
EvoLM: In Search of Lost Language Model Training Dynamics
Modern language model (LM) training has been divided into multiple stages, making it difficult for downstream developers to evaluate the impact of design choices made at each stage. We present EvoLM, ...
We seek to:
✅ Build a fully transparent and reproducible model suite for studying LM training
✅ Quantify how each training phase contributes to upstream cloze task performance and downstream generative task performance, considering both in-domain and out-of-domain settings
02.07.2025 20:05 — 👍 0 🔁 0 💬 1 📌 0
EvoLM: In Search of Lost Language Model Training Dynamics
Modern language model (LM) training has been divided into multiple stages, making it difficult for downstream developers to evaluate the impact of design choices made at each stage. We present EvoLM, ...
Introducing EvoLM, a model suite with 100+ decoder-only LMs (1B/4B) trained from scratch, across four training stages —
🟦 Pre-training
🟩 Continued Pre-Training (CPT)
🟨 Supervised Fine-Tuning (SFT)
🟥 Reinforcement Learning (RL)
02.07.2025 20:05 — 👍 2 🔁 1 💬 1 📌 0
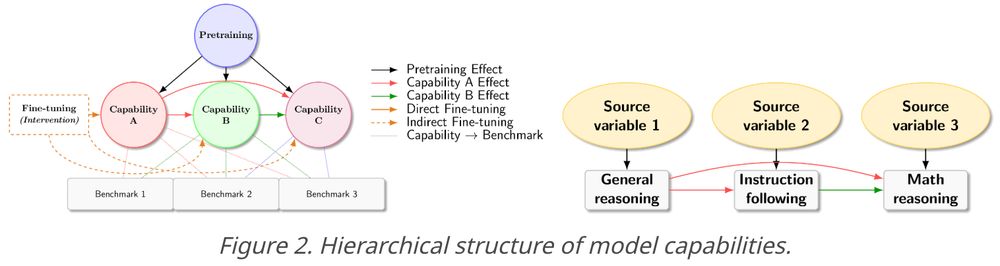
New work [JSKZ25] w/ Jikai, Vasilis,
@shamkakade.bsky.social .
We introduce new formulations and tools for evaluating LM capabilities, which help explain observations of post-training behaviors of Qwen-series models.
More details:
- hanlin-zhang.com/causal-capab...
- x.com/_hanlin_zhan...
18.06.2025 18:02 — 👍 0 🔁 0 💬 0 📌 0
Eliminating Position Bias of Language Models: A Mechanistic Approach
Position bias has proven to be a prevalent issue of modern language models (LMs), where the models prioritize content based on its position within the given context. This bias often leads to unexpecte...
[3/4] LMs can suffer from position bias—they favor content based on where it appears. This can hurt reasoning and evaluation.
We introduce PINE, a training-free method that eliminates position bias via bidirectional attention+reordering docs by attention scores.
(arxiv.org/abs/2407.01100)
23.04.2025 01:35 — 👍 0 🔁 0 💬 1 📌 0

How the von Neumann bottleneck is impeding AI computing
The von Neumann architecture, which separates compute and memory, is perfect for conventional computing. But it creates a data traffic jam for AI.
[1/4] Modern large-scale LM training is limited not just by compute, but by data movement—a classic Von Neumann bottleneck (research.ibm.com/blog/why-von...).
Scaling batch size reduces optimization steps, but only up to a point—the Critical Batch Size (CBS).
23.04.2025 01:35 — 👍 0 🔁 0 💬 1 📌 0
Highlights from #ICLR2025 — a brief thread 🧵
23.04.2025 01:35 — 👍 1 🔁 0 💬 1 📌 0
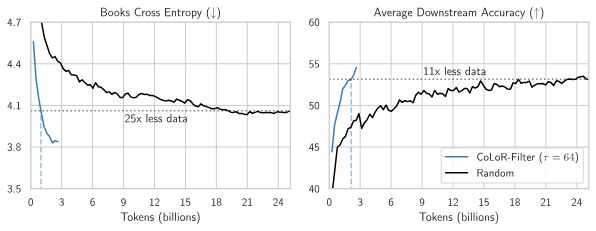
I want to reshare @brandfonbrener.bsky.social's @NeurIPSConf 2024 paper on CoLoR-Filter: A simple yet powerful method for selecting high-quality data for language model pre-training!
With @hlzhang109.bsky.social @schwarzjn.bsky.social @shamkakade.bsky.social
05.04.2025 12:04 — 👍 17 🔁 8 💬 2 📌 1
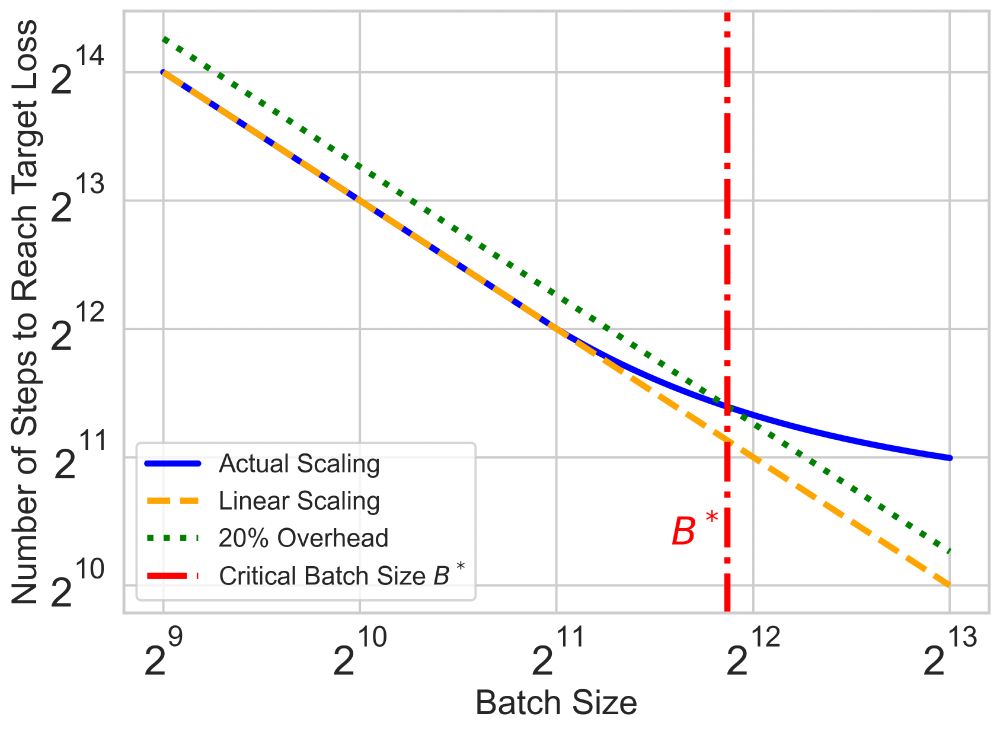
(1/n) 💡How can we speed up the serial runtime of long pre-training runs? Enter Critical Batch Size (CBS): the tipping point where the gains of data parallelism balance with diminishing efficiency. Doubling batch size halves the optimization steps—until we hit CBS, beyond which returns diminish.
22.11.2024 20:19 — 👍 16 🔁 4 💬 2 📌 0
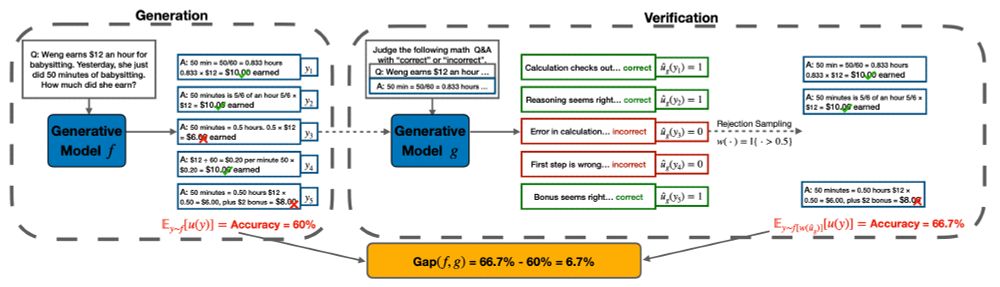
LLM self-improvement has critical implications in synthetic data, post-training and test-time inference. To understand LLMs' true capability of self-improvement, we perform large-scale experiments with multiple families of LLMs, tasks and mechanisms. Here is what we found: (1/9)
06.12.2024 18:02 — 👍 12 🔁 4 💬 1 📌 1
https://miguelhernan.org/
Using health data to learn what works.
Making #causalinference less casual.
Director, @causalab.bsky.social
Professor, @hsph.harvard.edu
Methods Editor, Annals of Internal Medicine @annalsofim.bsky.social
My opinions only here.
👨🔬 RS DeepMind
Past:
👨🔬 R Midjourney 1y 🧑🎓 DPhil AIMS Uni of Oxford 4.5y
🧙♂️ RE DeepMind 1y 📺 SWE Google 3y 🎓 TUM
👤 @nwspk
PhD student with the Harvard ML Foundations group.
ML/AI researcher & former stats professor turned LLM research engineer. Author of "Build a Large Language Model From Scratch" (https://amzn.to/4fqvn0D). Blogging about AI research at magazine.sebastianraschka.com.
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Distinguished Scientist at Google. Computational Imaging, Machine Learning, and Vision. Posts are personal opinions. May change or disappear over time.
http://milanfar.org
Associate Professor at Princeton
Machine Learning Researcher
Researcher and CIFAR Fellow, working on the intersection of machine learning and neuroscience in Montréal at @mcgill.ca and @mila-quebec.bsky.social.
AI professor at Caltech. General Chair ICLR 2025.
http://www.yisongyue.com
AI safety at Anthropic, on leave from a faculty job at NYU.
Views not employers'.
I think you should join Giving What We Can.
cims.nyu.edu/~sbowman
I work at Sakana AI 🐟🐠🐡 → @sakanaai.bsky.social
https://sakana.ai/careers
a mediocre combination of a mediocre AI scientist, a mediocre physicist, a mediocre chemist, a mediocre manager and a mediocre professor.
see more at https://kyunghyuncho.me/
source: https://arxiv.org/rss/stat.ML
maintainer: @tmaehara.bsky.social
Computer science, math, machine learning, (differential) privacy
Researcher at Google DeepMind
Kiwi🇳🇿 in California🇺🇸
http://stein.ke/
Professor and Head of Machine Learning Department at Carnegie Mellon. Board member OpenAI. Chief Technical Advisor Gray Swan AI. Chief Expert Bosch Research.
Mathematician at UCLA. My primary social media account is https://mathstodon.xyz/@tao . I also have a blog at https://terrytao.wordpress.com/ and a home page at https://www.math.ucla.edu/~tao/
Professor, Stanford University, Statistics and Mathematics. Opinions are my own.
Professor at Penn, Amazon Scholar at AWS. Interested in machine learning, uncertainty quantification, game theory, privacy, fairness, and most of the intersections therein




















