
illustration of text
⚠️ Leaderboard Illusion: "We find that undisclosed private testing practices benefit a handful of providers who are able to test multiple variants before public release & retract scores if desired..the ability of these providers to choose the best score leads to biased Arena scores"
Paper out now!🔻
05.05.2025 20:08 — 👍 9 🔁 2 💬 1 📌 0

We tried very hard to get this right, and have spent the last 5 months working carefully to ensure rigor.
If you made it this far, take a look at the full 68 pages: arxiv.org/abs/2504.20879
Any feedback or corrections are of course very welcome.
30.04.2025 14:58 — 👍 14 🔁 0 💬 1 📌 1
Very proud of this work that we led by
Shivalika Singh and @mziizm.bsky.social with Yiyang Nan, Alex Wang, Daniel D'Souza, @sayash.bsky.social, Ahmet Üstün, Sanmi Koyejo, Yuntian Deng, @shaynelongpre.bsky.social
@nlpnoah.bsky.social @beyzaermis.bsky.social
30.04.2025 14:57 — 👍 5 🔁 0 💬 1 📌 0

This was an uncomfortable paper to work on because it asks us to look in the mirror as a community.
As scientists, we must do better.
As a community, I hope we can demand better. We make very clear the 5 changes needed.
30.04.2025 14:55 — 👍 6 🔁 1 💬 1 📌 0

Overall, our work suggests that engagement from a handful of providers and preferential policies from
Arena towards the same small group have created conditions to overfit to Arena-specific dynamics rather than general model quality.
30.04.2025 14:55 — 👍 2 🔁 0 💬 1 📌 0

We show that access to Chatbot Arena data yields substantial benefits.
While using Arena-style data in training boosts win rates by 112%, this improvement doesn't transfer to tasks like MMLU, indicating overfitting to Arena's quirks rather than general performance gains.
30.04.2025 14:55 — 👍 3 🔁 0 💬 1 📌 0

These data differences stem from some key policies that benefit a handful of providers:
1) proprietary models sampled at higher rates to appear in battles 📶
2) open-weights + open-source models removed from Arena more often 🚮
3) How many private variants 🔍
30.04.2025 14:55 — 👍 1 🔁 0 💬 1 📌 0

We also observe large differences in Arena Data Access
Chatbot Arena is a open community resource that provides free feedback but 61.3% of all data goes to proprietary model providers.
30.04.2025 14:55 — 👍 2 🔁 0 💬 1 📌 0
We even do real world private testing using Aya Vision models to show the gains you can expect.
Even when you test identical checkpoints we see gains. This is the most conservative case where quality is identical.
30.04.2025 14:55 — 👍 3 🔁 0 💬 1 📌 0

There is no reasonable scientific justification for this practice.
Being able to choose the best score to disclose enables systematic gaming of Arena score.
This advantage increases with number of variants and if all other providers don’t know they can also private test.
30.04.2025 14:55 — 👍 7 🔁 1 💬 1 📌 0

There is an unspoken policy of hidden testing that benefits a small subset of providers.
Providers can choose what score to disclose and retract all others.
At an extreme, we see testing of up to 27 models in lead up to releases.
30.04.2025 14:55 — 👍 4 🔁 0 💬 1 📌 0

We spent 5 months analyzing 2.8M battles on the Arena, covering 238 models across 43 providers.
We show that preferential policies engaged in by a handful of providers lead to overfitting to Arena-specific metrics rather than genuine AI progress.
30.04.2025 14:55 — 👍 4 🔁 0 💬 2 📌 0

It is critical for scientific integrity that we trust our measure of progress.
The @lmarena.bsky.social has become the go-to evaluation for AI progress.
Our release today demonstrates the difficulty in maintaining fair evaluations on the Arena, despite best intentions.
30.04.2025 14:55 — 👍 42 🔁 9 💬 3 📌 4

1/ Science is only as strong as the benchmarks it relies on.
So how fair—and scientifically rigorous—is today’s most widely used evaluation benchmark?
We took a deep dive into Chatbot Arena to find out. 🧵
30.04.2025 12:53 — 👍 28 🔁 6 💬 1 📌 1
This has been a topic close to my heart for a long time.
We have an awesome lineup of speakers who have made deep contributions to open-source in ML, e.g. @sarahooker.bsky.social , @chrisrackauckas.bsky.social, Matt Johnson, Tri Dao, @stellaathena.bsky.social, Evan Shelhamer.
16.04.2025 20:42 — 👍 10 🔁 2 💬 0 📌 0
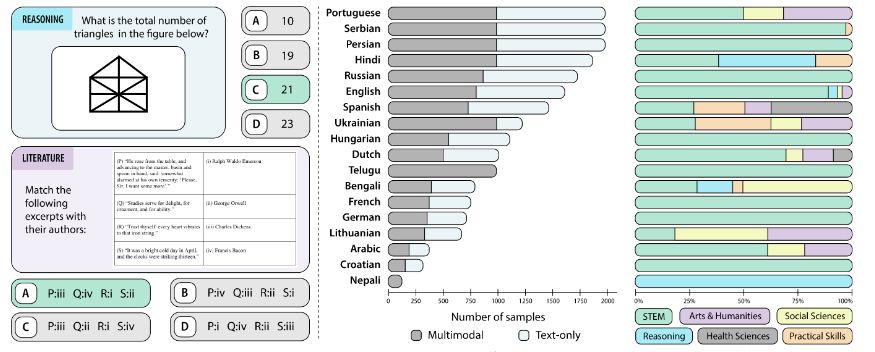
Today we are releasing Kaleidoscope 🎉
A comprehensive multimodal & multilingual benchmark for VLMs! It contains real questions from exams in different languages.
🌍 20,911 questions and 18 languages
📚 14 subjects (STEM → Humanities)
📸 55% multimodal questions
10.04.2025 10:31 — 👍 25 🔁 6 💬 1 📌 1

We're particularly proud to release Aya Vision 8B - it's compact 🐭 and efficient 🐎, outperforming models up to 11x its size 📈.
Releasing open weights helps to make breakthroughs in VLMs accessible to the research community.
05.03.2025 17:56 — 👍 14 🔁 4 💬 1 📌 0
Just 2 days after launch, Aya Vision is trending on
@hf.co 🔥🔥
We launched open-weights with the goal of making VLM breakthroughs accessible to the research community - so exciting to see such a positive response.
huggingface.co/CohereForAI/...
06.03.2025 17:10 — 👍 7 🔁 2 💬 0 📌 0
Love this post by @sarahooker.bsky.social on that other platform: "The first step of any meaningful pursuit is to severely underestimate its difficulty."
03.03.2025 19:51 — 👍 5 🔁 1 💬 0 📌 0
Introducing ✨ Aya Vision ✨ - an open-weights model to connect our world through language and vision
Aya Vision adds breakthrough multimodal capabilities to our state-of-the-art multilingual 8B and 32B models. 🌿
04.03.2025 14:01 — 👍 8 🔁 3 💬 1 📌 3
👀
27.02.2025 11:00 — 👍 7 🔁 1 💬 0 📌 0

An important topic in AI is the climate impacts of the energy-intensive computing hardware needed to train and deploy AI models ⚡
Our policy primer explores ways to move towards more sustainable AI. 🌱
📜 cohere.com/research/pap...
25.02.2025 17:42 — 👍 2 🔁 1 💬 0 📌 0

Does more compute equate with greater risk?⚡️What is our track record predicting what risks emerge with scale? 📈
In this work led by Sara Hooker, we seek to understand the viability of compute thresholds ⚖️ as a way to mitigate risk. 🦺
arxiv.org/abs/2407.05694
11.02.2025 15:11 — 👍 1 🔁 1 💬 0 📌 0

In this work, we ask "How does model merging stack up when optimizing language models for diverse multitask learning?" 📚🧩
📜https://arxiv.org/abs/2410.10801
18.02.2025 16:38 — 👍 5 🔁 1 💬 0 📌 0
Lol a worthy toxic trait
16.02.2025 22:18 — 👍 1 🔁 0 💬 1 📌 0

Aya Expanse, our open-weight 32B model, outperforms drastically larger models including Claude, Mistral Large 2, & Llama 405B on Scale's Private Multilingual Protocol.
We are proud to work on global AI that is efficient and accessible 🔥
22.01.2025 14:22 — 👍 6 🔁 3 💬 1 📌 0

Our paper is accepted to ICLR!
INCLUDE: Evaluating Multilingual LLMs with Regional Knowledge (arxiv.org/abs/2411.19799)
A benchmark of ~200k QA pairs across 44 languages, capturing real-world cultural nuances.
A collaborative effort led by @cohereforai.bsky.social, with contributors worldwide.
/1
23.01.2025 16:07 — 👍 11 🔁 4 💬 1 📌 0

In this cross-institutional work, we introduce technical governance for AI and 100+ 🔢 open technical problems 🔧.
We provide a taxonomy of open problem areas in TAIG organized by governance capacities and governance targets.
📜https://arxiv.org/pdf/2407.14981
12.02.2025 14:54 — 👍 2 🔁 2 💬 0 📌 0

The C4AI Research Grant program is proud to have supported a project focused on building LLM tools for teachers 🧑🏫
This project focused on adapting educational materials to students’ skill levels, ensuring more effective and responsible AI integration in classrooms.
13.02.2025 16:15 — 👍 4 🔁 1 💬 1 📌 0
Co-founder DrivenData. Celebrating a decade of data for good.
ML challenges | https://www.drivendata.org/
Data projects | https://drivendata.co/
Open source | https://github.com/pjbull
PhD @ MIT. Prev: Google Deepmind, Apple, Stanford. 🇨🇦 Interests: AI/ML/NLP, Data-centric AI, transparency & societal impact
PhD @ UniMelb
NLP, with a healthy dose of MT
Based in 🇮🇩, worked in 🇹🇱 🇵🇬 , from 🇫🇷
I make sure that OpenAI et al. aren't the only people who are able to study large scale AI systems.
Lead dev of SciML org, VP of Modeling and Simulation @JuliaHub, Director of Scientific Research @PumasAI, and Research Staff
@mit_csail. #julialang #sciml
Postdoctoral Research Scientist in Statistics at Columbia University
PhD fellow @coastalcph | MVA @ENS_ParisSaclay | Engineer
@uchile. 🤖🧠☕🍻🥐✈️🏃🏽🇨🇱🎸 🏊🏽♂️
Senior AI researcher at BSC. Random thinker at home.
Data/AI policy @adalovelaceinst.bsky.social
(Political) philosophy of tech @lsegovernment.bsky.social @lsepoltheory.bsky.social
Views my own 🔮✨
🏳️🌈🏳️⚧️
- Director @adalovelaceinst.bsky.social:ensuring data & AI work for ppl & society
- Stint in government - led #NationalDataStrategy; roles in Cabinet Office, ONS & MHCLG
- Charity roles inc. Samaritans Trustee; staff @ The RSA, Centrepoint, ParkinsonsUK
Scholar, author, policy advisor
alondranelson.com
Science, Technology, and Social Values Lab
https://www.ias.edu/stsv-lab
Head of ML & Society at Hugging Face 🤗
Co-founder and CEO at Hugging Face
Climate & AI Lead @HuggingFace, TED speaker, WiML board member, TIME AI 100 (She/her/Dr/🦋)
Philosopher/AI Ethicist at Univ of Edinburgh, co-Director @technomoralfutures.bsky.social and BRAID @braiduk.bsky.social, author of Technology and the Virtues (2016) and The AI Mirror (2024). Views my own. Humble servant to Carol and Puffin.
Assistant Prof of CS at the University of Waterloo, Faculty and Canada CIFAR AI Chair at the Vector Institute. Joining NYU Courant in September 2026. Co-EiC of TMLR. My group is The Salon. Privacy, robustness, machine learning.
http://www.gautamkamath.com
So far I have not found the science, but the numbers keep on circling me.
Views my own, unfortunately.
Associate professor at IT University of Copenhagen: NLP, language models, interpretability, AI & society. Co-editor-in-chief of ACL Rolling Review. #NLProc #NLP
Founder & PI @aial.ie. Assistant Professor of AI, School of Computer Science & Statistics, @tcddublin.bsky.social
AI accountability, AI audits & evaluation, critical data studies. Cognitive scientist by training. Ethiopian in Ireland. She/her


























