Curious about the details for these efficiency claims?
We open-source everything for full reproducibility:
Paper: arxiv.org/abs/2506.09967
Blog: shangshangwang.notion.site/resa
Code: github.com/shangshang-w...
Model: huggingface.co/Resa-Yi
Training Logs: wandb.ai/upup-ashton-...
12.06.2025 17:02 — 👍 2 🔁 0 💬 0 📌 0
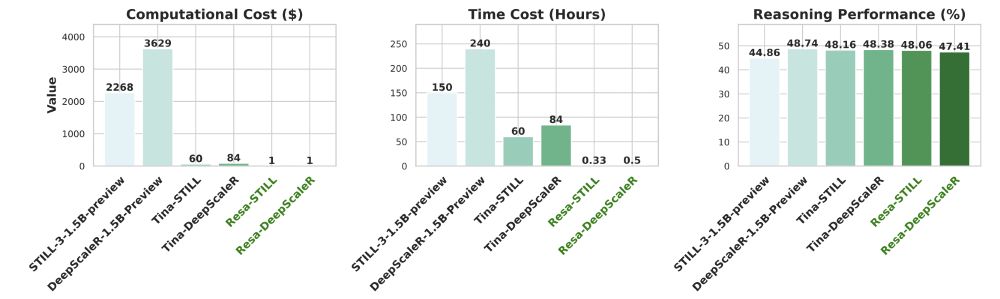
SAE-Tuning trains models that match RL-trained counterparts’ performance while reducing costs by >2000x and time by >450x.
The trained model is transparent, revealing where reasoning abilities hide, also generalizable and modular, enabling transfer across datasets and models.
12.06.2025 17:02 — 👍 0 🔁 0 💬 1 📌 0

Such efficiency stems from our novel SAE-Tuning method, which expands the use of SAEs beyond test-time steering.
In SAE-Tuning, the SAE first “extracts” latent reasoning features and then guides a standard supervised fine-tuning process to “elicit” reasoning abilities.
12.06.2025 17:02 — 👍 1 🔁 0 💬 1 📌 0

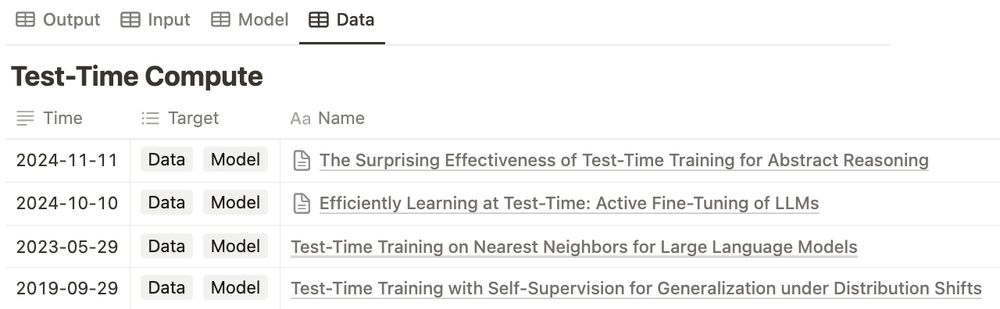
Sparse autoencoders (SAEs) can be used to elicit strong reasoning abilities with remarkable efficiency.
Using only 1 hour of training at $2 cost without any reasoning traces, we find a way to train 1.5B models via SAEs to score 43.33% Pass@1 on AIME24 and 90% Pass@1 on AMC23.
12.06.2025 17:02 — 👍 1 🔁 0 💬 1 📌 0

Check out more about Tina following the links down below.
Paper: arxiv.org/abs/2504.15777
Notion Blog: shangshangwang.notion.site/tina
Code: github.com/shangshang-w...
Model: huggingface.co/Tina-Yi
Training Logs: wandb.ai/upup-ashton-...
Tina's avatar is generated by GPT-4o based on KYNE's girls.
23.04.2025 17:10 — 👍 2 🔁 0 💬 0 📌 0
We also want to express our gratitude to the broader open-source community. This research was made possible by leveraging numerous publicly available resources from DeepScaleR, STILL, OpenThoughts @bespokelabs.bsky.social , OpenR1 @hf.co , LIMR, and OpenRS.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0
This is an amazing collaboration with Julian, Omer, Enes, and Oliver @oliu-io.bsky.social in the course taught by Willie @willieneis.bsky.social (both the teacher and the advisor) Thanks everyone!
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0
[9/9] 🚀 We thus hypothesize that LoRA’s effectiveness and efficiency stem from rapidly adapting the reasoning format under RL while preserving base model knowledge, a likely more compute-efficient process than the deep knowledge integration of full-parameter training.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0

[8/9] 💡 Observation 2) We consistently observe a training phase transition in the format-related metrics (format reward, completion length) but NOT accuracy-related metrics across most Tina models. And the best-performance checkpoint is always found around this transition point.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0

[7/9] 💡 Observation 1) We observe that in Tina models, increased training compute inversely affects performance, in contrast to full-parameter models. This observation highlights a “less compute can yield more performance” phenomenon.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0
🤔 But why? Where does this effectiveness and efficiency come from?
💡 We further provide insights based on our observations during post-training Tina models.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0

[6/9] 😋 And, it costs only $9 to reproduce the best Tina checkpoint, $526 to reproduce all our experiments from scratch!
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0

[5/9] 🤩 We validate this across multiple open-source reasoning datasets and various ablation settings with a single, fixed set of hyperparameters, confirming the effectiveness and efficiency of LoRA-based RL.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0

[4/9] 😍 With minimal post-training compute, the best Tina checkpoint achieves >20% performance increase over the base model and 43% Pass@1 on AIME24.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0

[3/9] 🚀 Our Tina models compete with, and sometimes surpass, SOTA models built on the same base model with a surprising high cost efficiency.
23.04.2025 17:10 — 👍 1 🔁 0 💬 1 📌 0
[2/9] 👩 We release the Tina family of models, created by post-training the DeepSeek-R1-Distill-Qwen-1.5B base model using low-rank adaptation (LoRA) during reinforcement learning (RL), on open-source reasoning datasets.
23.04.2025 17:10 — 👍 2 🔁 0 💬 1 📌 0

😃 Want strong LLM reasoning without breaking the bank? We explored just how cost-effectively RL can enhance reasoning using LoRA!
[1/9] Introducing Tina: A family of tiny reasoning models with strong performance at low cost, providing an accessible testbed for RL reasoning. 🧵
23.04.2025 17:10 — 👍 7 🔁 3 💬 1 📌 0

Feedback on "LLM Reasoning: Curated Insights"
6/6 This is an ongoing collection of LLM reasoning. Please feel free to send new materials or any feedback here or via the google form.
docs.google.com/forms/d/e/1F...
19.02.2025 18:01 — 👍 0 🔁 0 💬 1 📌 0


5/6 Others Artifacts
We then collect survey, evaluation, benchmark and application papers and also online resources like blogs, posts, videos, code, and data.
19.02.2025 18:01 — 👍 0 🔁 0 💬 1 📌 0

4/6 Verification, The Key to Reasoning
Verifiers serve as a key component in both post-training (e.g., as reward models) and test-time compute (e.g., as signals to guide search). Our fourth section collects thoughts on various verification.
19.02.2025 18:01 — 👍 0 🔁 0 💬 1 📌 0


2/6 Post-Training: Gain Reasoning Ability
Our second section collects thoughts on post-training methods for LLM reasoning including the hot RL-based and also SFT-based methods.
19.02.2025 18:01 — 👍 0 🔁 0 💬 1 📌 0

LLM Reasoning: Curated Insights
Reasoning ability is gained via post-training and is scaled via test-time compute.
Click on the link/card below to see the full set of spreadsheets, and check out the thread below for an overview of each section:
shangshangwang.notion.site/llm-reasoning
19.02.2025 18:01 — 👍 0 🔁 0 💬 1 📌 0

🔍 Diving deep into LLM reasoning?
From OpenAI's o-series to DeepSeek R1, from post-training to test-time compute — we break it down into structured spreadsheets. 🧵
19.02.2025 18:01 — 👍 4 🔁 2 💬 1 📌 0

Introducing METAGENE-1🧬, an open-source 7B-parameter metagenomics foundation model pretrained on 1.5 trillion base pairs. Built for pandemic monitoring, pathogen detection, and biosurveillance, with SOTA results across many genomics tasks.
🧵1/
06.01.2025 17:04 — 👍 27 🔁 6 💬 2 📌 0
The official account of the University of Southern California. #USC | #FightOn
President of Signal, Chief Advisor to AI Now Institute
CS PhD student at USC. Former research intern at AI2 Mosaic. Interested in human-AI interaction and language grounding.
Associate professor at CMU, studying natural language processing and machine learning. Co-founder All Hands AI
Tech Lead and LLMs at @huggingface 👨🏻💻 🤗 AWS ML Hero 🦸🏻 | Cloud & ML enthusiast | 📍Nuremberg | 🇩🇪 https://philschmid.de
AI professor at Caltech. General Chair ICLR 2025.
http://www.yisongyue.com
USC CS Ph.D. student
Prev Tsinghua Uni
NLP, Multimodal Learning, AI for Science
https://saccharomycetes.github.io/
full-time ML theory nerd, part-time AI-non enthusiast
AI @ OpenAI, Tesla, Stanford
The AI community building the future!
https://ollieliu.com/; oliver irl
phd'ing in ml@usc; prev. ml@cmu, msr
multimodal foundation models, ai4sci, decision making
Assistant Professor in CS + AI at USC. Previously at Stanford, CMU. Machine Learning, Decision Making, AI-for-Science, Generative AI, ML Systems, LLMs.
https://willieneis.github.io