“Continuous Thought Machines”
Blog → sakana.ai/ctm
Modern AI is powerful, but it's still distinct from human-like flexible intelligence. We believe neural timing is key. Our Continuous Thought Machine is built from the ground up to use neural dynamics as a powerful representation for intelligence.
12.05.2025 02:33 — 👍 73 🔁 15 💬 3 📌 5

moonshotai/Kimi-Audio-7B-Instruct · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
Kimi-Audio 🚀🎧 an OPEN audio foundation model released by Moonshot AI
huggingface.co/moonshotai/K...
✨ 7B
✨ 13M+ hours of pretraining data
✨ Novel hybrid input architecture
✨ Universal audio capabilities (ASR, AQA, AAC, SER, SEC/ASC, end-to-end conversation)
28.04.2025 07:34 — 👍 3 🔁 1 💬 0 📌 1

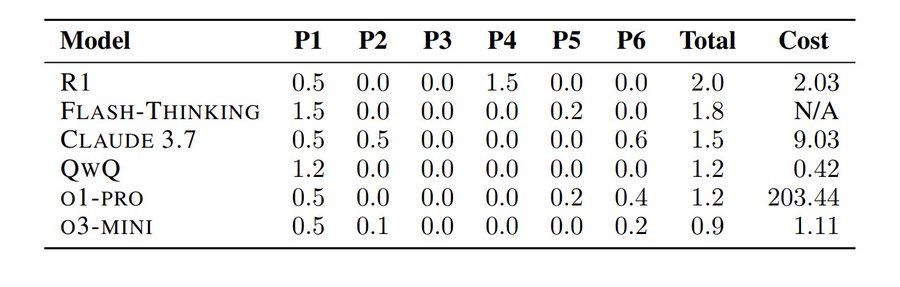
A line chart titled “Figure 1: Inference-time scaling performance with different RMs on all tested RM benchmarks” shows performance on the y-axis (ranging from 66.5 to 72.5) and k: #sampled rewards (logscale) on the x-axis, with values from 1 to 32.
Key observations:
• DeepSeek-GRM-27B (MetaRM@k) (Ours) is the top performer, shown with a red line and star markers, rising steeply and leveling near 72.5.
• DeepSeek-GRM-27B (Voting@k) (Ours) follows, in blue with stars, peaking slightly above 70.5.
• GPT-4o (Greedy) is shown as a gray dashed line, sitting just under 71.
• Other models, shown in orange, green, brown, and gray lines (scalar or voting methods), plateau between ~66.5 and ~68.5.
• LLM-as-a-Judge w/ TokenProb, Skywork-Reward-Gemma-2-27B, and DeepSeek-BTRM-27B are among these lower-performing models.
Caption summary: The plot shows how performance scales with the number of reward samples at inference time. Results are up to 8 samples, with some (DeepSeek models) extrapolated to 32. Models in non-italic font use Gemma-2-27B as their base.
🚨New DeepSeek Model Incoming🚨
but first they release the paper describing generative reward modeling (GRM) via Self-Principled Critique Tuning (SPCT)
looking forward to DeepSeek-GRM!
arxiv.org/abs/2504.02495
04.04.2025 10:45 — 👍 30 🔁 6 💬 4 📌 5
You’ve probably heard about how AI/LLMs can solve Math Olympiad problems ( deepmind.google/discover/blo... ).
So naturally, some people put it to the test — hours after the 2025 US Math Olympiad problems were released.
The result: They all sucked!
31.03.2025 20:33 — 👍 174 🔁 50 💬 9 📌 12

Kimi 1.6 is coming ...
Source: livecodebench.github.io/leaderboard....
Chat: kimi.ai
27.02.2025 22:53 — 👍 17 🔁 3 💬 0 📌 1

This is new - Moonshot AI (i.e., kimi.ai) released the two open-weigh models.
Moonlight: 3B/16B MoE model trained with Muon on 5.7T tokens, advancing the Pareto frontier with better performance at fewer FLOPs.
huggingface.co/moonshotai
22.02.2025 20:20 — 👍 15 🔁 4 💬 1 📌 1

The paper below describes Huawei's cloud AI platform designed to efficiently serve LLMs.
It uses four major design components: serverless abstraction and infrastructure, serving engine, scheduling algorithms, and scaling optimizations.
18.02.2025 13:43 — 👍 13 🔁 1 💬 2 📌 0

RAG is dead. Long live RAG.
LLMs suck at long context.
This paper shows what I have seen in most deployments.
With longer contexts, performance degrades.
13.02.2025 06:11 — 👍 6 🔁 1 💬 1 📌 0

🔥 allenai/Llama-3.1-Tulu-3-8B (trained with PPO) -> allenai/Llama-3.1-Tulu-3.1-8B (trained with GRPO)
We are happy to "quietly" release our latest GRPO-trained Tulu 3.1 model, which is considerably better in MATH and GSM8K!
12.02.2025 17:33 — 👍 22 🔁 5 💬 1 📌 2
Probabilistic Inference Scaling
Probabilistic Inference Scaling
can we scale small, open LMs to o1 level? Using classical probabilistic inference methods, YES!
Particle filtering approach to Improved inference w/o any training!
Check out probabilistic-inference-scaling.github.io
By Aisha Puri et al📈🤖
Joint MIT-CSAIL & RedHat
07.02.2025 20:05 — 👍 48 🔁 5 💬 1 📌 0

Post training an LLM for reasoning with GRPO in TRL by @sergiopaniego.bsky.social
A guide to post-training a LLM using GRPO. It's particularly effective for scaling test-time compute for extended reasoning, making it an ideal approach for solving complex tasks, such as mathematical problem-solving
07.02.2025 05:15 — 👍 11 🔁 2 💬 1 📌 0


Dzisiaj spotkanie z załogą misji Ax-4 w Centrum Nauki Kopernik. Trzymamy kciuki za lot Sławosza Uznańskiego!
z @polsa.studenci @astro_peggy @astro_slawosz @tibor_to_orbit
05.02.2025 21:57 — 👍 3 🔁 1 💬 0 📌 0
A ateizm to jakiś lewicowy postulat?
04.02.2025 19:23 — 👍 0 🔁 0 💬 0 📌 0

Alibaba Qwen2.5-1M ! 💥 Now supporting a 1 MILLION TOKEN CONTEXT LENGTH 🔥
📄 Blog: qwenlm.github.io/blog/qwen2.5...
26.01.2025 17:56 — 👍 39 🔁 5 💬 5 📌 0

The image depicts a monumental statue of Buddha, emphasizing serenity and grandeur. The statue's intricate design captures traditional Buddhist features, including a meditative posture with hands placed in a symbolic gesture, flowing robes, and a calm facial expression exuding peace. The perspective highlights the statue's immense size against a minimalistic white sky background, underscoring its significance as a spiritual and cultural landmark.
Explainer: What's R1 and Everything Else
This is an attempt to consolidate the dizzying rate of AI developments since Christmas. If you're into AI but not deep enough, this should get you oriented again.
timkellogg.me/blog/2025/01...
26.01.2025 03:17 — 👍 116 🔁 27 💬 5 📌 13
The “Active Enum” Pattern
Enums are objects, why not give them attributes?
https://blog.glyph.im/2025/01/active-enum.html
26.01.2025 05:15 — 👍 10 🔁 1 💬 2 📌 0
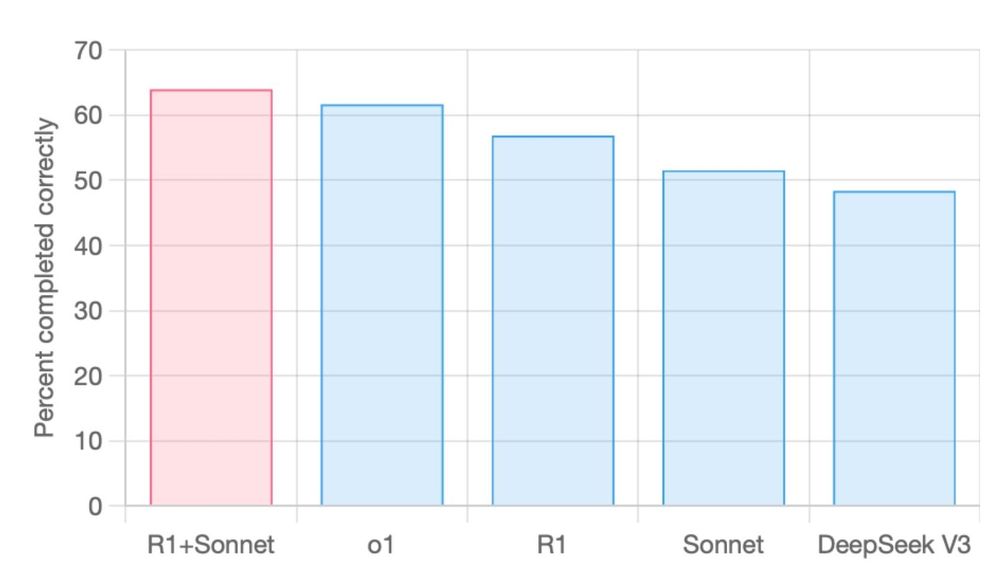
R1+Sonnet set SOTA on aider’s polyglot benchmark
R1+Sonnet has set a new SOTA on the aider polyglot benchmark. At 14X less cost compared to o1.
Aider reports that R1+Sonnet (R1 Thinking + Sonnet) set a new SOTA on the aider polyglot benchmark at 14X less cost compared to o1.
64% R1+Sonnet
62% o1
57% R1
52% Sonnet
48% DeepSeek V3
aider.chat/2025/01/24/r...
24.01.2025 17:46 — 👍 41 🔁 9 💬 1 📌 2

InternLM v3
- Performance surpasses models like Llama3.1-8B and Qwen2.5-7B
- Capable of deep reasoning with system prompts
- Trained only on 4T high-quality tokens
huggingface.co/collections/...
15.01.2025 08:24 — 👍 18 🔁 7 💬 2 📌 0
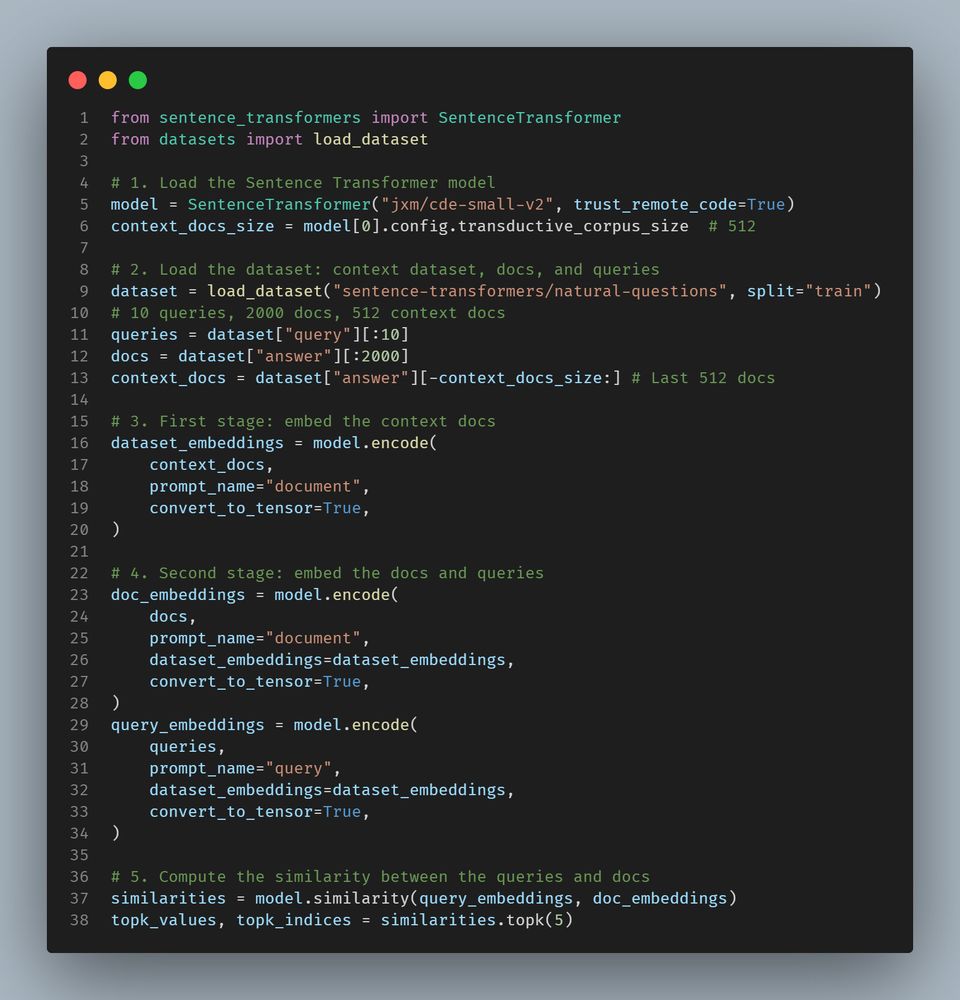
The newest extremely strong embedding model based on ModernBERT-base is out: `cde-small-v2`. Both faster and stronger than its predecessor, this one tops the MTEB leaderboard for its tiny size!
Details in 🧵
14.01.2025 13:21 — 👍 31 🔁 7 💬 1 📌 1

"Sky-T1-32B-Preview, our reasoning model that performs on par with o1-preview on popular reasoning and coding benchmarks."
That was quick! Is this already the Alpaca moment for reasoning models?
Source: novasky-ai.github.io/posts/sky-t1/
14.01.2025 00:34 — 👍 39 🔁 8 💬 3 📌 0

Google's Titans: a new architecture with attention and a meta in-context memory that learns how to memorize at test time as presented by one of the author - @alibehrouz.bsky.social
13.01.2025 19:53 — 👍 70 🔁 18 💬 4 📌 5

What a week to open the year in open ML, all the things released at @hf.co 🤠
Here's everything released, find text-readable version here huggingface.co/posts/merve/...
All models are here huggingface.co/collections/...
10.01.2025 14:51 — 👍 21 🔁 1 💬 0 📌 0

Contemplative LLMs: Anxiety is all you need?
Let the LLM 'contemplate' before answering
Contemplative LLMs: Anxiety is all you need? by Maharshi
Let the LLM 'contemplate' for a bit before answering using this simple system prompt, which might (in most cases) lead to the correct final answer!
maharshi.bearblog.dev/contemplativ...
10.01.2025 03:44 — 👍 25 🔁 8 💬 1 📌 0

Release v1.2.0 · modelcontextprotocol/python-sdk
A big thank you to @jlowin for the creation of the fantastic FastMCP, which is now included into the MCP SDK.
Backwards Compatibility
This release is semver compatible. Existing code will continue ...
This is a big one: Python MCP SDK 1.2.0 is out!
The best part? It contains the widely used FastMCP library as part of the SDK. Don't worry, the old code still works and there is no need to update, but writing new servers is much easier.
Check out the release notes: github.com/modelcontext...
03.01.2025 22:30 — 👍 18 🔁 4 💬 0 📌 0
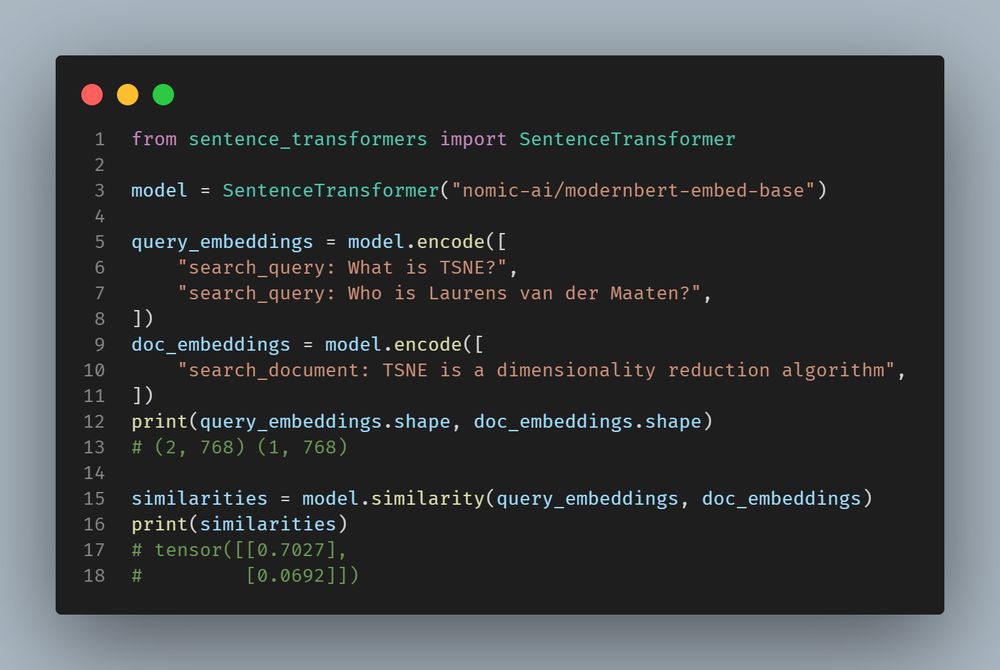
That didn't take long! Nomic AI has finetuned the new ModernBERT-base encoder model into a strong embedding model for search, classification, clustering and more!
Details in 🧵
31.12.2024 15:43 — 👍 37 🔁 10 💬 2 📌 1
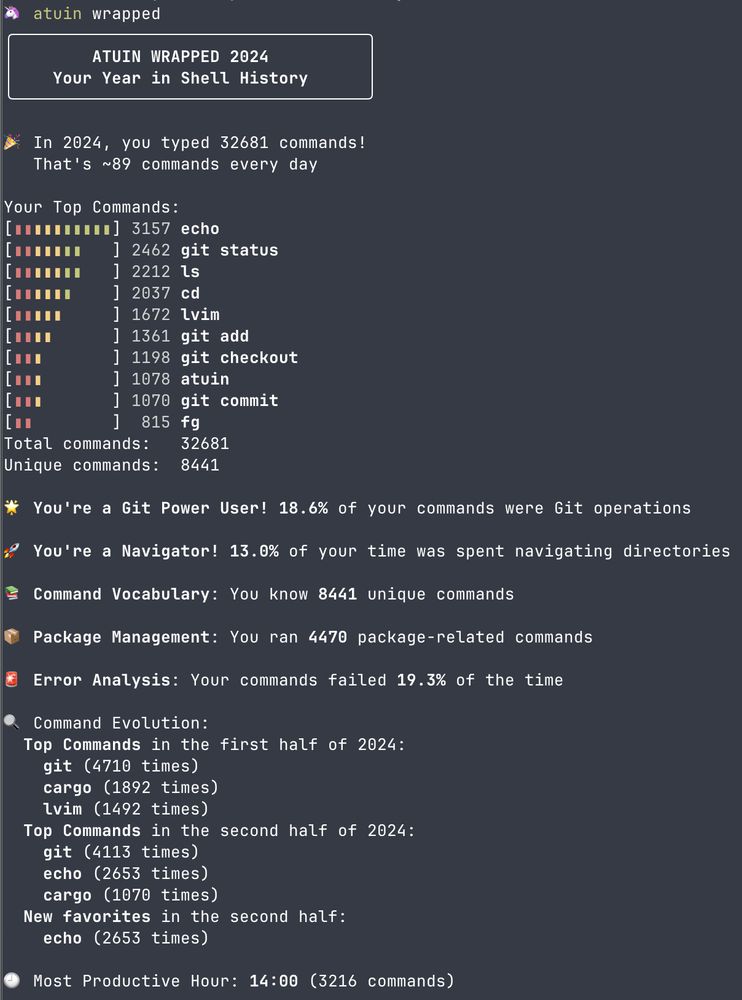
A screenshot of my Atuin wrapped, showing some fun stats about my command history in the style of "spotify wrapped"
Atuin v18.4 is out now!
Including `atuin wrapped`, your year in shell history 🐢
thanks @daveeddy.com for the suggestion!
27.12.2024 17:26 — 👍 124 🔁 21 💬 9 📌 11
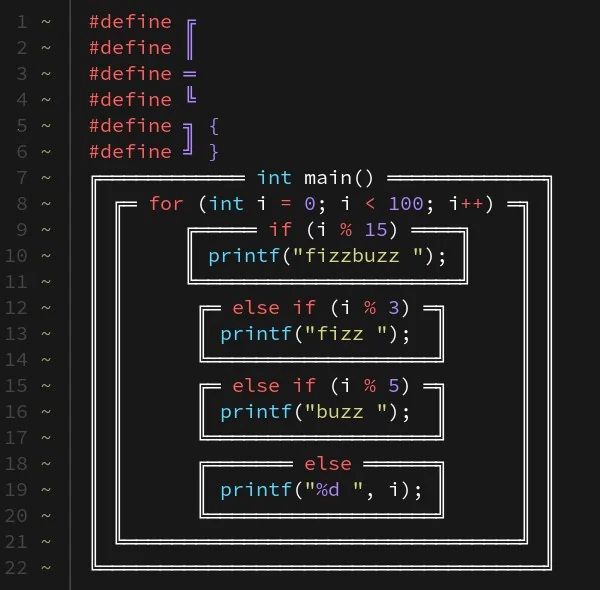
Code written with box characters used on old old software to make fake UIs
You’re still arguing about tabs vs. spaces? May I present…
25.12.2024 18:37 — 👍 5327 🔁 1293 💬 157 📌 149
Engineer by trade. Eclectic by choice.
robertroskam.com
Professor at EHESS & PSE
Co-Director, World Inequality Lab
inequalitylab.world | WID.world
http://piketty.pse.ens.fr/
Sakana AI is an AI R&D company based in Tokyo, Japan. 🗼🧠
https://sakana.ai/careers
Interested in machine learning and AI safety.
Research scientist at Snowflake; previously at FAR.AI, Google Brain, UofT & KU Leuven.
Originally a PL researcher, now ML engineer at Bardeen. EU native, US currently. Opinions are a weighted average of everyone around me (the weights are mine). Also @gcampax@mastodon.social. he/him
Software dev at Astral 🦀. Sometimes do freelance journalism: Guardian, Telegraph, openDemocracy. Python core dev in my spare time 🐍. Studied 🎶 a while back.
AI Architect | North Carolina | AI/ML, IoT, science
WARNING: I talk about kids sometimes
words and sounds and the sounds of words
🚫 https://neverpo.st 🐉 https://funcity.ventures 🪦 https://ripcorp.biz
BK NYC // rugnetta.com // posts delete regularly
Studying genomics, machine learning, and fruit. My code is like our genomes -- most of it is junk.
Assistant Professor UMass Chan, Board of Directors NumFOCUS
Previously IMP Vienna, Stanford Genetics, UW CSE.
https://ihaveeatenfoliage.substack.com
Apple ML Research in Barcelona, prev OxCSML InfAtEd, part of MLinPL & polonium_org 🇵🇱, sometimes funny
Wiadomości z Oko.press na twoim tajmlajnie.
Bot RSS projektu Polskie Niebo @plsky.eu
Pytania: @sebastian.plsky.eu
Former journalist running for Congress (IL-09) because we deserve Democrats who actually do something | katforillinois.com
Every football story that matters. Breaking news. In-depth analysis.
🔗 https://www.nytimes.com/athletic
Education leader designing immersive AI learning experiences. Shaping the future of instruction. Keynote speaker. Chair EDUCAUSE SSA Steering Committee. Accessibility Policy Committee. Reader & learner. University of Illinois Chicago UIC.
More on LinkedIn
Author, Creator
👋 Wavepal (wavepal.app)
📙 Extra Focus: The Quick Start Guide to Adult ADHD (extrafocusbook.com)
📮 Extra Focus • ADHD newsletter (extrafocus.com)
🛠️ SkyLink • Bluesky extension (skylinkchrome.com + skylinkff.com)
Mobile (KMP) and Data Engr. Interested in decentralized tech, open source ai, wasm, and proteins.
Kotlin and R enjoyoor
lead in software development | semiconductors | podcaster | starting CrossFit | growth mindset | sharing is caring!
charts and graphs
follow me on twitter https://twitter.com/norvid_studies