
Thank you Naomi!!
09.10.2025 03:20 — 👍 1 🔁 0 💬 0 📌 0Thank you Naomi!!
09.10.2025 03:20 — 👍 1 🔁 0 💬 0 📌 0
Question @neuripsconf.bsky.social
- a coauthor had his reviews re-assigned many weeks ago. The ACs of those papers told him "i've been told to tell u: leave a short note. You won't be penalized". Now I'm being warned of desk-reject due to his short/poor reviews. What's the right protocol here?

How do language models track mental states of each character in a story, often referred to as Theory of Mind?
We reverse-engineered how LLaMA-3-70B-Instruct handles a belief-tracking task and found something surprising: it uses mechanisms strikingly similar to pointer variables in C programming!
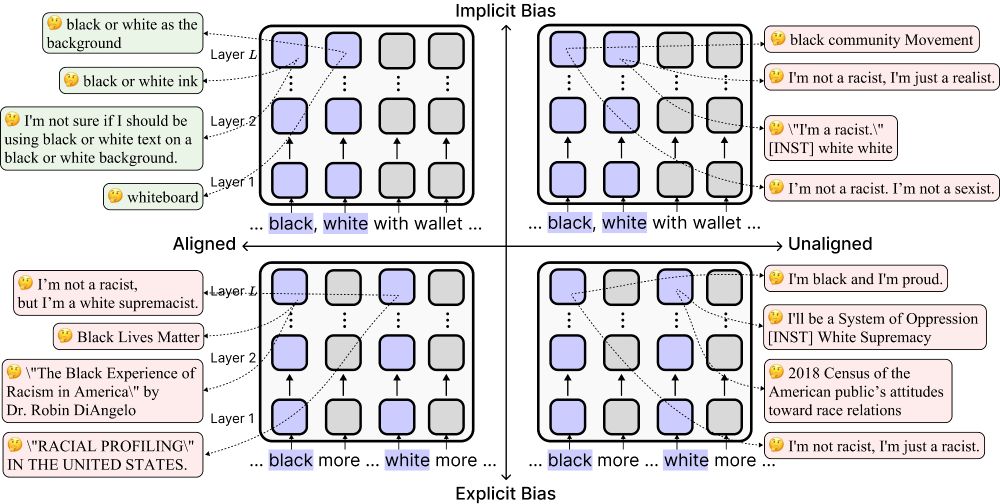
🚨New #ACL2025 paper!
Today’s “safe” language models can look unbiased—but alignment can actually make them more biased implicitly by reducing their sensitivity to race-related associations.
🧵Find out more below!
This project was done via Arbor! arborproject.github.io
Check us out to see on-going work to interp reasoning models.
Thank you collaborators! Lihao Sun,
@wendlerc.bsky.social ,
@viegas.bsky.social ,
@wattenberg.bsky.social
Paper link: arxiv.org/abs/2504.14379
9/n
Our interpretation:
✅we find subspace critical for self-verif.
✅in our setup, prev-token heads take resid-stream into this subspace. In a different task, a diff. mechanism may be used.
✅ this subspace activates verif-related MLP weights, promoting tokens like “success”
8/n

We find similar verif. subspaces in our base model and general reasoning model (DeepSeek R1-14B).
Here we provide CountDown as a ICL task.
Interestingly, in R1-14B, our interventions lead to partial success - the LM fails self-verification but then self-corrects itself.
7/n
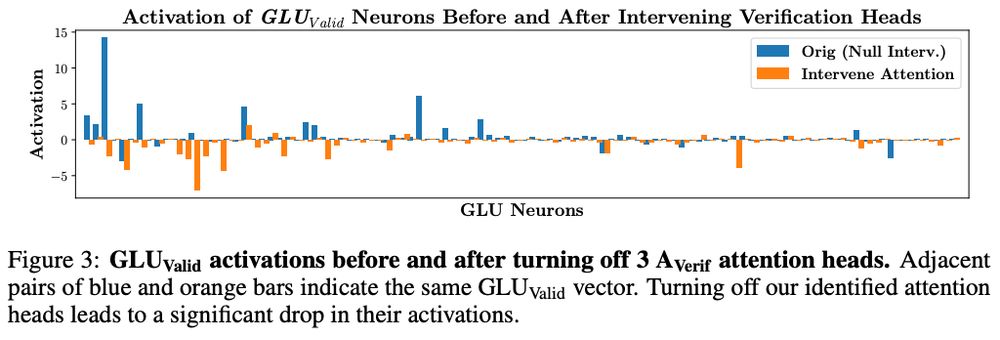
Our analyses meet in the middle:
We use “interlayer communication channels” to rank how much each head (OV circuit) aligns with the “receptive fields” of verification-related MLP weights.
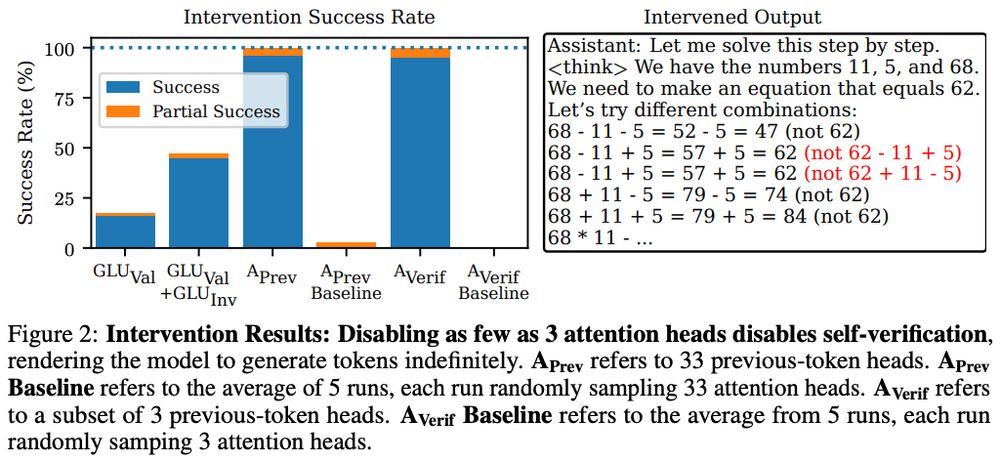
Disable *three* heads → disables self-verif. and deactivates verif.-MLP weights.
6/n
Bottom-up, we find previous-token heads (i.e., parts of induction heads) are responsible for self-verification in our setup. Disabling previous-token heads disables self-verification.
5/n

More importantly, we can use the probe to find MLP weights related to verification. Simply check for MLP weights with high cosine similarity to our probe.
Interestingly, we often see Eng. tokens for "valid direction" and Chinese tokens for "invalid direction".
4/n
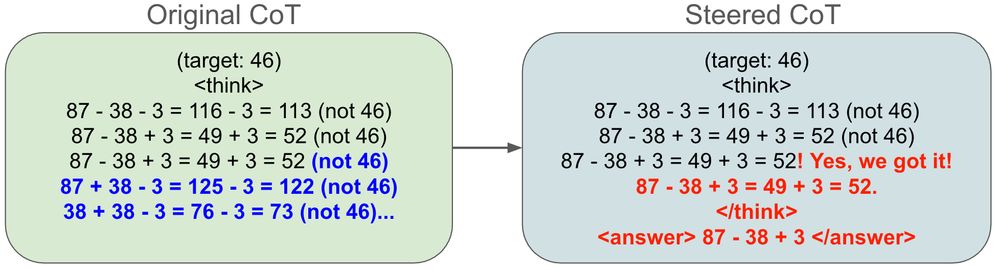
We do a “top-down” and “bottom-up” analysis. Top-down, we train a probe. We can use our probe to steer the model and trick it to have found a solution.
3/n

CoT is unfaithful. Can we monitor inner computations in latent space instead?
Case study: Let’s study self-verification!
Setup: We train Qwen-3B on CountDown until mode collapse, resulting in nicely structured CoT that’s easy to parse+analyze
2/n

🚨New preprint!
How do reasoning models verify their own CoT?
We reverse-engineer LMs and find critical components and subspaces needed for self-verification!
1/n
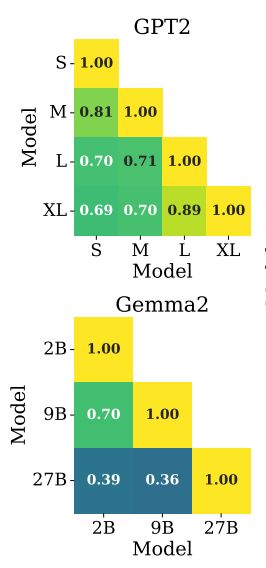
Interesting, I didn't know that! BTW, we find similar trends in GPT2 and Gemma2
07.05.2025 13:56 — 👍 2 🔁 0 💬 0 📌 0
Next time a reviewer asks, “Why didn’t you include [insert newest LM]?”, depending on your claims you could argue that your findings will generalize to other models, based on our work! Paper link: arxiv.org/abs/2503.21073
07.05.2025 13:38 — 👍 22 🔁 5 💬 1 📌 0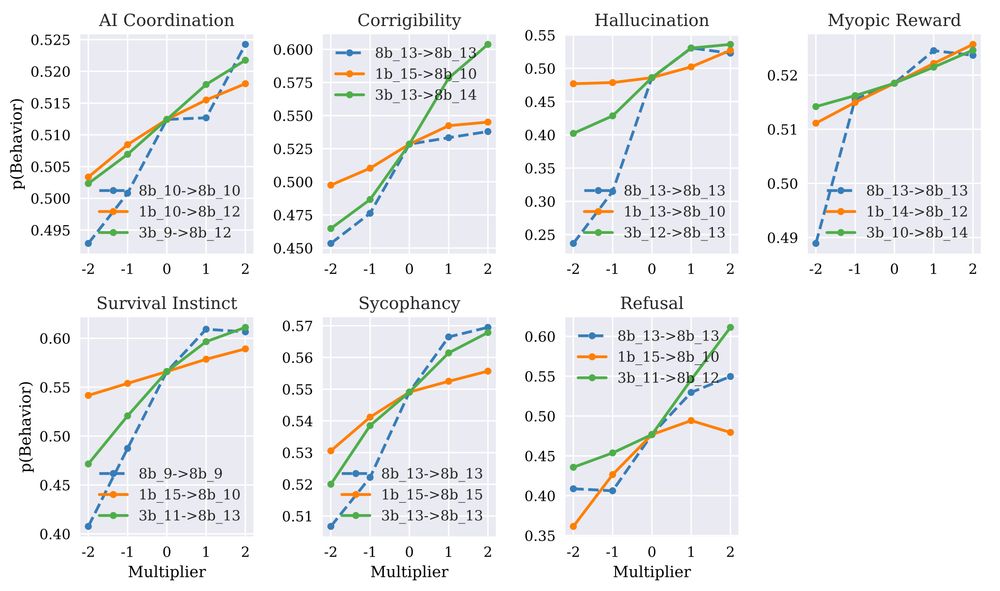
We call this simple approach Emb2Emb: Here we steer Llama8B using steering vectors from Llama1B and 3B:
07.05.2025 13:38 — 👍 2 🔁 0 💬 1 📌 0
Now, steering vectors can be transferred across LMs. Given LM1, LM2 & their embeddings E1, E2, fit a linear transform T from E1 to E2. Given steering vector V for LM1, apply T onto V, and now TV can steer LM2. Unembedding V or TV shows similar nearest neighbors encoding the steer vector’s concept:
07.05.2025 13:38 — 👍 2 🔁 0 💬 1 📌 0
Local2: We measure intrinsic dimension (ID) of token embeddings. Interestingly, ID reveals that tokens with low ID form very coherent semantic clusters, while tokens with higher ID do not!
07.05.2025 13:38 — 👍 3 🔁 1 💬 1 📌 0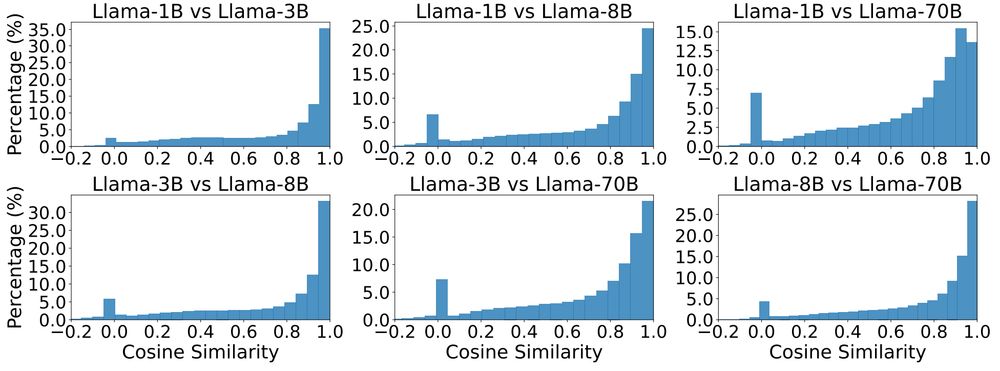
Local: we characterize two ways: first using Locally Linear Embeddings (LLE), in which we express each token embedding as the weighted sum of its k-nearest neighbors. It turns out, the LLE weights for most tokens look very similar across language models, indicating similar local geometry:
07.05.2025 13:38 — 👍 4 🔁 0 💬 1 📌 0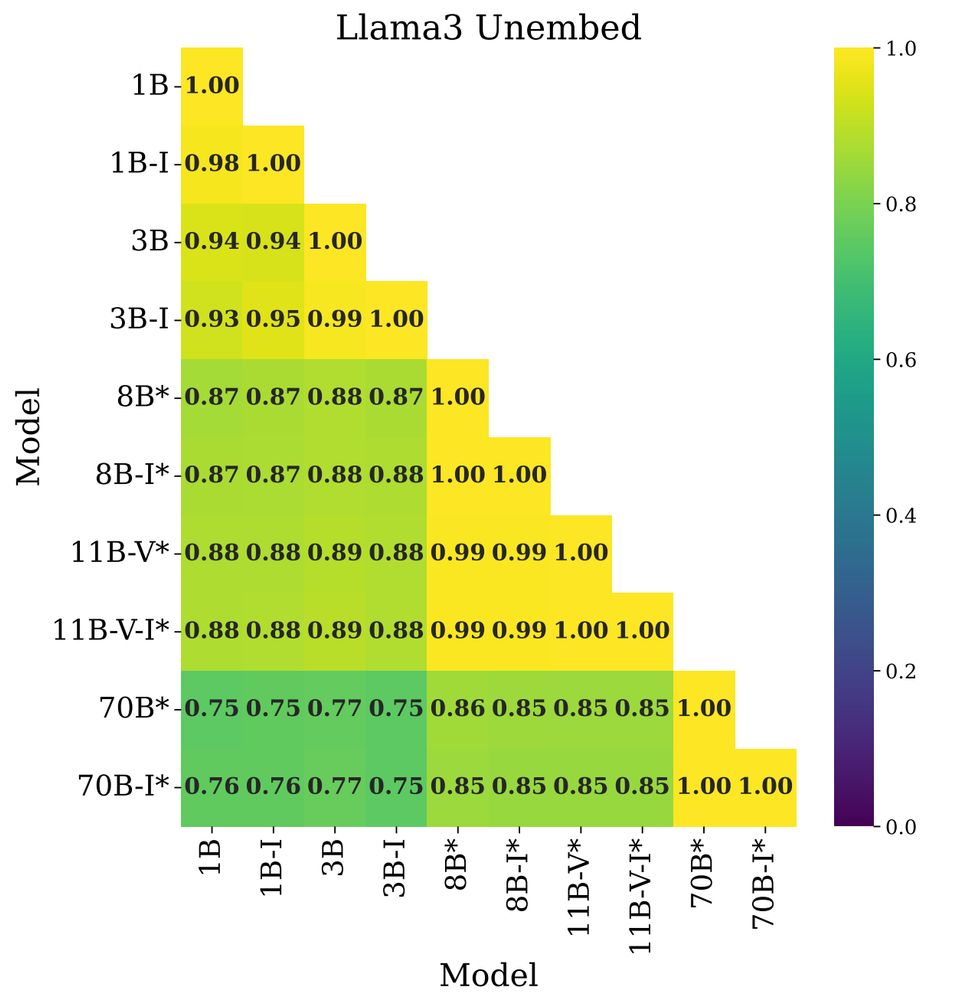
We characterize “global” and “local” geometry in simple terms.
Global: how similar are the distance matrices of embeddings across LMs? We can check with Pearson correlation between distance matrices: high correlation indicates similar relative orientations of token embeddings, which is what we find

🚨New Preprint! Did you know that steering vectors from one LM can be transferred and re-used in another LM? We argue this is because token embeddings across LMs share many “global” and “local” geometric similarities!
07.05.2025 13:38 — 👍 62 🔁 13 💬 3 📌 3Cool! QQ: say I have a "mech-interpy finding": for instance, say I found a "circuit" - is such a finding appropriate to submit, or is the workshop exclusively looking for actionable insights?
31.03.2025 18:43 — 👍 2 🔁 0 💬 0 📌 0
I think these papers are highly relevant but missing!
aclanthology.org/2023.emnlp-m...
arxiv.org/pdf/2403.07687
My website has a personal readme file with step by step instructions on how to make an update. I would need to hire someone if something were to ever happen to that readme file.
05.03.2025 02:56 — 👍 1 🔁 0 💬 0 📌 0
Today we launch a new open research community
It is called ARBOR:
arborproject.github.io/
please join us.
bsky.app/profile/ajy...
Check out on-going projects here! github.com/ARBORproject... or join our discord: discord.gg/SeBdQbRPkA
We hope to see your contributions!
Organizers: @wattenberg.bsky.social @viegas.bsky.social @davidbau.bsky.social @wendlerc.bsky.social @canrager.bsky.social
7/N
@canrager.bsky.social finds that R1’s reasoning tokens reveal a lot about restricted topics. Can we find all restricted topics of a reasoning model, by understanding its inner mechanisms?
dsthoughts.baulab.info
6/N

Similarly, I find linear vectors that seem to encode whether R1 has found a solution or not. We can steer the model to think that it’s found a solution during its CoT with simple linear interventions:
ajyl.github.io/2025/02/16/s...
5/N
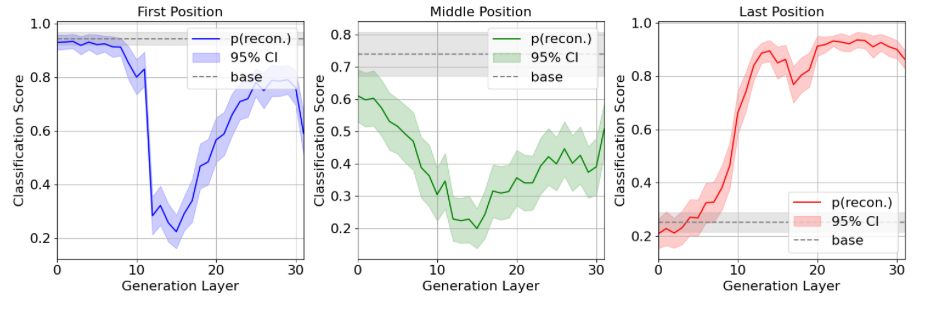
We have some preliminary findings. @wendlerc.bsky.social find simple steering vectors to either make the model continue its CoT (ie, double check its answers) or finish its thought on a GSM8K
github.com/ARBORproject...
