
Bombing of Dresden - Wikipedia
100000t of bombs vs the civilian casualty rates in Gaza actually shows that the IDF went out of their way to protect the civilian population
Compare this to, I dunno, the Dresden bomb raids:
25000 deaths over 4 days from just 3900t of bombs
Was that genocide?
en.m.wikipedia.org/wiki/Bombing...
29.06.2025 08:25 —
👍 0
🔁 0
💬 0
📌 0
Lol this fake statistician has blocked me for calling out his stupidity 😅
29.06.2025 08:20 —
👍 0
🔁 0
💬 0
📌 0

Because the urban warfare during the counterinsurgency, 60% of the buildings were destroyed during fighting in the course of a couple of months. This is in line with the report you cited above.
How is this war in Gaza different to that war?
en.m.wikipedia.org/wiki/Falluja...
29.06.2025 08:19 —
👍 0
🔁 0
💬 1
📌 0
Did the US also commit genocide in Iraq?
28.06.2025 21:56 —
👍 0
🔁 0
💬 1
📌 0
The Gedankenexperiment says they must be doing a pretty terrible job if this is supposed to be a genocide 🙄
28.06.2025 20:57 —
👍 0
🔁 0
💬 3
📌 0
x.com/BlackHC/stat...
Some thoughts on the comment paper
13.06.2025 11:35 —
👍 0
🔁 0
💬 0
📌 0
CoverDrop: Blowing the Whistle Through A News App
We launched CoverDrop 🎉 providing sources with a secure and anonymous way to talk to journalists. Having started five years ago as a PhD research project, this now ships within the Guardian app to millions of users—all of which provide cover traffic. Paper, code, and more info: www.coverdrop.org
09.06.2025 13:00 —
👍 59
🔁 20
💬 1
📌 1
This is going to be big news in my field. While we wait for the dataset, the stuff about post-processing makes interesting reading (if you're me)
11.06.2025 20:07 —
👍 72
🔁 13
💬 4
📌 0
Oh yeah I can't believe ai generated ASMR is also taking off. I've seen one or two of those!
11.06.2025 21:09 —
👍 0
🔁 0
💬 0
📌 0
What's your favorite Veo video?
11.06.2025 16:44 —
👍 0
🔁 0
💬 1
📌 0
Yeah but that's where most of the interesting things are 😅
11.06.2025 16:43 —
👍 0
🔁 0
💬 0
📌 0
I hope the authors (I QT'ed @MFarajtabar above) can revisit the Tower of Hanoi results and examine the confounders to strengthen the paper (or just drop ToH). This will help keep the focus on the more interesting other environments for which the claims in the paper seem valid 🙏
09.06.2025 21:49 —
👍 6
🔁 0
💬 0
📌 0
And other influencers exaggerate its results massively:
x.com/RubenHssd/s...
09.06.2025 21:49 —
👍 1
🔁 0
💬 1
📌 0

A knockout blow for LLMs?
LLM “reasoning” is so cooked they turned my name into a verb
So thinks are not as bleak as the coverage makes them sound. Aprospos coverage: here are some glowing reviews of the paper that do not question it:
Of course, @GaryMarcus likes it very much:
garymarcus.substack.com/p/a-knockou...
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0

I want to point to one more claim which is already outdated (the relevant paper was only published a few days ago so hardly anyone's fault):
The ProRL paper by Nvidia has shown that RL-based models can truly learn new things - if you run RL long enough!
arxiv.org/abs/2505.24864
09.06.2025 21:49 —
👍 3
🔁 0
💬 1
📌 0
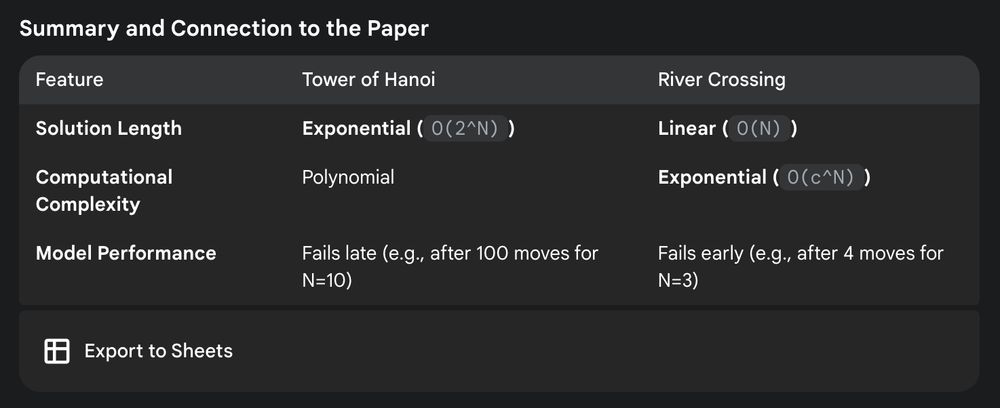
But as Gemini 2.5 Pro explains, River Crossing's optimal solutions are rather short, but they have a high branching factor and number of possible states with dead-ends.
That models fail here is a lot more interesting and points towards areas of improvements.
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
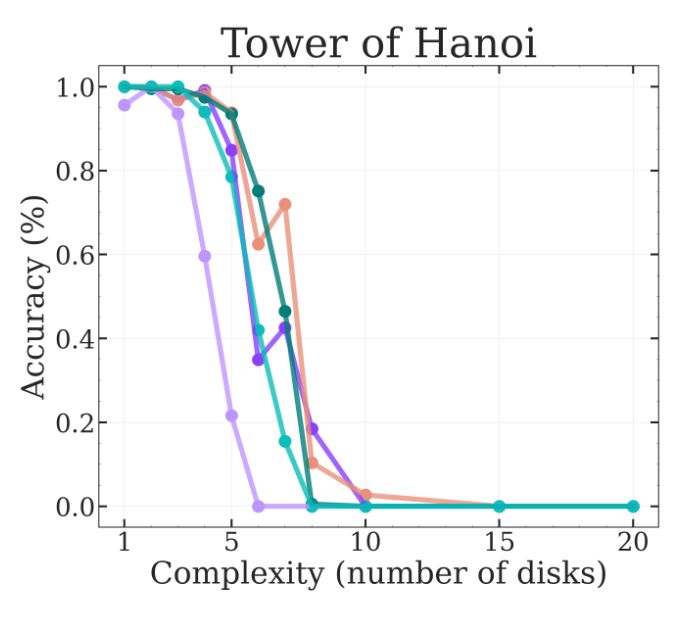
All in all, the Tower of Hanoi results cannot be given any credence because it seems there are many confounders and simpler explanations.
However, I don't think the other games hit the same issues. If we look at River Crossing it seems to hit high token counts very quickly:
09.06.2025 21:49 —
👍 1
🔁 0
💬 1
📌 0
Thus, @scaling01 calls out their conclusion: it looks like they didn't pay as close attention to the model's reasoning traces as they have claimed 😬
x.com/scaling01/s...
09.06.2025 21:49 —
👍 1
🔁 0
💬 1
📌 0
This can also be observed in other simpler non-reasoning tasks:
x.com/Afinetheore...
09.06.2025 21:49 —
👍 1
🔁 0
💬 1
📌 0
New LRMs are actually trained to be aware of their token limits. If they cannot think there way through, they find other solutions.
Apparently, the models say so at N=9 in ToH or refuse the write out the whole solution "by hand" and write code instead:
x.com/scaling01/s...
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
Another "counterintuitive" behavior that is reported that the models start outputting fewer thinking tokens as the problems get more complex (e.g., more disks in Tower of Hanoi).
But again, this can be explained away sadly for ToH (but only ToH!).
x.com/MFarajtabar...
09.06.2025 21:49 —
👍 1
🔁 0
💬 1
📌 0
Because, wait, it gets worse:
For N >= 12 or 13 disks, the LRM could not even output all the moves for the solution even if it wanted because the models can only output 64k tokens. Half of the plots of the ToH are essentially meaningless anyway.
x.com/scaling01/s...
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
This is very important: we do not need the LRM to be bad at reasoning for this to happen.
It just happens because the correct solution is so long and is not allowed to contain any typos.
(IMO the paper should really consider dropping the ToH environment from their results.)
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
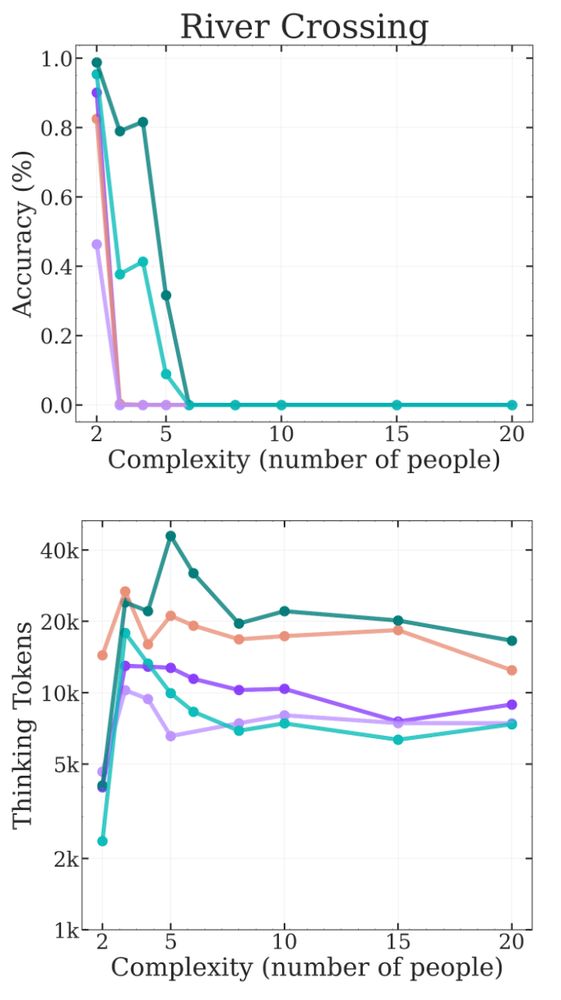
It assumes the LLM samples the correct token with a given (high) probability and looks at the required number of tokens we need to output all the moves. Then:
p("all correct") = p**(2^N - 1)
and p=0.999 matches the ToH results in the paper above.
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
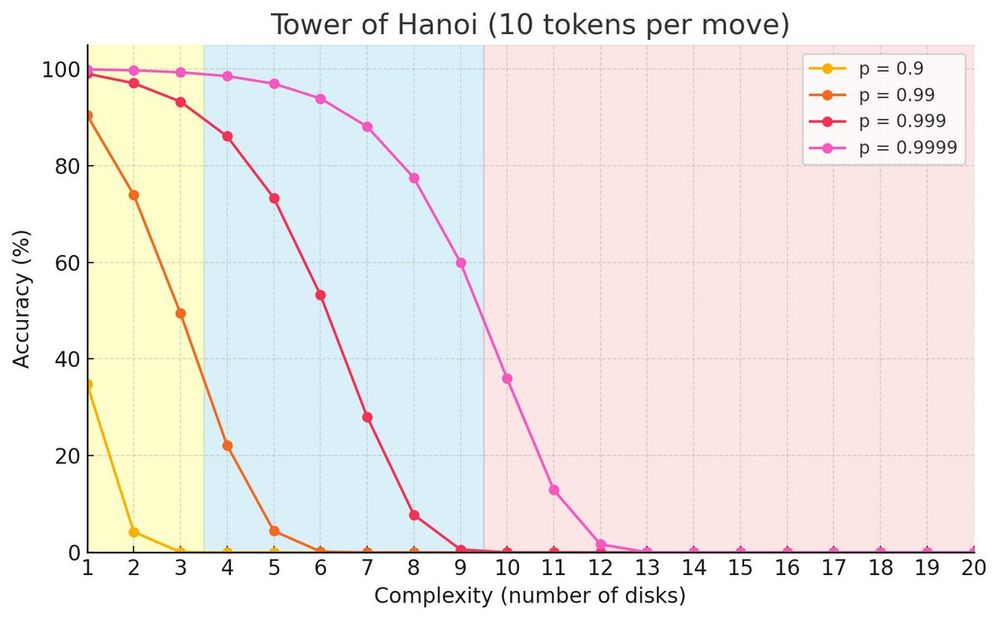
We use top-p or top-k sampling with a temperature of 0.7 after all. Thus, there is a chance the model gets unlucky and the wrong token is sampled, resulting in failure. (They should really try min-p 😀)
@scaling01 has a nice toy model that matches the paper results:
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
This also explains away why telling LRMs the ToH algorithm makes little difference in their performance: they already know how to solve the game.
The problem is writing out e.g. 2**10 - 1 = 1023 steps without any mistake while being sampled!
x.com/MFarajtabar...
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
This already explains away the earlier noted surprise that is also mentioned in the paper and in the open questions:
x.com/scaling01/s...
09.06.2025 21:49 —
👍 1
🔁 0
💬 1
📌 0
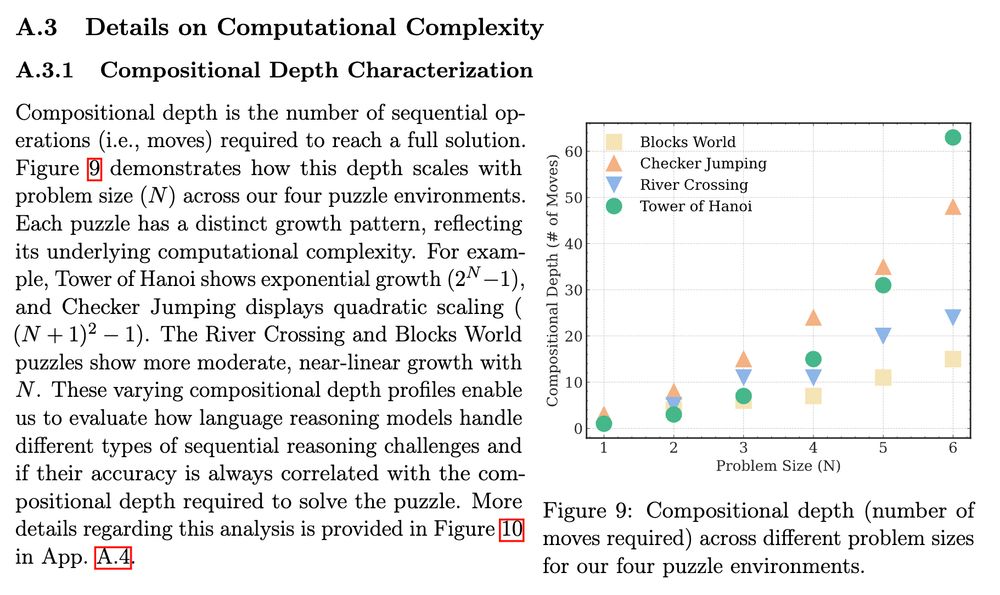
Otoh, Tower of Hanoi is rather straightforward. BUT it requires many steps (2^N - 1, where N is the number of disks). LLMs already know the optimal algorithm to solve it, so the only problem is writing out all those steps! Performing well on ToH is not about reasoning at all 🫠
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
Somehow the authors were not aware or did not reflect on the actual complexity of the games. As @scaling01 points out via o3, River Crossing is actually harder to solve because it has a large branching factor and high chance of ending up in dead ends
x.com/scaling01/s...
09.06.2025 21:49 —
👍 3
🔁 0
💬 1
📌 0
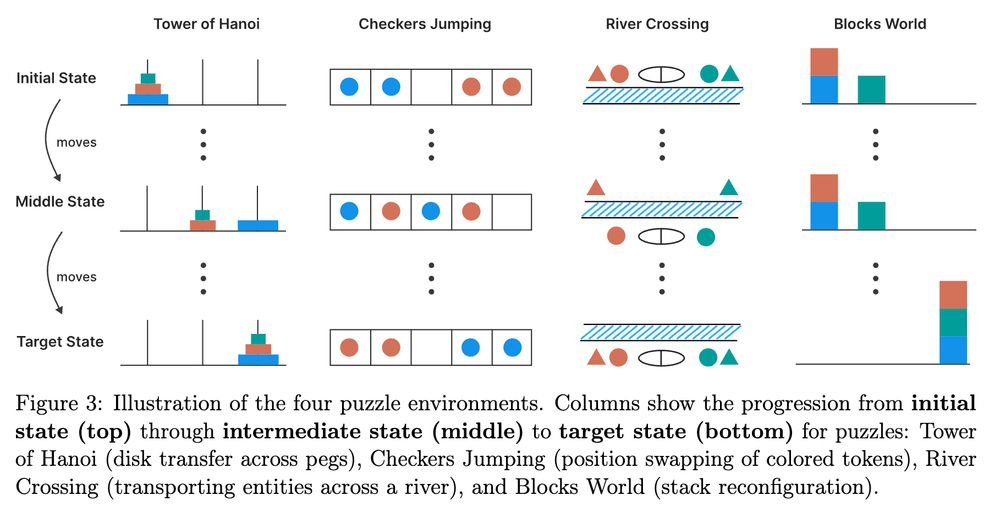
The paper explores four puzzle environments: Tower of Hanoi, Checkers Jumping, River Crossing, and Blocks World.
It finds some "surprising" behavior of LRMs: they can perform 100 correct steps on the Tower of Hanoi, but only 4 steps on River Crossing.
x.com/MFarajtabar...
09.06.2025 21:49 —
👍 2
🔁 0
💬 1
📌 0
