Do swiss universities expect permanent SNF funding? I thought you still had a basic funding model in place, no?
02.02.2026 10:59 — 👍 0 🔁 0 💬 1 📌 0

Short announcement before the data get too old: ccsmainz.github.io/platformnews/. With 571 news outlets on TikTok, YouTube Shorts, and Instagram across 46 countries, matching the @reutersinstitute.bsky.social DNR. Computational analyses on topics, platformization, diversity, etc. Feedback welcome.
23.01.2026 13:40 — 👍 15 🔁 5 💬 0 📌 1

Künstliche Intelligenz in der Begutachtung
DFG erlaubt Einsatz von KI in der Begutachtung.
Wenn wir jetzt noch die AI dazu kriegen, die komplette Forschung zu machen, haben wir den Menschen komplett von der Last des Forschungsprozzeses befreit und er kann sich komplett auf wichtige Dinge wie Reisekostenerstattungsanträge konzentrieren.
08.01.2026 10:16 — 👍 617 🔁 196 💬 19 📌 53
Wondering whether the Michelangelo sauce is based on the artist or the hero turtle and how. 🤔
05.01.2026 11:31 — 👍 2 🔁 0 💬 1 📌 0
PostDoc in CSS / CCS (m/w/d)
📍 Location: Munich
📅 Start: 1 Apr 2026
⏳ Apply by: 31 Jan 2026
Details:
German: job-portal.lmu.de/jobposting/6...
English: job-portal.lmu.de/jobposting/7...
12.12.2025 06:47 — 👍 6 🔁 6 💬 0 📌 2
SKULL OF THOMAS AQUINAS: TAKE A LEFT NOW
PRIEST: No, the GPS says we have to keep going—
SKULL: I KNOW A SHORTCUT
PRIEST: Do you remember the last ti—
SKULL: FOR THOSE WITH FAITH, NO EVIDENCE IS NECESSARY; FOR THOSE WITHOUT IT, NO EVIDENCE WILL SUFFICE
10.12.2025 17:10 — 👍 13607 🔁 4860 💬 108 📌 227

screenshot of my post
Big new blogpost!
My guide to data visualization, which includes a very long table of contents, tons of charts, and more.
--> Why data visualization matters and how to make charts more effective, clear, transparent, and sometimes, beautiful.
www.scientificdiscovery.dev/p/salonis-gu...
09.12.2025 20:28 — 👍 800 🔁 317 💬 22 📌 50
Happy "let's circle back in the New Year" season to all who celebrate.
01.12.2025 13:14 — 👍 344 🔁 99 💬 5 📌 12

PAUSE sign
1. Pausing new submissions about AI topics for 90 days. That is, papers about AI models, testing AI models, proposing AI models, theories about the future of AI, etc. We will make exceptions for papers that are already accepted for publication (or published) in peer-reviewed scholarly journals
/2
27.11.2025 14:54 — 👍 102 🔁 21 💬 2 📌 7
🚨New Publication Alert 🚨"Gender diversity in the field of communication in Germany, Austria, Switzerland". 3 Studies in 1 Paper! We analyzed the scientific job market, publications, citations, and grants! Available open access: doi.org/10.1007/s116... [English]. German summary in 🧵 #commSky
06.11.2025 13:52 — 👍 2 🔁 2 💬 1 📌 1
There are some track features you can get, like runtime or explicit lyrics, but the interesting ones like key, bpm or danceability are part of the audio features API which has been disabled since last year (developer.spotify.com/blog/2024-11...). DDP+Track analysis could still be very interesting.
29.10.2025 10:46 — 👍 1 🔁 0 💬 0 📌 0
I tried to do this in my computational methods class this spring and it turned out the most of the Spotify tracks/music API is now disabled, so you cannot easily get matching song-level data anymore, except from large dumps of popular songs, or by using alternative APIs using artist/title.
28.10.2025 14:45 — 👍 0 🔁 0 💬 1 📌 0
For a second I was really impressed that @richardfletcher.bsky.social brought out HUGE cardboard printouts for his slides ;-)
09.10.2025 15:10 — 👍 2 🔁 0 💬 1 📌 0
I'd argue that BA/MA theses don't need to be informative re an actual research question, but only inform us whether students actually learned something. Of course, running naive studies with tiny self-selected or convenience samples isn't helping the students in that regard either.
01.10.2025 06:11 — 👍 5 🔁 0 💬 1 📌 0

Zwei männliche und eine weibliche Silhouette. Im Vordergrund Mikrophone wie bei einer Pressekonferenz
🔥Hot off the press: Studie zur Repräsentation weiblicher Forschender in den Medien 👉
doi.org/10.1177/0963...
📰 Inhaltsanalyse: 4.860 Medienartikel
👩🔬 Nur 18% der zitierten Expert:innen sind Frauen
📊 Frauenanteil in der Forschung: ca. 31%
➡️ Deutliche Sichtbarkeitslücke für weibliche Forschende
08.09.2025 10:06 — 👍 13 🔁 9 💬 1 📌 1


This year, I am living in a simulation - literally. 🌀
@mscharkow.bsky.social, and I are currently conducting a #simulation study on how users interact with algorithms in short-video environments such as #TikTok. I’ve had two incredible opportunities to share our progress so far.
11.07.2025 13:02 — 👍 9 🔁 5 💬 1 📌 0

Our Digital News Report 2025 is out!
📊48 markets
🌏Almost 100K respondents
📰Key headline: Audiences lean into video news and influencers, raising misinformation concerns and new dilemmas for publishers
📱Explore now buff.ly/xLP67Tg
🧵Findings in thread #DNR25
17.06.2025 05:03 — 👍 94 🔁 81 💬 2 📌 25
Interesting. Do the funders provide reasons for this requirement, ie are they science-related or legal? In many ethics/IRB (equivalent) discussions I've had in the past, it seemed that collecting less demographic information seemed to be preferable in general for privacy/data protection reasons.
25.03.2025 20:49 — 👍 2 🔁 0 💬 1 📌 0
What happens if you have NA in your demographics? Do papers get rejected if the reported mean age is based on 73% of the sample? I get the warmup argument, but why not warm up with motivating items? If however, your experiment's primary outcome is age or gender, put that item in ASAP ;-)
25.03.2025 19:44 — 👍 0 🔁 0 💬 1 📌 0
This is also what I learned and continue to teach. Sociodemographics rarely a predictor (or outcome!) of interest, at least in my courses...
25.03.2025 19:11 — 👍 4 🔁 0 💬 1 📌 0
SoSci Survey ‣ Onlinebefragung vielseitig und DSGVO-konform
SoSci Survey - professionelle Onlinebefragung einfach, schnell, flexibel, sicher - für den nicht-kommerziellen Einsatz ein kostenloser Onlinefragebogen
I am a big fan of www.soscisurvey.de The basics are free anyway but university licenses of various types including for own servers exist as well, I think psychology at UZH even has one.
Plus, I've had very good experiences with support as well.
13.02.2025 15:06 — 👍 11 🔁 3 💬 1 📌 0
Good and timely stuff! I wonder how we can navigate the (very real) tradeoff between quality and reproducibility. Will reviewer #2 accept a drop of .2 in accuracy between gpt/gemini vs. local models if you make this decision transparent? What if results change? Just add another robustness check?
17.12.2024 20:20 — 👍 2 🔁 0 💬 0 📌 0

LimeWire Wrapped
1. sistem_of_a_dowm_Zelda_song.flac
2. Nirvana - Glycerine.flv
3. track_8_(1)_(1)c.mp3
4. weird_al_Bert_and_Big_Bird_smoking_weed_FUNNY(parody).wav
5. jay-z_the-blueprint_FULL ALBUM_REAL.mp3.exe
finally finished downloading my limewire wrapped after 20 years
04.12.2024 21:11 — 👍 25940 🔁 4911 💬 369 📌 284
If you think of time as a sampling dimension (which we often do in many other contexts), it's not even a metaphorical population, but an occasion-specific sample. Which is also argued in the above literature regarding country-year data.
03.12.2024 14:30 — 👍 3 🔁 0 💬 0 📌 0
Not to be confused with Schöpfungshöhenselbstzweifel!
03.12.2024 14:11 — 👍 2 🔁 0 💬 0 📌 0
I sense a strong nudge to never reject anything 🤗
03.12.2024 14:09 — 👍 1 🔁 0 💬 1 📌 0

Wiener weniger unfreundlich
Das Image der Wiener Bevölkerung, besonders unfreundlich zu sein, hat sich leicht verbessert. Im vergangenen Jahr noch auf dem letzten Platz von 53 internationalen Städten, liegt Wien in Sachen Freund...
Laut Studie ist Wien nicht mehr die unfreundlichste Stadt, sondern Berlin und München sind besser als wir. Es bringt nichts, irgendeinen Sündenbock zu suchen. Wir alle müssen jetzt reflektieren, wo wir im vergangenen Jahr Fehler gemacht haben könnten.
22.11.2024 08:02 — 👍 1186 🔁 205 💬 101 📌 86
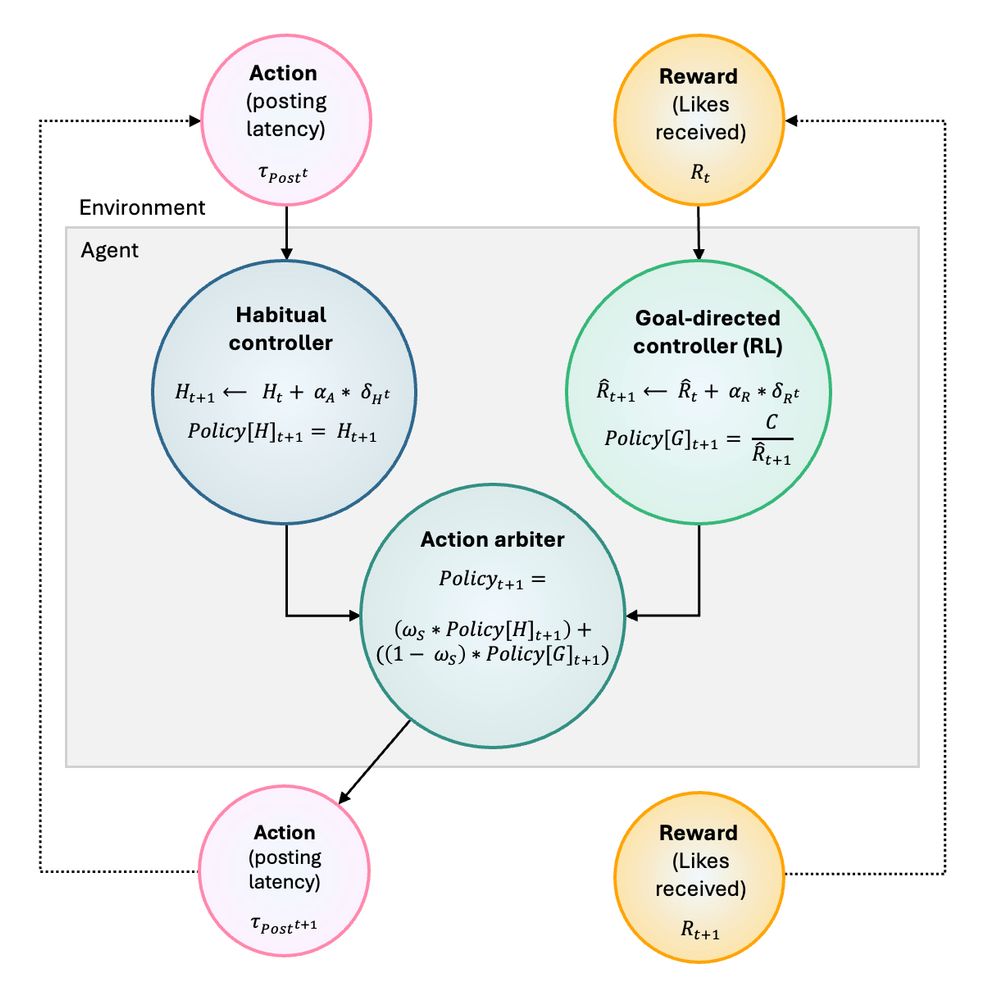
🚨New preprint 🚨
**A computational model of reward learning and habits on social media**
🧵
We develop a computational reward learning model of real-world social media data, which infers the separate goal-directed and habitual cognitive processes driving posting...
13.11.2024 11:01 — 👍 78 🔁 27 💬 4 📌 3
Made the CommSky Starter Pack https://go.bsky.app/QkcgePD
Assistant Professor at Syracuse. I study public relations, military esports, video games, and gender theory. Happily 🏳️🌈.
Public policy professor at the Hobby School. Enthusiastic about food, dogs, travel, and research. I write books about many failures of local democracy. Bad opinions my own.
Associate Professor at UMass Amherst studying the civic impacts of media distribution. I work in our Journalism Department and also co-edit the Distribution Matters series for The MIT Press.
Mastodon: @josh@sciences.social
Banner text by F.E.D McDowell
Assistant Professor studying sports-related media and journalistic professionalism at UW-Milwaukee. Aspiring boat guy.
Assistant professor of practice at the Edward R. Murrow College of Comm. Research in the intersection of women’s sport, social media & branding.Cofounder of Starting Line 1928. #commsky
Assistant Professor at University of Evansville.
I study emerging tech, representation & professionalism in journalism.
Associate Professor in Internet Governance at Maastricht University | Internet censorship | Platform governance | Russian politics & political communication
Member of The Young Academy (KNAW)
Academic editor @policyr.bsky.social
Instructor in Interactive Media and Ed.D. student at MTSU. Co-founder of Craft Content Nashville and Content Economy Nashville. Host of Artisanal Insights pod and co-host of #CnCShow. Ex-pat yinzer. Toddler mom. She/her.
Dir. of Global Partnerships, Inst. for Information, the Internet & Democracy, NEU | Union of Concerned Scientists 2024 Defender of Science |
Co-founder: https://researchersupport.org/
https://expertvoicestogether.org/
https://independenttechresearch.org/
Prof @ Wesleyan U; Co-Director of WesMediaProject (@wesmediaproject.bsky.social & mediaproject.wesleyan.edu); policomm, polisci, public opinion & health policy scholar; member of Collaborative on Media & Messaging for Health & Social Policy (commhsp.org)
FAU Journalism Prof and UFF-FAU Steward, political communication & digital media // The Press and Democratic Backsliding from Lexington Books, LXFANDF30 for 30% off // he/him
manytoomany.com
scholar.google.com/citations?user=-KlefNYAAAAJ
Log off.
-assoc prof of strategic comm at Arizona State University
-current editor of Comm Research Reports
-👨🔬🏀☕
Associate Professor of Communication & Sociology at Northwestern University. Executive Director of the Center for Applied Transgender Studies. Author of Voices for Transgender Equality: Making Change in the Networked Public Sphere (Oxford UP, 2024).
Russia, Eurasia, nationalism, propaganda, autocracy
Journalism and Mass Communication Quarterly (JMCQ) is the flagship journal of the Association for Education in Journalism and Mass Communication (AEJMC)
interpersonal & critical health comm phd candidate @ illinois, gratitude fellow @ the love consortium, affiliate @ unc citap, & co-managing editor @ sex & psych
studying mediated intimate relationships & more
https://www.emilymendelson.com
Brasileiro. Inconstant poster in English and Portuguese. Assistant Professor of Media and Democracy at the University of Maryland's Philip Merrill College of Journalism.
https://danieltrielli.com
Teaching Professor of Communication Studies at Northeastern University. Wrestling, Pop Culture, #BillsMafia #commsky
Deliberation, democracy & public engagement scholar #TeamRhetoric #Commsky politics in US & #CEE #transportation, public memory, Town Meeting. Lifter. Vlach/Aromanian #WMASS @TownModerator.bsky.social
Prof of Comm & Media and Polisci @UMich studying how people get & use political information and social measurement.
Competencies: data sci, DIY solar, election analytics, carpooling, #polcom, #polpsych, survey methods, AI literacy (views are my own)






















