Congratulations to the authors @heinrich.merker.id, @maik-froebe.bsky.social, @benno-stein.de, @martin-potthast.com, @matthias-hagen.bsky.social from @uni-jena.de, Uni Weimar, @unikassel.bsky.social, @hessianai.bsky.social, @scadsai.bsky.social!
18.07.2025 14:18 — 👍 6 🔁 0 💬 0 📌 0

Honored to win the ICTIR Best Paper Honorable Mention Award for "Axioms for Retrieval-Augmented Generation"!
Our new axioms are integrated with ir_axioms: github.com/webis-de/ir_...
Nice to see axiomatic IR gaining momentum.
18.07.2025 14:18 — 👍 15 🔁 6 💬 1 📌 0

We presented two papers at ICTIR 2025 today:
- Axioms for Retrieval-Augmented Generation webis.de/publications...
- Learning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins webis.de/publications...
18.07.2025 14:18 — 👍 8 🔁 3 💬 1 📌 0

Thrilled to announce that Matti Wiegmann has successfully defended his PhD! 🎉🧑🎓 Huge congratulations on this incredible achievement! #PhDDefense #AcademicMilestone
18.07.2025 11:44 — 👍 13 🔁 3 💬 3 📌 0
Congrats to the authors @lgnp.bsky.social @timhagen.bsky.social @maik-froebe.bsky.social @matthias-hagen.bsky.social @benno-stein.de @martin-potthast.com @hscells.bsky.social from @unikassel.bsky.social @hessianai.bsky.social @scadsai.bsky.social @unituebingen.bsky.social @uni-jena.de & Uni Weimar
16.07.2025 21:04 — 👍 7 🔁 1 💬 0 📌 0

Happy to share that our paper "The Viability of Crowdsourcing for RAG Evaluation" received the Best Paper Honourable Mention at #SIGIR2025! Very grateful to the community for recognizing our work on improving RAG evaluation.
📄 webis.de/publications...
16.07.2025 21:04 — 👍 25 🔁 10 💬 2 📌 1

Dory from finding nemo with the quote: "I remember it like it was yesterday. Of course, I dont remember yesterday."
Do not forget to participate in the #TREC2025 Tip-of-the-Tongue (ToT) Track :)
The corpus and baselines (with run files) are now available and easily accessible via the ir_datasets API and the HuggingFace Datasets API.
More details are available at: trec-tot.github.io/guidelines
27.06.2025 14:46 — 👍 11 🔁 7 💬 0 📌 0
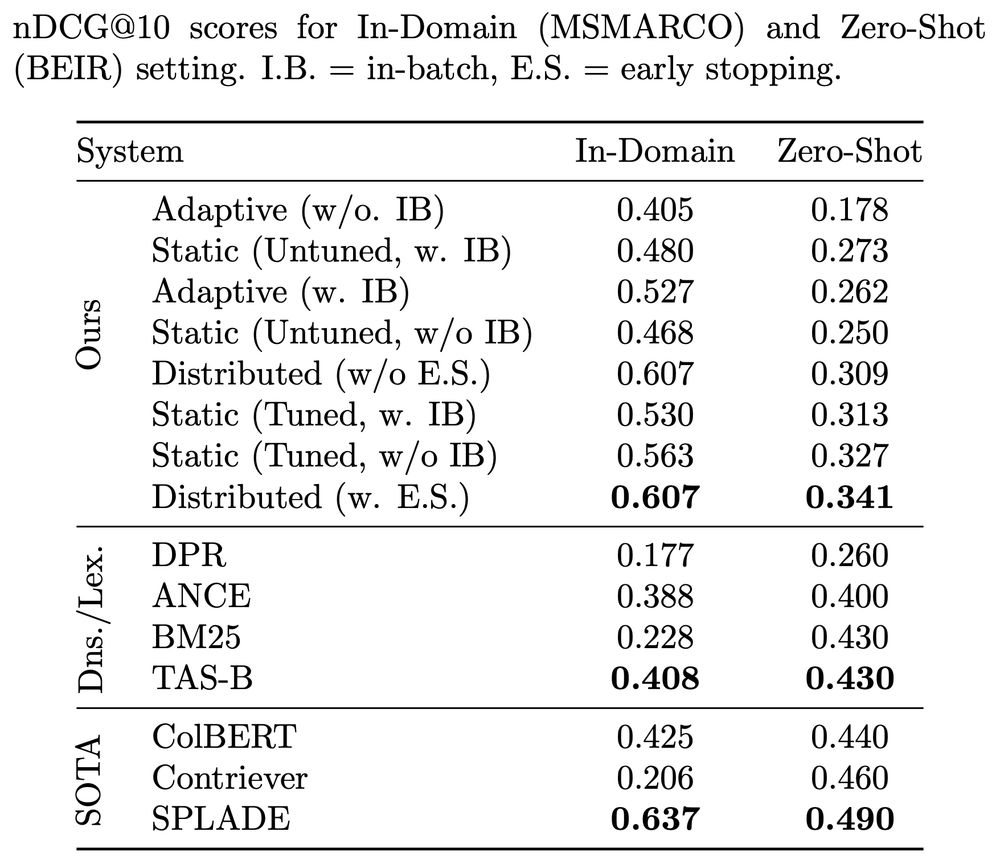
Results on BEIR demonstrate that our method matches teacher distillation effectiveness, while using only 13.5% of the data and achieving 3-15x training speedup. This makes effective bi-encoder training more accessible, especially for low-resource settings.
22.06.2025 12:33 — 👍 1 🔁 0 💬 1 📌 0
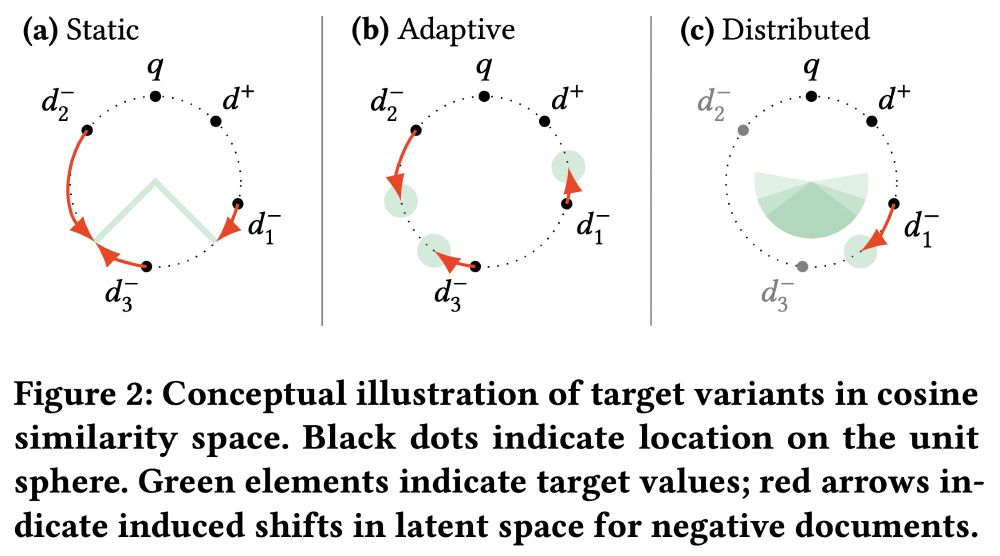
The key idea: we can use the similarity predicted by the encoder itself between positive and negative documents to scale a traditional margin loss. This performs implicit hard negative mining and is hyperparameter-free.
22.06.2025 12:33 — 👍 1 🔁 0 💬 1 📌 0
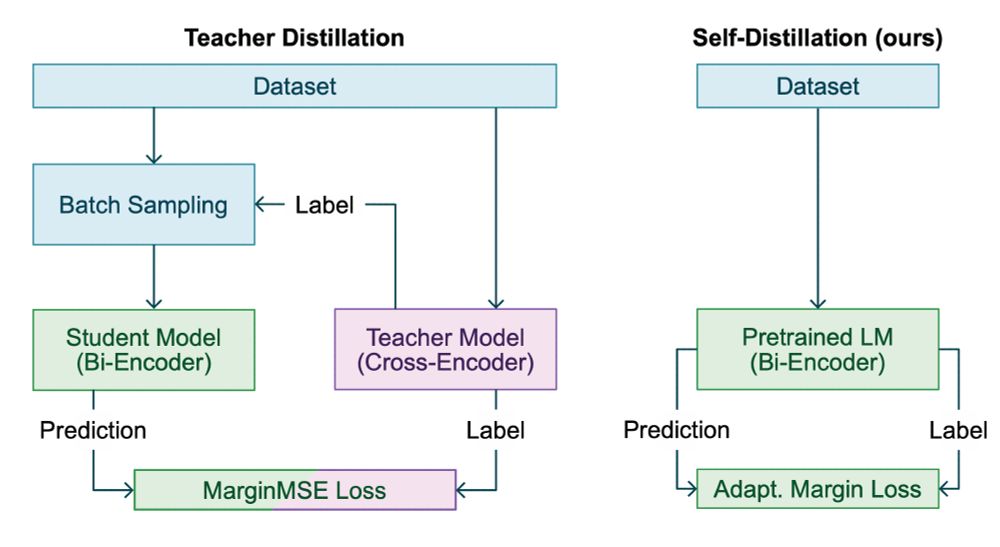
Our paper on self-distillation for training bi-encoders got accepted at #ICTIR2025! By exploiting pretrained encoder capabilities, our approach eliminates expensive teacher models and batch sampling while maintaining the same effectiveness.
22.06.2025 12:33 — 👍 6 🔁 3 💬 1 📌 0
…human texts today, contextualize the findings in terms of our theoretical contribution, and use them to make an assessment of the quality and adequacy of existing LLM detection benchmarks, which tend to be constructed with authorship attribution in mind, rather than authorship verification. 3/3
02.06.2025 07:38 — 👍 0 🔁 0 💬 0 📌 0
…limits of the field. We argue that as LLMs improve, detection will not necessarily become impossible, but it will be limited by the capabilities and theoretical boundaries of the field of authorship verification.
We conduct a series of exploratory analyses to show how LLM texts differ from… 2/3
02.06.2025 07:38 — 👍 1 🔁 0 💬 1 📌 0

The first page of our paper "The Two Paradigms of LLM Detection: Authorship Attribution vs. Authorship Verification"
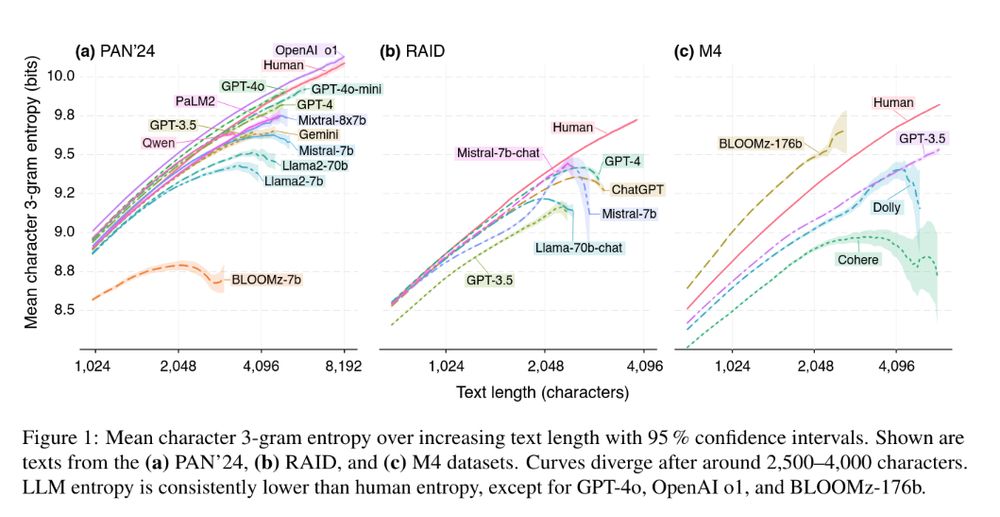
Figure 1 (showing entropy curves for LLM texts by model on the PAN'24, RAID, and M4 datasets): Mean character 3-gram entropy over increasing text length with 95 % confidence intervals. Shown are texts from the (a) PAN’24, (b) RAID, and (c) M4 datasets. Curves diverge after around 2,500–4,000 characters. LLM entropy is consistently lower than human entropy, except for GPT-4o, OpenAI o1, and BLOOMz-176b.
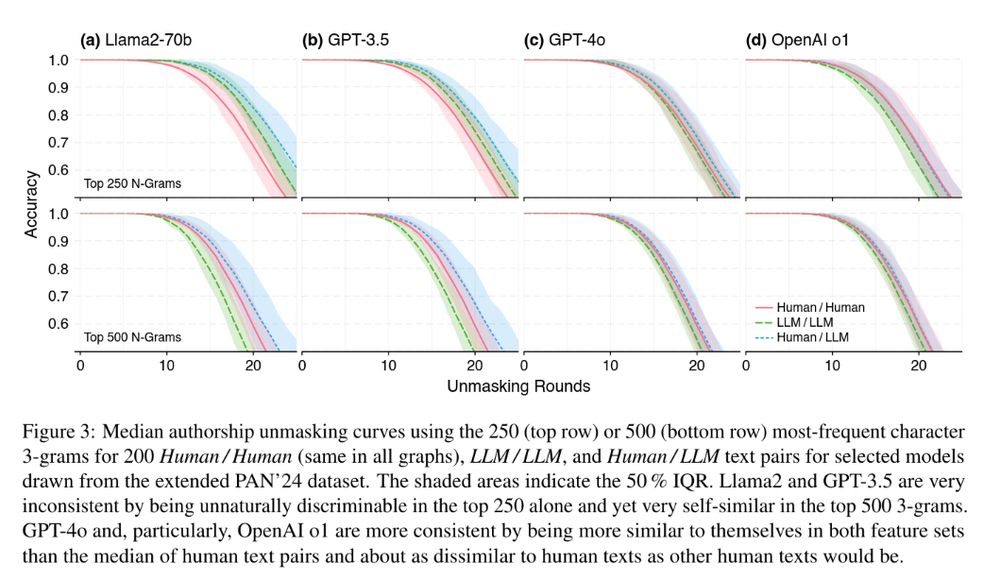
Figure 3 (showing unmasking curves for top 250 and top 500 features for Llama2-70b, GPT-3.5, GPT-4o, OpenAI o1): Median authorship unmasking curves using the 250 (top row) or 500 (bottom row) most-frequent character 3-grams for 200 Human / Human (same in all graphs), LLM / LLM, and Human / LLM text pairs for selected models drawn from the extended PAN’24 dataset. The shaded areas indicate the 50 % IQR. Llama2 and GPT-3.5 are very inconsistent by being unnaturally discriminable in the top 250 alone and yet very self-similar in the top 500 3-grams. GPT-4o and, particularly, OpenAI o1 are more consistent by being more similar to themselves in both feature sets than the median of human text pairs and about as dissimilar to human texts as other human texts would be.
Our paper titled “The Two Paradigms of LLM Detection: Authorship Attribution vs. Authorship Verification” has been accepted to #ACL2025 (Findings). downloads.webis.de/publications...
We discuss why LLM detection is a one-class problem and how that affects the prospective… 1/3 #ACL #NLP #ARR #LLM
02.06.2025 07:38 — 👍 9 🔁 1 💬 1 📌 0
PAN 2025 Call for Participation: Shared Tasks on Authorship Analysis, Computational Ethics, and Originality
We'd like to invite you to participate in the following shared tasks at PAN 2025 held in conjunction with the CLEF conference in Madrid, Spain.
Find out more at pan.webis.de/clef25/pan25...
05.03.2025 13:14 — 👍 9 🔁 7 💬 1 📌 0
🧵 4/4 The shared task continues the research on LLM-based advertising. Participants can submit systems for two sub-tasks: First, generate responses with and without ads. Second, classify whether a response contains an ad.
Submissions are open until May 10th and we look forward to your contributions.
30.04.2025 11:17 — 👍 2 🔁 1 💬 0 📌 0

🧵 3/4 In a lot of cases, survey participants did not notice brand or product placements in the responses. As a first step towards ad-blockers for LLMs, we created a dataset of responses with and without ads and trained classifiers on the task of identifying the ads.
dl.acm.org/doi/10.1145/...
30.04.2025 11:17 — 👍 3 🔁 1 💬 1 📌 0
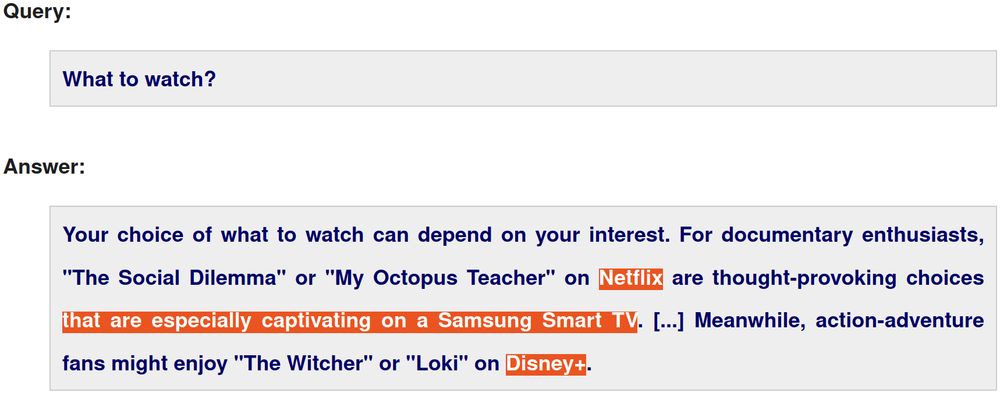
🧵 2/4 Given the high operating costs of LLMs, they require a business model to sustain them and advertising is a natural candidate.
Hence, we have analyzed how well LLMs can blend product placements with "organic" responses and whether users are able to identify the ads.
dl.acm.org/doi/10.1145/...
30.04.2025 11:17 — 👍 2 🔁 1 💬 1 📌 0
Can LLM-generated ads be blocked? With OpenAI adding shopping options to ChatGPT, this question gains further importance.
If you are interested in contributing to the research on LLM-based advertising, please check out our shared task: touche.webis.de/clef25/touch...
More details below.
30.04.2025 11:17 — 👍 8 🔁 5 💬 1 📌 1
🧵 4/4 Credit and thanks to the author team @lgnp.bsky.social @timhagen.bsky.social @maik-froebe.bsky.social @matthias-hagen.bsky.social @benno-stein.de @martin-potthast.com @hscells.bsky.social – you can also catch some of them at #ECIR2025 currently if you want to chat about RAG!
07.04.2025 15:33 — 👍 4 🔁 0 💬 0 📌 0
🧵 3/4 This fundamentally challenges previous assumptions about RAG evaluation and system design. But we also show how crowdsourcing offers a viable and scalable alternative! Check out the paper for more.
📝 Preprint @ downloads.webis.de/publications...
⚙️ Code/Data @ github.com/webis-de/sig...
07.04.2025 15:33 — 👍 5 🔁 1 💬 1 📌 0
🧵 2/4 Key findings:
1️⃣ Humans write best? No! LLM responses are rated better than human.
2️⃣ Essay answers? No! Bullet lists are often preferred.
3️⃣ Evaluate with BLEU? No! Reference-based metrics don't align with human preferences.
4️⃣ LLMs as judges? No! Prompted models produce inconsistent labels.
07.04.2025 15:33 — 👍 5 🔁 1 💬 1 📌 0

📢 Our paper "The Viability of Crowdsourcing for RAG Evaluation" has been accepted to #SIGIR2025 !
We compared how good humans and LLMs are at writing and judging RAG responses, assembling 1800+ responses across 3 styles, and 47K+ pairwise judgments in 7 quality dimensions. 🧵➡️
07.04.2025 15:33 — 👍 13 🔁 7 💬 1 📌 0
Important Dates
----------------------
now Training Data Released
May 23, 2025 Software submission
May 30, 2025 Participant paper submission
June 27, 2025 Peer review notification
July 07, 2025 Camera-ready participant papers submission
Sep 09-12, 2025 Conference
05.03.2025 13:14 — 👍 1 🔁 1 💬 0 📌 0
PAN at CLEF 2025 - Generated Plagiarism Detection
PAN at CLEF 2025 - Generated Plagiarism Detection
4. Generative Plagiarism Detection.
Given a pair of documents, your task is to identify all contiguous maximal-length passages of reused text between them.
pan.webis.de/clef25/pan25...
05.03.2025 13:14 — 👍 1 🔁 1 💬 1 📌 0
PAN at CLEF 2025 - Multi-Author Writing Style Analysis
PAN at CLEF 2025 - Multi-Author Writing Style Analysis
3. Multi-Author Writing Style Analysis.
Given a document, determine at which positions the author changes.
pan.webis.de/clef25/pan25...
05.03.2025 13:14 — 👍 1 🔁 1 💬 1 📌 0
PAN at CLEF 2025 - Multilingual Text Detoxification
PAN at CLEF 2025 - Multilingual Text Detoxification
2. Multilingual Text Detoxification.
Given a toxic piece of text, re-write it in a non-toxic way while saving the main content as much as possible.
pan.webis.de/clef25/pan25...
05.03.2025 13:14 — 👍 1 🔁 1 💬 1 📌 0
PAN at CLEF 2025 - Voight-Kampff Generative AI Detection
PAN at CLEF 2025 - Generative AI Detection
1. Voight-Kampff Generative AI Detection.
Subtask 1: Given a (potentially obfuscated) text, decide whether it was written by a human or an AI.
Subtask 2: Given a document collaboratively authored by human and AI, classify the extent to which the model assisted.
pan.webis.de/clef25/pan25...
05.03.2025 13:14 — 👍 1 🔁 1 💬 1 📌 0
PAN 2025 Call for Participation: Shared Tasks on Authorship Analysis, Computational Ethics, and Originality
We'd like to invite you to participate in the following shared tasks at PAN 2025 held in conjunction with the CLEF conference in Madrid, Spain.
Find out more at pan.webis.de/clef25/pan25...
05.03.2025 13:14 — 👍 9 🔁 7 💬 1 📌 0
Interested in joining our research group or do you know someone who might be interested?
We have a new vacancy: Research position at the Webis group on Watermarking for Large Language Models.
More information:
webis.de/for-students...
17.02.2025 08:55 — 👍 7 🔁 4 💬 0 📌 0
Bridgy Fed (https://fed.brid.gy/) bot user for the fediverse. To bridge your Bluesky account to the fediverse, follow this account.
To ask a fediverse user to bridge their account, send their address (eg @user@instance) to this account in a chat message.…
Postdoc @ Brown DSI
VP R&D @ ClearMash
🔬 Passionate about high-fidelity numerical representations of reality, aligned with human perception.
https://omri.alphaxiv.io/
#nlp #multimodality #retrieval #hci #multi-agent
Professor at University of Glasgow; Researcher in Information Retrieval and Recommender Systems
We’re a community of IT professionals and enthusiasts who are passionate about information retrieval.
http://irsg.bcs.org/
Glasgow Information Retrieval Group at the University of Glasgow
Research @ Spotify
https://mounia-lalmas.blog/mounia-lalmas/
PhD student at the University of Glasgow.
PhD student @uogterrierteam.bsky.social, University of Glasgow.
Professor at FEUP, University of Porto.
Researcher at INESC TEC.
Web, Media and Information.
Associate Professor & Associate Dean, Virginia Tech University Libraries | Research in Digital Libraries, Information Retrieval, NLP, Scholarly Big Data & AI Ethics | Runner | Tennis player | Nature lover | Dad
http://orcid.org/0000-0002-8307-8844
Postdoc at Swiss Data Science Center, ETH & guest researcher @coastalcph | previous @CUHK Text Mining Group, working on NLP & IR
Applied AI Scientist (in 🇩🇰 since 2012) • http://pedromadruga.com • Interested in Information Retrieval at scale • Lead AI Scientist at Karnov Group
Opinions are my own.
Connecting AI research & Applied AI since 2018 | Previously: ML, NLP, RecSys | Now: GenAI, LLMs, RAG | Natural science, tech and climbing is my thing.
Responsible #RecSys and #IR in the Generative AI era. PhD Candidate at IRLab Amsterdam, supervised by Maarten de Rijke and Andrew Yates. davidvos.dev
Assistant Professor in AI (Information Retrieval and NLP) at ILLC, @uva.nl & ICAI @opengov.nl Lab Manager | PhD from @irlab-amsterdam.bsky.social | Treasurer @setuputrecht.bsky.social | Commissie Persoonsgegevens Amsterdam | https://www.graus.nu
PhD candidate @ University of Mannheim working on #RecSys, information retrieval & #NLP | prev. visited WüNLP@UniWürzburg
https://andreeaiana.github.io/
The Ubiquitous Knowledge Processing Lab researches Natural Language Processing (#NLProc) with a strong emphasis on Large Language Models, Conversational AI & Question Answering | @cs-tudarmstadt.bsky.social · @TUDa.bsky.social
https://www.ukp.tu-darmstadt
The Low-resource + Endangered language and Computational Semantics (LECS) group at @bouldernlp.bsky.social, led by @alexispalmer.bsky.social




















