Joint work with @natalieshapira.bsky.social, @arnabsensharma.bsky.social, @criedl.bsky.social, @boknilev.bsky.social, @tamarott.bsky.social, @davidbau.bsky.social, and Atticus Geiger.
24.06.2025 17:15 — 👍 1 🔁 0 💬 0 📌 0
We expect Lookback mechanism to extend beyond belief tracking - the concept of marking vital tokens seems universal across tasks requiring in-context manipulation. This mechanism could be fundamental to how LMs handle complex logical reasoning with conditionals.
24.06.2025 17:15 — 👍 0 🔁 0 💬 1 📌 0
We found that the LM generates a Visibility ID at the visibility sentence which serves as source info. Its address copy stays in-place, while a pointer copy flows to later lookback tokens. There, a QK-circuit dereferences the pointer to fetch info about the observed character as payload.
24.06.2025 17:15 — 👍 1 🔁 0 💬 1 📌 0

Next we studied how providing explicit visibility condition affects characters' beliefs.
24.06.2025 17:14 — 👍 0 🔁 0 💬 1 📌 0

We test our high-level causal model with targeted interventions:
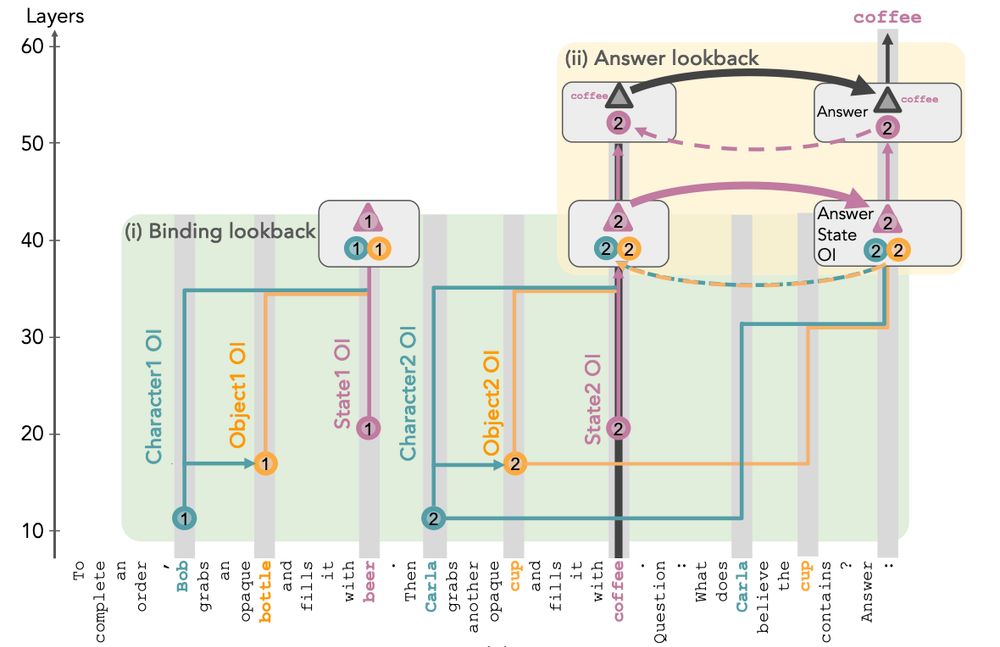
- Patching the answer lookback pointer flips the final output from coffee to beer (pink line)
- Patching the answer lookback payload shifts it from coffee to tea (grey line)
Strong evidence that the Answer Lookback mechanism is real!
24.06.2025 17:14 — 👍 0 🔁 0 💬 1 📌 0
Step 3: The LM now uses the state OI at the last token as a pointer and its in-place copy as an address to look back to the correct token, this time fetching its token value (e.g., "beer") as the payload, which gets predicted as the final output.
24.06.2025 17:14 — 👍 0 🔁 0 💬 1 📌 0
Step 2: The LM binds the character-object-state triplet by copying their OIs (source) to the state token. These OIs also flow to the last token via corresponding tokens in the query (pointer). Next, LM uses both copies to attend to the correct state from last token and fetch its state OI (payload).
24.06.2025 17:14 — 👍 0 🔁 0 💬 1 📌 0
Step 1: LM maps each vital token (character, object, state) to an abstract Ordering ID (OI), a reference that marks it as the first or second of its type, regardless of the actual token.
24.06.2025 17:14 — 👍 0 🔁 0 💬 1 📌 0
Using the Causal Abstraction framework, we formulated a precise hypothesis that explains the end-to-end mechanism the model uses to perform this task.
24.06.2025 17:14 — 👍 0 🔁 0 💬 1 📌 0
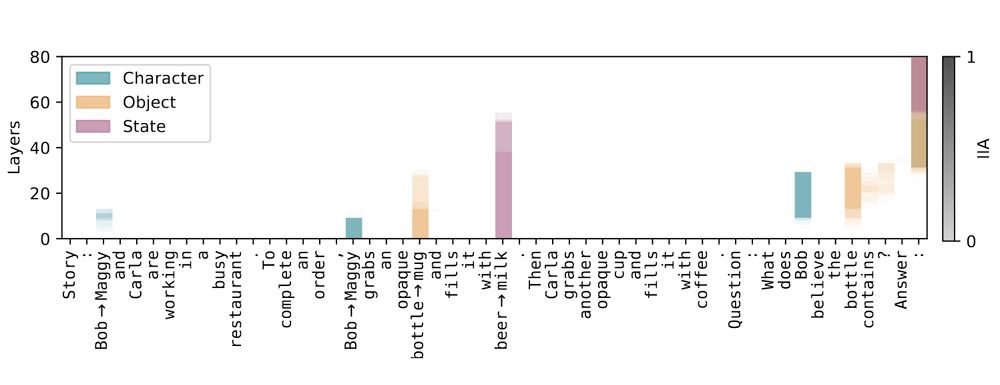
Tracing key tokens shows that the correct state (e.g., beer) flows directly to the final token at later layers. Meanwhile, info about the query character and object is retrieved from earlier mentions and passed to the final token before being replaced by the correct state token.
24.06.2025 17:14 — 👍 1 🔁 0 💬 1 📌 0
Here is how it works: the model duplicates key info across two tokens, letting later attention heads look back at earlier ones to retrieve it, rather than passing it forward directly. Like leaving a breadcrumb trail in context.
24.06.2025 17:14 — 👍 1 🔁 0 💬 1 📌 0
We discovered "Lookback" - a mechanism where language models mark important info while reading, then attend back to those marked tokens when needed later. Since LMs don't know what info will be relevant upfront, this lets them efficiently retrieve key details on demand.
24.06.2025 17:13 — 👍 1 🔁 0 💬 1 📌 0

We constructed CausalToM, a dataset for causal analysis, featuring simple stories where two characters each separately change the state of two objects, potentially unaware of each other's actions. We ask Llama-3-70B-Instruct to reason about a character’s beliefs regarding the state of an object. Eg.
24.06.2025 17:13 — 👍 1 🔁 0 💬 1 📌 0
Since Theory of Mind (ToM) is fundamental to social intelligence numerous works have benchmarked this capability of LMs. However, the internal mechanics responsible for solving (or failing to solve) such tasks remains unexplored...
24.06.2025 17:13 — 👍 2 🔁 0 💬 1 📌 0

How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
24.06.2025 17:13 — 👍 54 🔁 19 💬 2 📌 1













