
🚨 New paper alert! 🚨
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)

@joschkastrueber.bsky.social
PhD student at the University of Tübingen, member of @bethgelab.bsky.social
🚨 New paper alert! 🚨
We’ve just launched openretina, an open-source framework for collaborative retina modeling across datasets and species.
A 🧵👇 (1/9)

AI can generate correct-seeming hypotheses (and papers!). Brandolini's law states BS is harder to refute than generate. Can LMs falsify incorrect solutions? o3-mini (high) scores just 9% on our new benchmark REFUTE. Verification is not necessarily easier than generation 🧵
28.02.2025 18:12 — 👍 4 🔁 2 💬 1 📌 1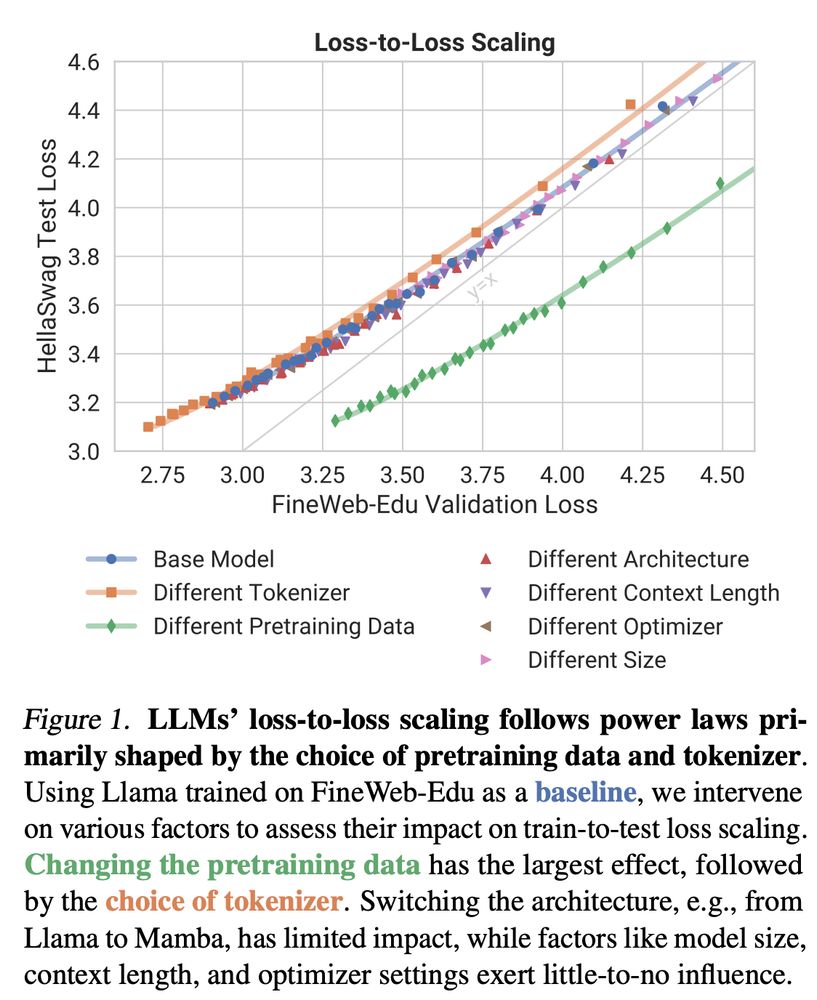
New preprint out! 🎉
How does LLM training loss translate to downstream performance?
We show that pretraining data and tokenizer shape loss-to-loss scaling, while architecture and other factors play a surprisingly minor role!
brendel-group.github.io/llm-line/ 🧵1/8
CuratedThoughts: Data Curation for RL Datasets 🚀
Since DeepSeek-R1 introduced reasoning-based RL, datasets like Open-R1 & OpenThoughts emerged for fine-tuning & GRPO. Our deep dive found major flaws — 25% of OpenThoughts needed elimination by data curation.
Here's why 👇🧵

Hiring announcement: ELLIS Institute Tübingen is looking for ML Researchers & Engineers for Open-Source AI Tutoring (m/f/d). The image features a white background with bold black text and the colorful ELLIS logo at the bottom.
🚀 We’re hiring! Join Bernhard Schölkopf & me at @ellisinsttue.bsky.social to push the frontier of #AI in education!
We’re building cutting-edge, open-source AI tutoring models for high-quality, adaptive learning for all pupils with support from the Hector Foundation.
👉 forms.gle/sxvXbJhZSccr...
Hi Sebastian, can you please add me to the starter pack? Thank you and have a great weekend!
08.02.2025 00:32 — 👍 1 🔁 0 💬 1 📌 0
Paper📜: arxiv.org/abs/2502.04313
Webpage🌐: model-similarity.github.io
Code🧑💻: github.com/model-simila...
Data📂: huggingface.co/datasets/bet...
Joint work with Shashwat Goel, Ilze Auzina, Karuna Chandra, @bayesiankitten.bsky.social @pkprofgiri.bsky.social, Douwe Kiela,
MatthiasBethge and Jonas Geiping
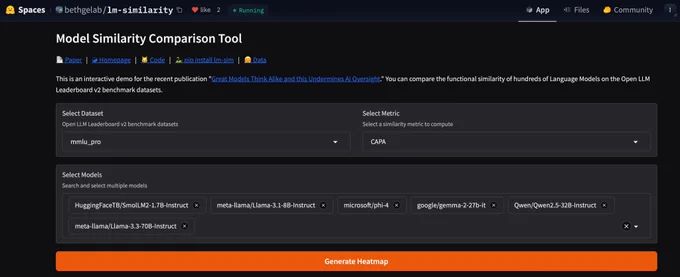
Sounds interesting? Play with model similarity metrics on our @huggingface
space huggingface.co/spaces/bethg..., thanks to sample-level predictions on OpenLLMLeaderboard. Or run pip install lm-sim, we welcome open-source contributions!
Similarity offers a different (ha!) perspective to compare LMs, that we think should be more popular. Can we measure free-text reasoning similarity? How correlated are our research bets? Implications for multi-agent systems? These are just some questions we need more research on!
07.02.2025 21:12 — 👍 3 🔁 0 💬 1 📌 0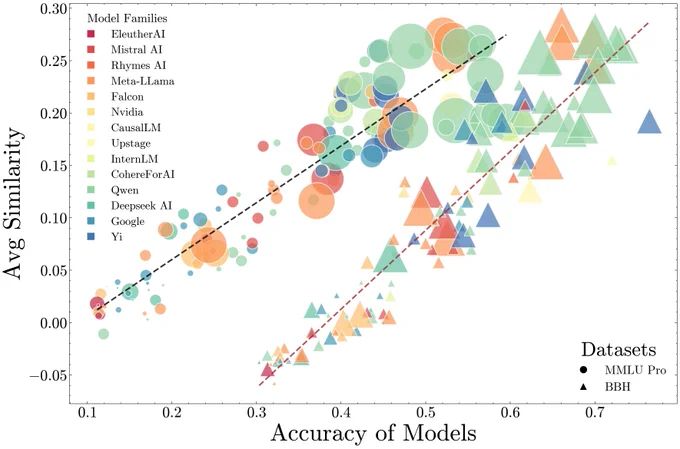
We will defer more to AI oversight for both evaluation and training as capabilities increase. Concerningly, more capable models are making more similar mistakes📈🙀
Appendix: Slightly steeper slope for instruct models, and switching architecture to Mamba doesnt reduce similarity!
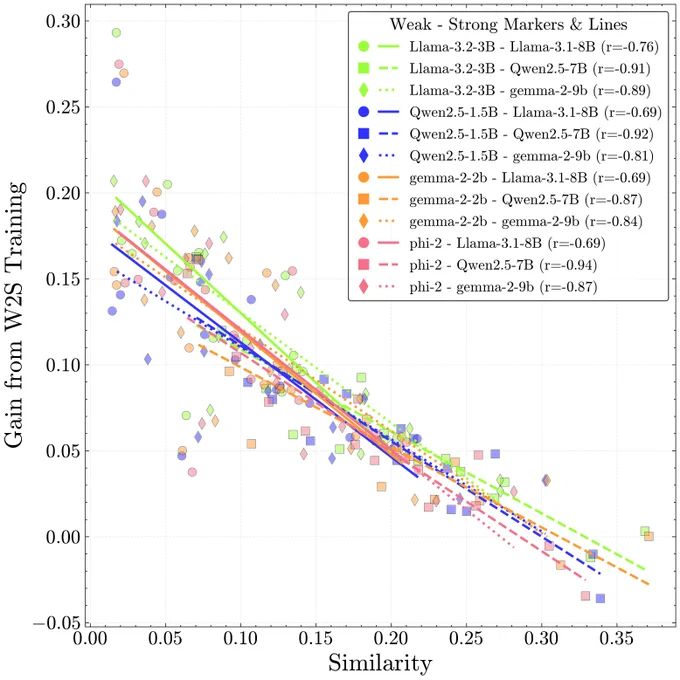
For Training on AI Annotations: We find complementary knowledge (lower similarity) predicts weak-to-strong generalization, i.e. gains from training on a smaller expert model's annotations. The performance ceiling is beyond what was previously understood from elicitation.☯️
07.02.2025 21:12 — 👍 1 🔁 0 💬 1 📌 0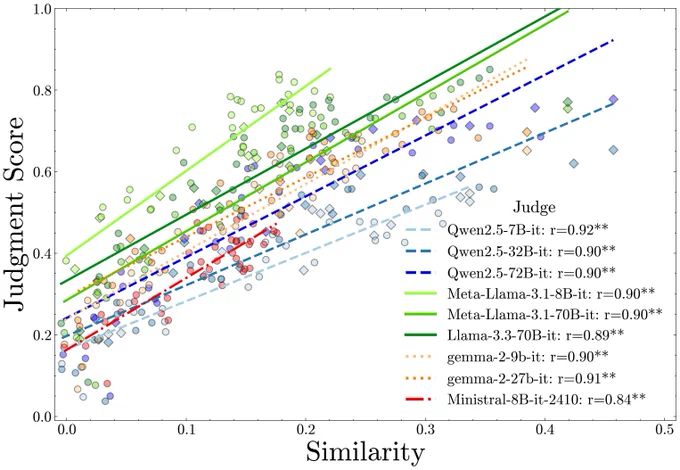
For AI Evaluators: We find LM judges favor more similar models, generalizing recent self-preference results. We used partial correlation and multiple regression tests to control for capability. Bias is worse for smaller judges, but effects persist in the largest/best ones too!🤥
07.02.2025 21:12 — 👍 1 🔁 0 💬 1 📌 0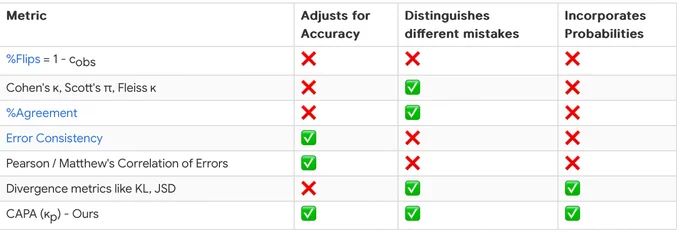
First, how to measure model similarity?
💡Similar models make similar mistakes.
❗Two 90% accuracy models have lesser scope to disagree than two 50% models. We adjust for chance agreement due to accuracy.
Taking this into account, we propose a new metric, Chance Adjusted Probabilistic Agreement (CAPA)
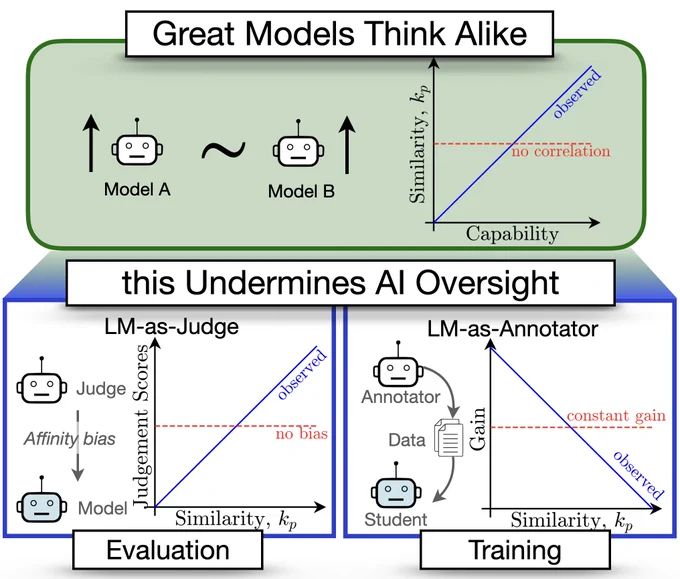
🚨Great Models Think Alike and this Undermines AI Oversight🚨
New paper quantifies LM similarity
(1) LLM-as-a-judge favor more similar models🤥
(2) Complementary knowledge benefits Weak-to-Strong Generalization☯️
(3) More capable models have more correlated failures 📈🙀
🧵👇



















