustness




Align3R: Aligned Monocular Depth Estimation for Dynamic Videos
Jiahao Lu et 10 al.
tl;dr: DepthPro for all frames -> inject depth ControlNet-style into Dust3r decoder, finetune on dynamic scenes. Long videos process in coarse-to-fine
arxiv.org/abs/2412.03079
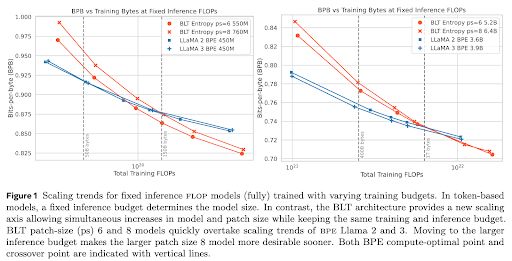
🚀 Introducing the Byte Latent Transformer (BLT) – A LLM architecture that scales better than Llama 3 using patches instead of tokens 🤯
Paper 📄 dl.fbaipublicfiles.com/blt/BLT__Pat...
Code 🛠️ github.com/facebookrese...
One of the physics of llm papers studied that and found you need a certain amour of repetitions of a factoid before it’s memorized. Repetition can be either multi epochs or just the same fact in another document. Number of needed repeats is also related to model size.
13.12.2024 16:27 — 👍 11 🔁 2 💬 2 📌 0Our paper PRISM alignment won a best paper award at #neurips2024!
All credits to @hannahrosekirk.bsky.social A.Whitefield, P.Röttger, A.M.Bean, K.Margatina, R.Mosquera-Gomez, J.Ciro, @maxbartolo.bsky.social H.He, B.Vidgen, S.Hale
Catch Hannah tomorrow at neurips.cc/virtual/2024/poster/97804

Welcome to Gemini 2.0 era!
I am thrilled about ✨ Gemini 2.0 Flash as it allowed us to build the next generation of Code Agents experience: developers.googleblog.com/en/the-next-...
Very interesting approach, added to my read list!
11.12.2024 08:50 — 👍 0 🔁 0 💬 0 📌 0🌍 Guessing where an image was taken is a hard, and often ambiguous problem. Introducing diffusion-based geolocation—we predict global locations by refining random guesses into trajectories across the Earth's surface!
🗺️ Paper, code, and demo: nicolas-dufour.github.io/plonk

Gemini 2.0 is out, and there's a ton of interesting stuff about it. From my testing it looks like Gemini 2.0 Flash may be the best currently available multi-modal model - I upgraded my LLM plugin to support that here: github.com/simonw/llm-g...
Gemini 2.0 announcement: blog.google/technology/g...

Can we enhance the performance of T2I models without any fine-tuning?
We show that with our ReNO, Reward-based Noise Optimization, one-step models consistently surpass the performance of all current open-source Text-to-Image models within the computational budget of 20-50 sec!
#NeurIPS2024
The best paper awardee from NeuRIPS 2024 has been apparently accused of misconduct by his ByteDance peers. This raises many questions certainly:
var-integrity-report.github.io

1/ 🎉 Excited to share our work, "Composed Image Retrieval for Training-Free Domain Conversion", accepted at WACV 2025! 🚀
05.12.2024 12:58 — 👍 16 🔁 5 💬 3 📌 1Now on ArXiv
ShowHowTo: Generating Scene-Conditioned Step-by-Step Visual Instructions
arxiv.org/abs/2412.01987
soczech.github.io/showhowto/
Given one real image &variable sequence of text instructions, ShowHowTo generates a multi-step sequence of images *conditioned on the scene in the REAL image*
🧵
So, now that our move to OpenAI became public, @kolesnikov.ch @xzhai.bsky.social and I are drowning in notifications. I read everything, but may not reply.
Excited about this new journey! 🚀
Quick FAQ thread...
Ok, it is yesterdays news already, but good night sleep is important.
After 7 amazing years at Google Brain/DM, I am joining OpenAI. Together with @xzhai.bsky.social and @giffmana.ai, we will establish OpenAI Zurich office. Proud of our past work and looking forward to the future.

Optimal transport, convolution, and averaging define interpolations between probability distributions. One can find vector fields advecting particles that match these interpolations. They are the Benamou-Brenier, flow-matching, and Dacorogna-Moser fields.
04.12.2024 13:55 — 👍 77 🔁 11 💬 1 📌 0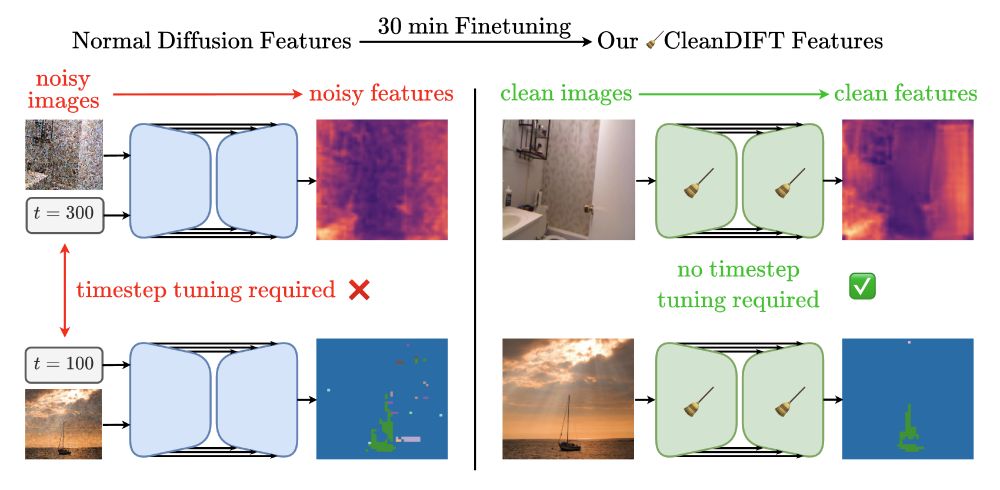
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
In arxiv.org/abs/2303.00848, @dpkingma.bsky.social and @ruiqigao.bsky.social had suggested that noise augmentation could be used to make other likelihood-based models optimise perceptually weighted losses, like diffusion models do. So cool to see this working well in practice!
02.12.2024 18:36 — 👍 52 🔁 11 💬 0 📌 0
A common question nowadays: Which is better, diffusion or flow matching? 🤔
Our answer: They’re two sides of the same coin. We wrote a blog post to show how diffusion models and Gaussian flow matching are equivalent. That’s great: It means you can use them interchangeably.
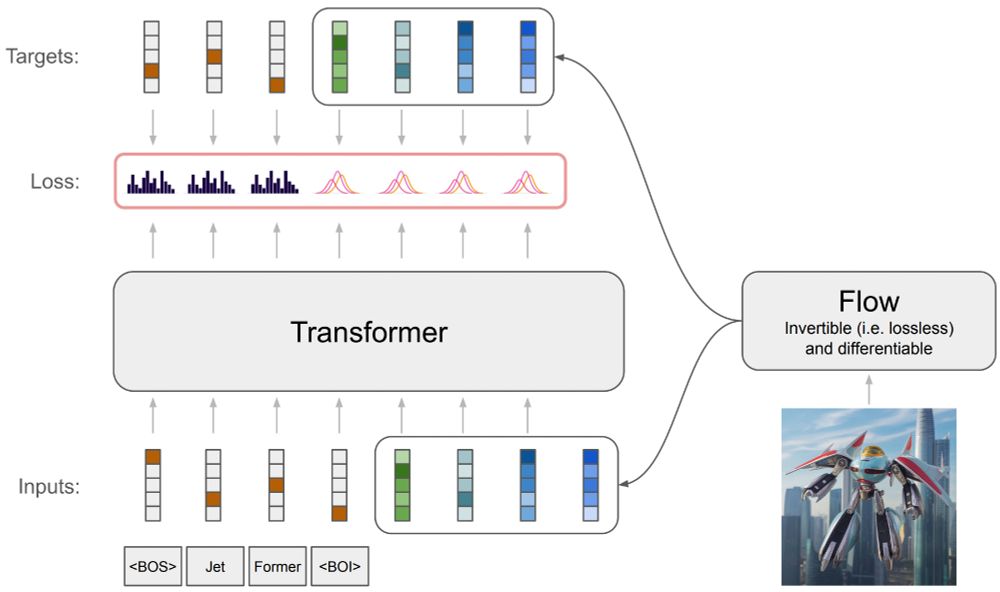
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
Meanwhile @deep-mind.bsky.social is a fake account, was reported a week ago.. and is still up. 🙄
30.11.2024 20:52 — 👍 17 🔁 2 💬 2 📌 0Can someone explain to me BlueSky’s business model. This will prolly make it clear what all the data policies amount to.
29.11.2024 18:57 — 👍 23 🔁 1 💬 5 📌 0I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!

Second Stage xkcd.com/3018
29.11.2024 13:39 — 👍 9720 🔁 718 💬 94 📌 46




















