Haven’t tried this. My guess would be that you need the same fact to be repeated across multiple batches (ie training steps) for the effect to be visible.
04.04.2025 19:13 — 👍 1 🔁 0 💬 0 📌 0
Our work suggests practical LLM training strategies:
1. use synthetic data early as plateau phase data isn't retained anyway
2. implement dynamic data schedulers that use low diversity during plateaus and high diversity afterward (which is similar to how we learn as infants!)
03.04.2025 12:20 — 👍 5 🔁 0 💬 1 📌 0

Hallucinations emerge with knowledge. As models learn facts about seen individuals, they also make overconfident predictions about unseen ones.
On top of that, fine-tuning struggles to add new knowledge: existing memories are quickly corrupted when learning new ones.
03.04.2025 12:20 — 👍 3 🔁 0 💬 1 📌 0
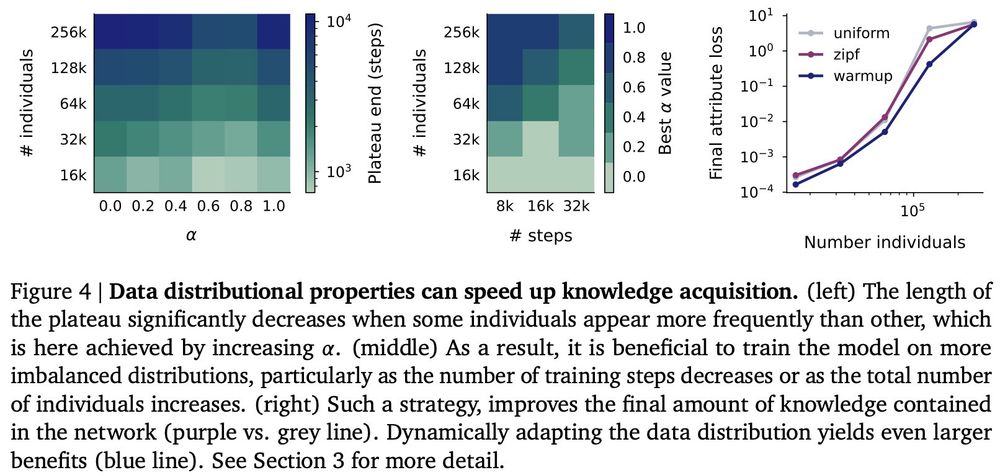
The training data distribution has a massive impact on learning. Imbalanced distributions (some individuals appearing more frequently) accelerate the plateau phase.
This suggests exciting new data scheduling strategies for training - we show that a simple warmup works well!
03.04.2025 12:20 — 👍 4 🔁 3 💬 2 📌 0

During that plateau, something crucial happens: the model builds the attention-based circuits that enable recall.
This is when the model learns how to recall facts, and it only remembers specific facts afterward!
03.04.2025 12:20 — 👍 3 🔁 0 💬 1 📌 0

We studied how models learn on a synthetic biography task and found three key phases in knowledge acquisition:
1. Models initially learn generic statistics
2. Performance plateaus while attention-based circuits form
3. Knowledge emerges as models learn individual-specific facts
03.04.2025 12:20 — 👍 5 🔁 2 💬 1 📌 0

Large language models store vast amounts of knowledge, but how exactly do they learn it?
Excited to share my Google DeepMind internship results, which reveal the fascinating dynamics behind factual knowledge acquisition in LLMs!
03.04.2025 12:20 — 👍 27 🔁 3 💬 1 📌 2
J'avais en effet, en toute sincérité d'esprit, pris l'engagement de le rendre à son état primitif de fils du soleil.
PhD student at ETH Zurich & MPI-IS in NLP & ML
Language, Reasoning, and Cognition
https://opedal.github.io
a mediocre combination of a mediocre AI scientist, a mediocre physicist, a mediocre chemist, a mediocre manager and a mediocre professor.
see more at https://kyunghyuncho.me/
Distinguished Scientist at Google. Computational Imaging, Machine Learning, and Vision. Posts are personal opinions. May change or disappear over time.
http://milanfar.org
Chief Scientist at the UK AI Security Institute (AISI). Previously DeepMind, OpenAI, Google Brain, etc.
Professor, Santa Fe Institute. Research on AI, cognitive science, and complex systems.
Website: https://melaniemitchell.me
Substack: https://aiguide.substack.com/
Director, Princeton Language and Intelligence. Professor of CS.
🧙🏻♀️ scientist at Meta NYC | http://bamos.github.io
Chief AI Scientist at Databricks. Founding team at MosaicML. MIT/Princeton alum. Lottery ticket enthusiast. Working on data intelligence.
Recently a principal scientist at Google DeepMind. Joining Anthropic. Most (in)famous for inventing diffusion models. AI + physics + neuroscience + dynamical systems.
Research Scientist at DeepMind. Opinions my own. Inventor of GANs. Lead author of http://www.deeplearningbook.org . Founding chairman of www.publichealthactionnetwork.org
Interested in cognition and artificial intelligence. Research Scientist at Google DeepMind. Previously cognitive science at Stanford. Posts are mine.
lampinen.github.io
Senior Research Fellow @ ucl.ac.uk/gatsby & sainsburywellcome.org
{learning, representations, structure} in 🧠💭🤖
my work 🤓: eringrant.github.io
not active: sigmoid.social/@eringrant @eringrant@sigmoid.social, twitter.com/ermgrant @ermgrant
AI @ OpenAI, Tesla, Stanford
I lead Cohere For AI. Formerly Research
Google Brain. ML Efficiency, LLMs,
@trustworthy_ml.
So far I have not found the science, but the numbers keep on circling me.
Views my own, unfortunately.
Professor, Programmer in NYC.
Cornell, Hugging Face 🤗
Research Scientist at Google DeepMind. Working on Gemini reasoning models.
PhD from UofT and Vector Institute
www.paulvicol.com
I do SciML + open source!
🧪 ML+proteins @ http://Cradle.bio
📚 Neural ODEs: http://arxiv.org/abs/2202.02435
🤖 JAX ecosystem: http://github.com/patrick-kidger
🧑💻 Prev. Google, Oxford
📍 Zürich, Switzerland
Group Leader in Tübingen, Germany
I’m 🇫🇷 and I work on RL and lifelong learning. Mostly posting on ML related topics.





















