Introducing Hugging Face Sheets, where we explore how to create more accurate and reliable structured data with AI and web sources.
10.06.2025 14:39 — 👍 1 🔁 0 💬 1 📌 0

Cultivate robust synthetic data and reduce model hallucinations
Exciting news! I’m designing an open-source app that helps AI builders create high-quality datasets in minutes—whether they start with data or not.
🍆 Watch your dataset grow consistently column by column
🪁 Adjust data generation anytime
🦄 Stay in control while automation does the heavy lifting
17.03.2025 14:25 — 👍 2 🔁 0 💬 0 📌 0
Cette phrase n’est pas de moi je l'ai lu dans un article de Jean-Lou Fourquet dans son introduction au dossier "Art et IA, une cohabitation est-elle possible ?"
14.03.2025 13:46 — 👍 0 🔁 0 💬 0 📌 0

Cela calme la frénésie autour de l'IA qui pourrait s'emparer de tous les sujets, tous les domaines avec pertinence. Elle éclaire des réflexions sur le lien entre art et automatisation de certains “gestes”.
lnkd.in/dPgVApDA
14.03.2025 13:46 — 👍 0 🔁 0 💬 2 📌 0
There is a way to make better use of Generative AI.
As a designer working on a synthetic data generator, I attach great importance to working on fundamental “details” that help users consciously use the technology.
Action prevention, flexibility, efficiency, and information transparency.
20.02.2025 13:06 — 👍 0 🔁 0 💬 0 📌 0
It echoes a mention I read a few days ago in a post from Dan Shipper summarizing an interview with the CEO of Vercel.
“AI tools are shifting software toward consumption-based billing models, making us capital allocators who decide how much compute the AI consumes.”
20.02.2025 13:05 — 👍 1 🔁 0 💬 0 📌 0
From a citizen's perspective, this list of prompts (read each of them and think about it) illustrates well how companies are inciting people to consume AI in an unsustainable way, making it their faithful companion 🐶 all day long.
20.02.2025 13:04 — 👍 0 🔁 0 💬 0 📌 0
From a citizen's perspective, this list of prompts (read each of them and think about it) illustrates well how companies are inciting people to consume AI in an unsustainable way, making it their faithful companion 🐶 all day long.
20.02.2025 13:03 — 👍 0 🔁 0 💬 0 📌 0
From a UX perspective, I like this design principle of guiding users to achieve their tasks. In this case, the continuous flow of prompt examples does the job.
20.02.2025 13:02 — 👍 0 🔁 0 💬 3 📌 0
About the last ChatGPT home page:
“Be more assisted” would be a more accurate title, in my opinion.
20.02.2025 13:01 — 👍 1 🔁 0 💬 2 📌 0

Of course L'Express was obliged to use a photo of Sam Altman to best illustrate a conversation with me.
Of course neither a) taking a new picture of me during the interview, nor b) asking me to provide a picture of myself were impossible.
Of course.
11.02.2025 16:18 — 👍 35 🔁 5 💬 2 📌 1
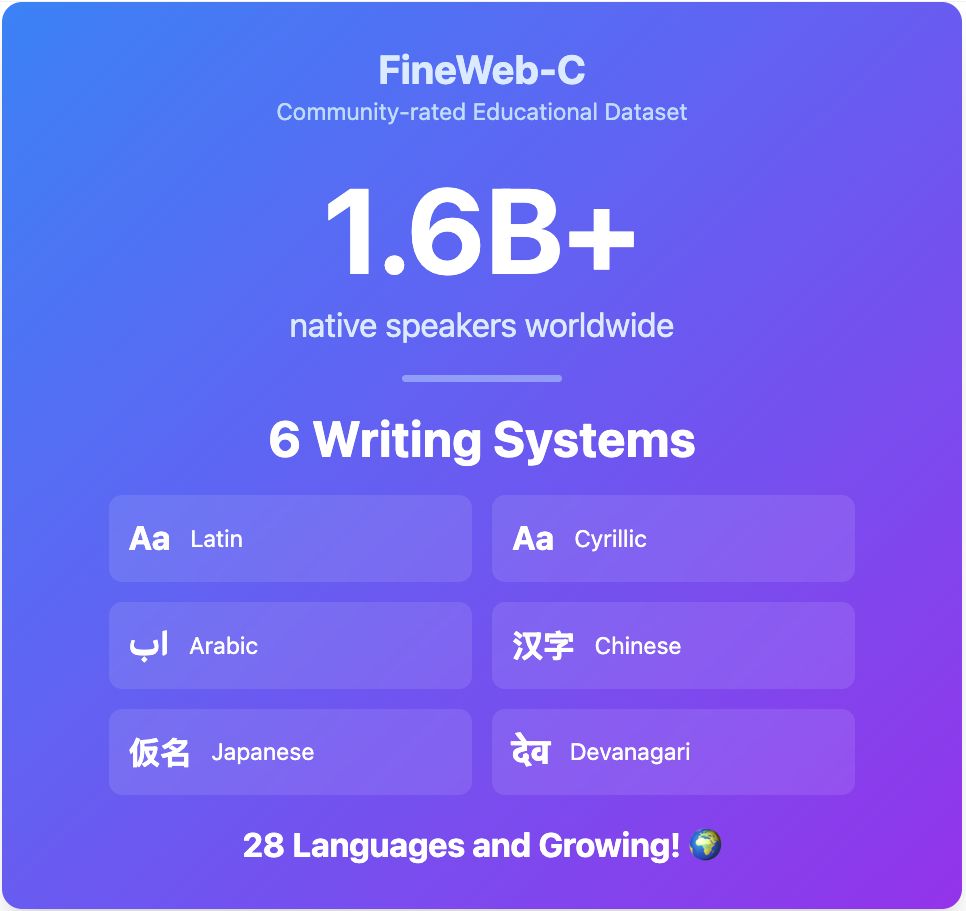
Image showing an overview of languages in the FineWeb-c Dataset.
🌍 Big step for multilingual AI data!
The @hf.co community has rated educational content in languages spoken by 1.6 billion people! New additions:
• Japanese
• Italian
• Old High German
These ratings can help enhance training data for major world languages.
27.01.2025 12:30 — 👍 27 🔁 3 💬 1 📌 1
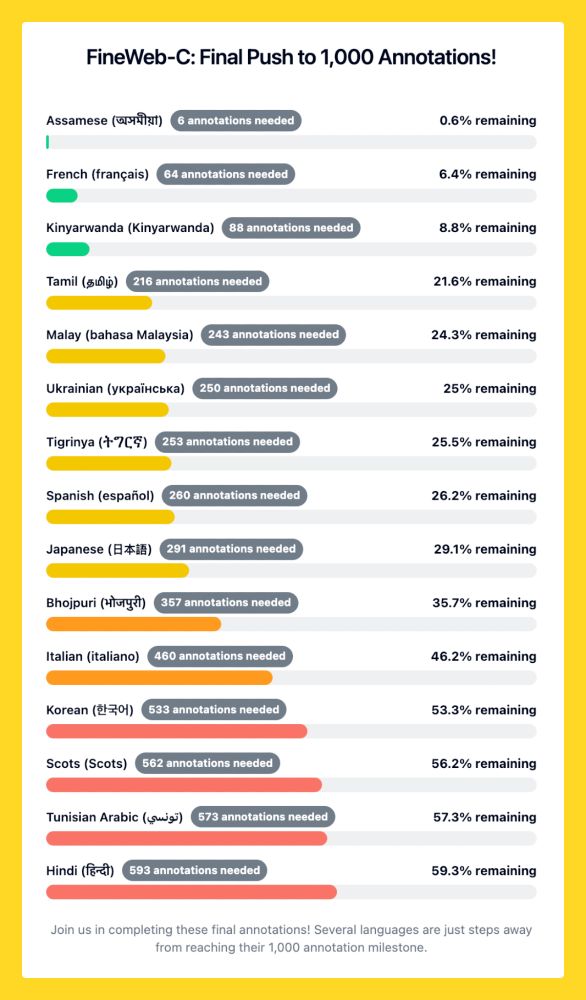
Progress bars showing remaining annotations needed for 15 languages in FineWeb-C dataset, ranging from 6 to 593 annotations needed
The finish line is near! We're building FineWeb-Edu for many languages and need your help 🤗
Many FineWeb-C languages are close to 1,000 annotations!
Assamese is 99.4% done, French needs 64 more annotations, Tamil: 216.
Please help us reach the goal: huggingface.co/spaces/data-...
06.01.2025 14:32 — 👍 20 🔁 5 💬 1 📌 1

Imagine creating custom datasets and training AI models WITHOUT writing a single line of code. We did and made it a reality.
@hf.co Synthetic Data Generator
Blog: huggingface.co/blog
Space: huggingface.co/spaces/argil...
GitHub: github.com/argilla-io/s...
16.12.2024 15:37 — 👍 22 🔁 6 💬 0 📌 0

fra - français - French
Join and contribute to the dataset fra - français - French
I've just contributed 20 examples to FineWeb 2 in French! Join me; we are already a couple of annotators there!
data-is-better-together-fineweb-c.hf.space/share-your-p...
10.12.2024 15:58 — 👍 4 🔁 0 💬 0 📌 0

In a couple of minutes, we’ll officially make the FineWeb 2 Annotation Sprint.
🎶 Go with your rhythms, and do what you can.
🤏 There is no minimum.
👐 Each contribution is welcomed.
The more we are, the better the result will be.
10.12.2024 11:51 — 👍 2 🔁 2 💬 0 📌 0


Vanakkam makkalae , glad that I’ll be leading the FineWeb 2 collaborative annotation sprint for Tamil! 🤗
I’ll be helping to build an open dataset to improve language models for our language. Do join the process of improving models !
huggingface.co/spaces/Huggi...
huggingface.co/spaces/data-...
10.12.2024 11:05 — 👍 1 🔁 1 💬 0 📌 0

I am thrilled to see Argilla increasingly used to enable impactful collaborative work around datasets.
Next week, we’ll announce a massive multi-language open annotation sprint to ensure all languages advance equally in AI.
06.12.2024 11:38 — 👍 2 🔁 1 💬 0 📌 0
[UX-UI update]
The latest update on the Argilla homepage provides a clear overview of your annotation projects, enhances project monitoring, and highlights the importance of collaboration in data curation.
29.11.2024 14:06 — 👍 2 🔁 0 💬 0 📌 0
👀 Who said the Argilla tool was only for text? I am proud of my brilliant teammates for setting up this significant initiative 🤗 @benburtenshaw.bsky.social @davidberenstein.bsky.social @danielvanstrien.bsky.social @dvilasuero.hf.co
26.11.2024 13:08 — 👍 2 🔁 1 💬 0 📌 0

Let’s make a generation of amazing open source image generation models from high quality data.
The best image generation models train on human preferences. Unfortunately, many of these datasets are closed. Let’s change that!
🧵 we're building a community dataset and we need help reviewing!
26.11.2024 12:00 — 👍 41 🔁 11 💬 5 📌 2
This is great, one of the responses could be "more effort on open datasets"
26.11.2024 08:41 — 👍 0 🔁 0 💬 1 📌 0
Soon: Another sprint to label all together a big dataset for many languages! Nominate yourself to lead your language community!
26.11.2024 07:21 — 👍 5 🔁 0 💬 0 📌 0

What about building a high-quality dataset together and making the result available to the whole Open-Source community?
You are all welcome with or without code skills, with or without a background in AI.
It's about democratizing access to AI projects and making how they work transparent.
25.11.2024 15:32 — 👍 4 🔁 1 💬 0 📌 0

⚫️⚪️ If you think transparency is key to building the image generation models of tomorrow, consider contributing to a massive open dataset.
Follow huggingface.co/data-is-bett... not to miss the announcement!
22.11.2024 15:05 — 👍 29 🔁 9 💬 0 📌 2
Renaissance Wonderland in Bloom | Art for Modern Dreamers 🌸🎨🤖 Crafting Semi-autonomous Visions Beyond Human and Machine
#Art #AICreativity #FineArt #ArtAndAI #AIArt #Artwork #ArtificialIntelligence #AIEvolution
🎨 https://bio.site/artcollector
Building Argilla @ 🤗 HuggingFace
🏗️ Software Architect ~ 🧮 Software Engineer ~ 🥋 Software Craftsman ~ 🎤 Speaker | Making software with passion applying the craftsmanship principles
Co-founder and CEO at Hugging Face
Independent researcher/consultant in AI and cognition; passionate about solving social challenges; love science and software development.
https://www.linkedin.com/in/catriona-kennedy-587b8658/
https://catrionakennedy.substack.com
Machine Learning Engineer @hf.co Hugging Face
Software Engineer at 🤗 Hugging Face: crafting smarter AI tools, empowering innovation, and bridging tech with creativity!
Concerned with tech, media and democracy. CEO & Editor at Tech Policy Press. Research & Adjunct Professor at NYU Tandon School of Engineering. Opinions mine.
Always growing, she/her, RAG builder, LLM whisperer, tech generalist
☀️ Assistant Professor of Computer Science at CU Boulder
👩💻 NLP, cultural analytics
🌐 https://maria-antoniak.github.io
Previously: Pioneer Centre for AI in Copenhagen, Ai2, Microsoft Research, Twitter, Facebook, Cornell, UW
AI scientist & consultant :: prev Amazon Alexa, Toshiba, Cam Uni :: voice & language tech :: powered by coffee :: photographer :: Cambridge UK
https://www.catherinebreslin.co.uk
Happy to be here
👾Webflow Developer | UX & No-Code Enthusiast
✨Floxies Ambassador @teamfloxies 🇲🇽
Building Argilla @ Hugging Face 🤗
🤗 Front-end Hugging Face
❤️ Open Source, Browsers, Svelte
🤟 Music lover
Children's book illustrator and artist, based in Sofia, Bulgaria
Art / Film Photography / Comics
🌐 www.denisillustrates.com
CEO of Bluesky, steward of AT Protocol.
Let’s build a federated republic, starting with this server. 🌱 🪴 🌳
you have the ability to understand things
principal engineer, react person, super gay, still masking
web dev, design, LLMs, data viz, tools for thought
✨ Design @ SHV
🌸 wattenberger.com
Engineering Manager @ Spotify💚
Black Code Collective co-founder ✊🏾
Scuba Diver 🧜🏽♀️🤿
Whiskey expert — IG: womanwithwhiskey
Adventurer 🗺️
am: Staff Engineer & Product Lead @slack.engineering. International Speaker. Design Systems Advocate. Chaotic Good.
was: Hillary for America (1st dev hired). IBM Design.
always: 🖖🏾. Whovian. Beyoncé.
♿️ AuDHD. CPTSD. INFP. ABCDEFG.
👉🏾 https://mina.codes
Data journalist / data analyst / trainer | Data/viz, média, monde du travail, écologie, culture web, parentalité | ex-@euronewsfr Féministe élevant 3 ♂ Insta @lirlilu / Github @missmee
 10.06.2025 14:41 — 👍 0 🔁 0 💬 0 📌 0
10.06.2025 14:41 — 👍 0 🔁 0 💬 0 📌 0
























