🚀 A new era in European #AIresearch begins!
ELLIOT is a €25M #HorizonEurope project launching July 2025 to build open, trustworthy Multimodal Generalist Foundation Models.
30 partners, 12 countries, EU values.
🔗 Press release: apigateway.agilitypr.com/distribution...
24.06.2025 06:46 — 👍 13 🔁 3 💬 0 📌 2
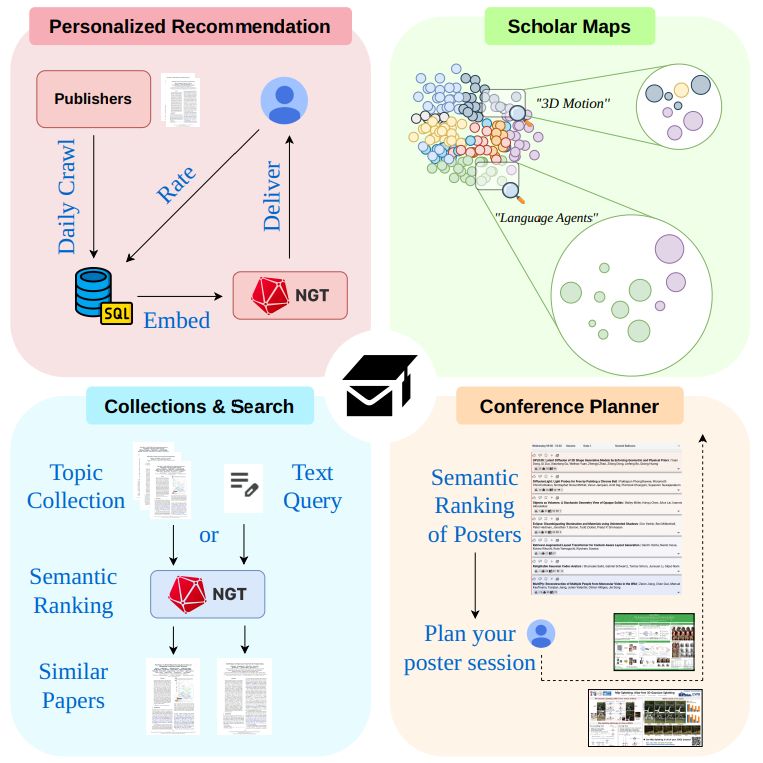
🚀 Never miss a beat in science again!
📬 Scholar Inbox is your personal assistant for staying up to date with your literature. It includes: visual summaries, collections, search and a conference planner.
Check out our white paper: arxiv.org/abs/2504.08385
#OpenScience #AI #RecommenderSystems
14.04.2025 11:04 — 👍 94 🔁 19 💬 1 📌 4
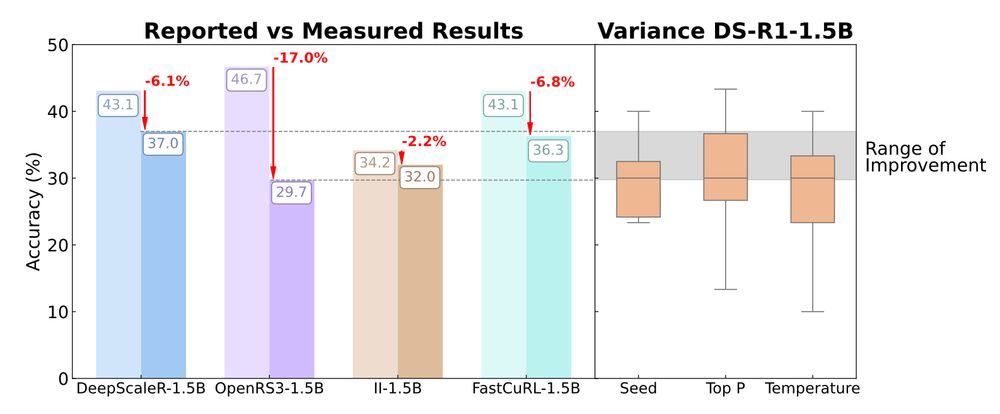
🧵1/ 🚨 New paper: A Sober Look at Progress in Language Model Reasoning
We re-evaluate recent SFT and RL models for mathematical reasoning and find most gains vanish under rigorous, multi-seed, standardized evaluation.
📊 bethgelab.github.io/sober-reason...
📄 arxiv.org/abs/2504.07086
10.04.2025 15:36 — 👍 14 🔁 5 💬 1 📌 0
Hochlehnert, Bhatnagar, Udandarao, Albanie, Prabhu, Bethge: A Sober Look at Progress in Language Model Reasoning: Pitfalls and Paths to Reproducibility https://arxiv.org/abs/2504.07086 https://arxiv.org/pdf/2504.07086 https://arxiv.org/html/2504.07086
10.04.2025 06:08 — 👍 1 🔁 2 💬 1 📌 0
Great work! A much-needed upgrade for continual learning datasets—excited to see progress on long-timespan tasks beyond classification. Deets below👇
10.04.2025 05:32 — 👍 1 🔁 0 💬 0 📌 0
Deadline extended to March 19 for the EVAL-FoMo workshop @cvprconference.bsky.social! We welcome submissions (incl. published papers) analyzing emerging capabilities & limits in visual foundation models.
Details: sites.google.com/view/eval-fo...
#CVPR2025
12.03.2025 12:20 — 👍 3 🔁 1 💬 0 📌 0
LMs excel at solving problems (~48% success) but falter at debunking them (<9% counterexample rate)!
Could form an AI Brandolini's Law: "Capability needed to refute bullshit is far larger than that needed to generate it"
28.02.2025 19:17 — 👍 2 🔁 0 💬 0 📌 0

AI can generate correct-seeming hypotheses (and papers!). Brandolini's law states BS is harder to refute than generate. Can LMs falsify incorrect solutions? o3-mini (high) scores just 9% on our new benchmark REFUTE. Verification is not necessarily easier than generation 🧵
28.02.2025 18:12 — 👍 4 🔁 2 💬 1 📌 1
Conference Management Toolkit - Login
Microsoft's Conference Management Toolkit is a hosted academic conference management system. Modern interface, high scalability, extensive features and outstanding support are the signatures of Micros...
🚀 Call for Papers – CVPR 3rd Workshop on Multi-Modal Foundation Models (MMFM)
@cvprconference.bsky.social ! 🚀
🔍 Topics: Multi-modal learning, vision-language, audio-visual, and more!
📅 Deadline: March 14, 2025
📝 Submission: cmt3.research.microsoft.com/MMFM2025
🌐 sites.google.com/view/mmfm3rd...
19.02.2025 14:16 — 👍 6 🔁 2 💬 1 📌 2
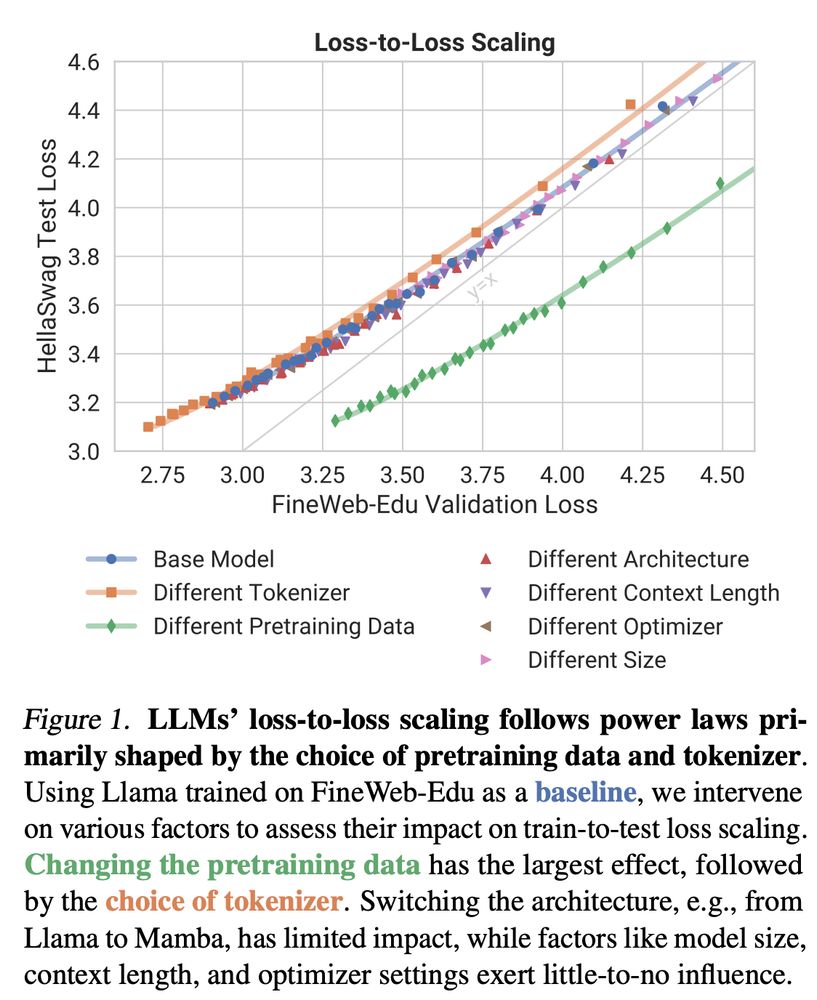
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
18.02.2025 14:09 — 👍 18 🔁 8 💬 1 📌 2
CuratedThoughts: Data curation focus for RL post-training! (Update 1) 🚀
25% of Openthoughts-114k-math filtered — issues included proofs, missing figures, and multiple questions with one answer.
Check out work by
@ahochlehnert.bsky.social & @hrdkbhatnagar.bsky.social
below 👇
17.02.2025 18:30 — 👍 2 🔁 0 💬 0 📌 0
Our 2nd Workshop on Emergent Visual Abilities and Limits of Foundation Models (EVAL-FoMo) is accepting submissions. We are looking forward to talks by our amazing speakers that include @saining.bsky.social, @aidanematzadeh.bsky.social, @lisadunlap.bsky.social, and @yukimasano.bsky.social. #CVPR2025
13.02.2025 16:02 — 👍 7 🔁 3 💬 0 📌 1

EVAL-FoMo 2
A Vision workshop on Evaluations and Analysis
🔥 #CVPR2025 Submit your cool papers to Workshop on
Emergent Visual Abilities and Limits of Foundation Models 📷📷🧠🚀✨
sites.google.com/view/eval-fo...
Submission Deadline: March 12th!
12.02.2025 14:45 — 👍 3 🔁 2 💬 0 📌 1
LMs are used for annotation, evaluation and distillation! We identify critical issues!
LMs of a similar capability class (not model family tho!) behave similarly and this skews oversight far more than I expected.
Check the 4-in-1 mega paper below to 👀 how 👇
07.02.2025 22:09 — 👍 2 🔁 0 💬 0 📌 0
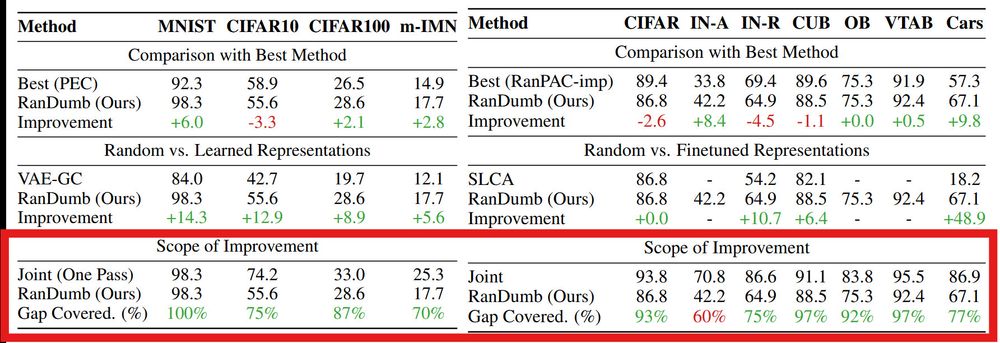
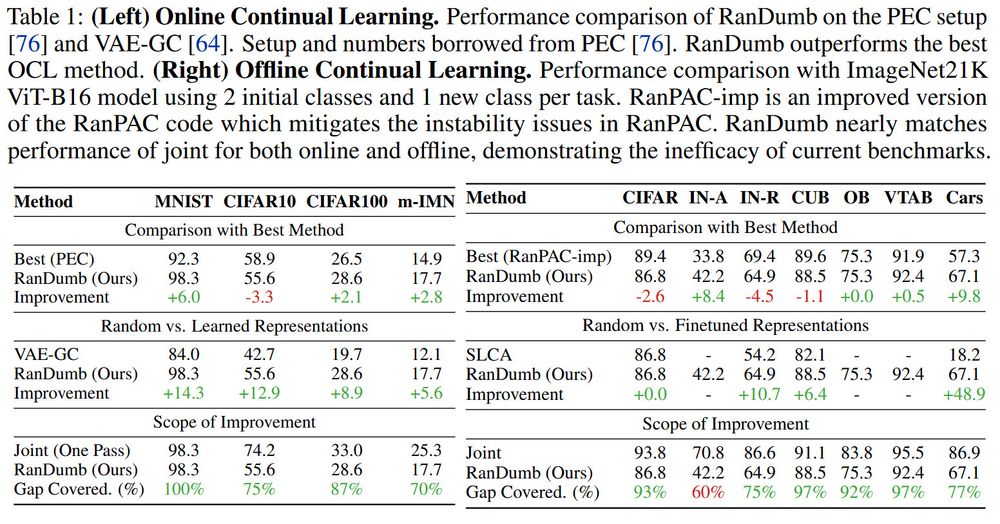
Can better representation learning help? No!
RanDumb recovers 70-90% of the joint performance.
Forgetting isn't the main issue—the benchmarks are too toy!
Key Point: Current OCL benchmarks are too constrained for any effective learning of online continual representations!
13.12.2024 18:53 — 👍 1 🔁 0 💬 0 📌 0
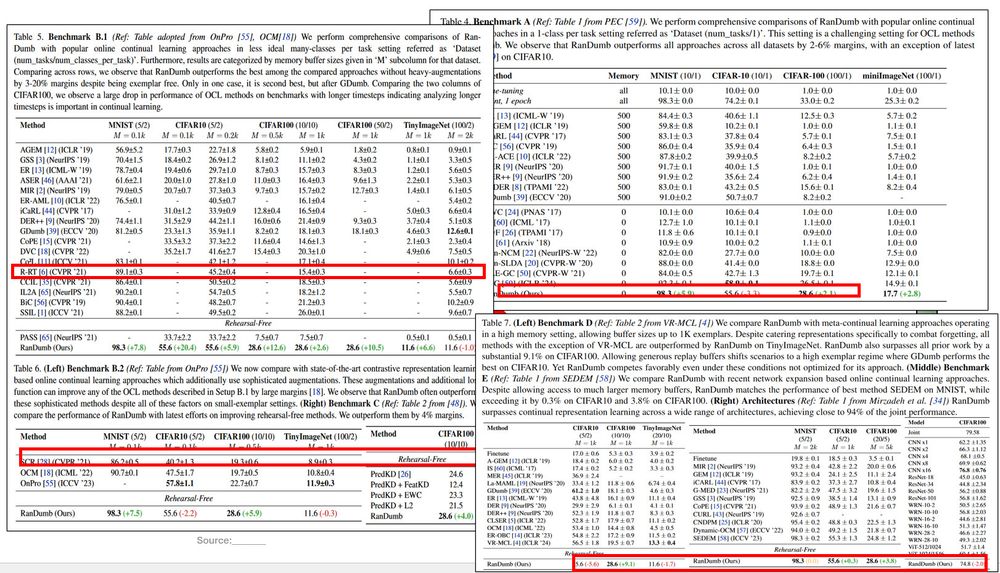
Across a wide range of online continual learning benchmarks-- RanDumb consistently surpasses prior methods (even latest contrastive & meta strategies), often by surprisingly large margins!
13.12.2024 18:53 — 👍 1 🔁 0 💬 1 📌 0
Continual Learning assumes deep representations learned outperform old school kernel classifiers (as in supervised DL). But this isn't validated!!
Why might it not work? Updates are limited and networks may not converge.
We find: OCL representations are severely undertrained!
13.12.2024 18:52 — 👍 0 🔁 0 💬 1 📌 0
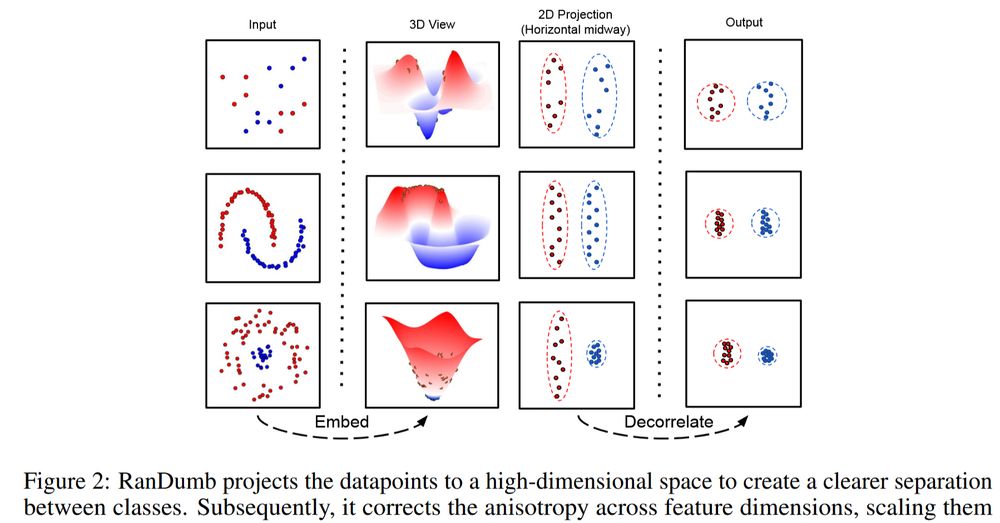
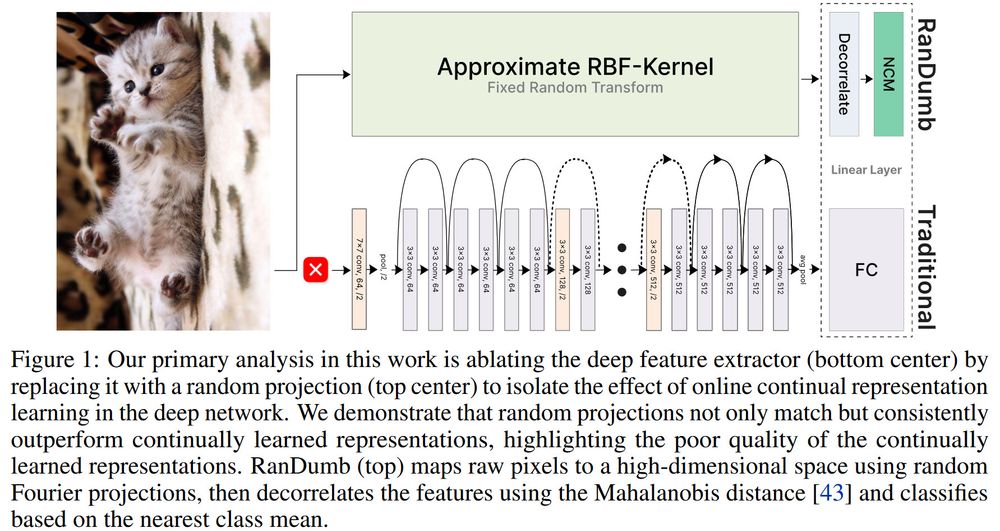
How RanDumb works: Fix a random embedder to transform raw pixels. Train a linear classifier on top—single pass, one sample at a time, no stored exemplars. Order-invariant, worst-case ready🚀
Looks familiar? This is streaming (approx.) Kernel LDA!!
13.12.2024 18:52 — 👍 0 🔁 0 💬 1 📌 0
New Work: RanDumb!🚀
Poster @NeurIPS, East Hall #1910- come say hi👋
Core claim: Random representations Outperform Online Continual Learning Methods!
How: We replace the deep network by a *random projection* and linear clf, yet outperform all OCL methods by huge margins [1/n]
13.12.2024 18:50 — 👍 1 🔁 0 💬 1 📌 0
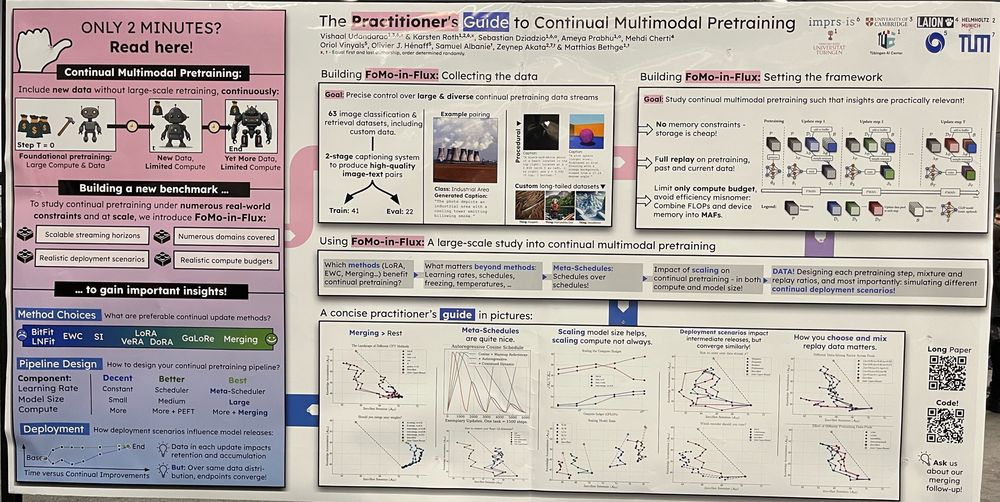
The Practitioner's Guide to Continual Multimodal Pretraining @dziadzio.bsky.social @confusezius.bsky.social @vishaalurao.bsky.social @bayesiankitten.bsky.social
12.12.2024 02:19 — 👍 24 🔁 4 💬 0 📌 0
Breaking the 8-model merge limit was tough, but we scaled to merging 200+ models! The secret? Iterative finetuning + merging *over time*.
The time axis unlocks scalable mergeability. Merging has surprising scaling gains across size & compute budgets.
All the gory details ⬇️
11.12.2024 18:16 — 👍 1 🔁 0 💬 0 📌 0
How do we benchmark the vast capabilities of foundation models? Introducing ONEBench – a unifying benchmark to test them all, led by
@adhirajghosh.bsky.social and
@dziadzio.bsky.social!⬇️
Sample-level benchmarks could be the new generation- reusable, recombinable & evaluate lots of capabilities!
10.12.2024 18:39 — 👍 2 🔁 1 💬 0 📌 0
Come chat with us @ NeurIPS for hot takes on the future of continual learning with foundation models!
10.12.2024 18:37 — 👍 1 🔁 0 💬 0 📌 0

ICLR 2025 Workshop Proposals
Welcome to the OpenReview homepage for ICLR 2025 Workshop Proposals
The list of accepted workshops for ICLR 2025 is available at openreview.net/group?id=ICL...
@iclr-conf.bsky.social
We received 120 wonderful proposals, with 40 selected as workshops.
03.12.2024 16:29 — 👍 57 🔁 15 💬 1 📌 5
Intern at Google Deepmind Toronto | PhD student in ML at Max Planck Institute Tübingen and University of Tübingen.
Machine Learning Researcher and Social Entrepreneur | Group Leader at ELLIS Institute Tübingen & Max Planck Institute for Intelligent Systems robustml.is.mpg.de | Co-Founder maddox.ai | Co-Initiator bw-ki.de | @ellis.eu scholar
Associate Professor in EECS at MIT. Neural nets, generative models, representation learning, computer vision, robotics, cog sci, AI.
https://web.mit.edu/phillipi/
PhD student at the University of Tübingen, member of @bethgelab.bsky.social, @uni_tue and @MPI_IS (IMPRS-IS). LLM multi-turn post-training and evaluations.
Neuroscience, Machine Learning, Computer Vision • Scientist at @unigoettingen.bsky.social & MPI-DS • https://eckerlab.org • Co-founder of https://maddox.ai • Dad of three • All things outdoor
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
Mathematician at UCLA. My primary social media account is https://mathstodon.xyz/@tao . I also have a blog at https://terrytao.wordpress.com/ and a home page at https://www.math.ucla.edu/~tao/
https://www.vita-group.space/ 👨🏫 UT Austin ML Professor (on leave)
https://www.xtxmarkets.com/ 🏦 XTX Markets Research Director (NYC AI Lab)
Superpower is trying everything 🪅
Newest focus: training next-generation super intelligence - Preview above 👶
Embodied lifelong learning (compositionality, RL, TAMP, robotics). Assistant Professor at Stony Brook ECE. Postdoc at MIT CSAIL, PhD from GRASP lab at Penn.
https://jorge-a-mendez.github.io
Faculty at the University of Pennsylvania. Lifelong machine learning and AI for robotics and precision medicine: continual learning, transfer & multi-task learning, deep RL, multimodal ML, and human-AI collaboration. seas.upenn.edu/~eeaton
ML researcher @ University of Oxford
ML Research Scientist at Oxford. DPhil student @compscioxford.bsky.social and TVGOxford. Ex ML Researcher @ Wise.
Deep Learning | ML Robustness | AI Safety | Uncertainty Quantification
PhD student at Oxford working on controllable video generation
Let's build AI's we can trust!
Torr Vision Group (TVG) In Oxford @ox.ac.uk
We work on Computer Vision, Machine Learning, AI Safety and much more
Learn more about us at: https://torrvision.com
Attorney, Author, Advisor, Academic, Futurist. 🇺🇸 🇨🇦
Inspiring transformative thinking and resilience where law, technology, and human rights converge
AI, Blockchain, XR, Health, and Humanity's Response to Uncertainty
www.ElizabethRothman.com
Professor of Data Science @ University of Tübingen, Director of Hertie AI (www.hertie.ai) and Speaker of ML4Science (www.machinelearningforscience.de)