
Excited to have the Big Picture workshop back for another iteration this year at @aclmeeting.bsky.social
Submit your big picture ideas, consolidation work, phd thesis distillation, etc. by March 5th!
www.bigpictureworkshop.com
w/ Allyson Ettinger, @norakassner.bsky.social, @sebruder.bsky.social
03.02.2026 14:44 — 👍 9 🔁 3 💬 0 📌 0
🚨 New Study 🚨
@arxiv.bsky.social has recently decided to prohibit any 'position' paper from being submitted to its CS servers.
Why? Because of the "AI slop", and allegedly higher ratios of LLM-generated content in review papers, compared to non-review papers.
29.01.2026 14:00 — 👍 29 🔁 9 💬 2 📌 2

Looking forward to learning new things in 2026?
We’ve got you covered with 17 amazing talks exploring how AI reshapes the way we work!
Get your conference pass
380.-
available until January 31
Front Conference Zurich is coming up soon! On Friday, February 27, an amazing group of speakers will explore how AI is reshaping the way we work, from creativity and product design to engineering and collaboration
🤩 Our lineup: frontconference.com/schedule
🎟️ Your ticket: frontconference.com/tickets
17.01.2026 11:36 — 👍 2 🔁 3 💬 1 📌 1

Olmo 3 is a fully open LLM
Olmo is the LLM series from Ai2—the Allen institute for AI. Unlike most open weight models these are notable for including the full training data, training process and checkpoints along …
Olmo 3 is notable as a "fully open" LLM - all of the training data is published, plus complete details on how the training process was run. I tried out the 32B thinking model and the 7B instruct models, + thoughts on why transparent training data is so important simonwillison.net/2025/Nov/22/...
23.11.2025 00:17 — 👍 191 🔁 33 💬 2 📌 3
Olmo 3 is out! 🤩
I am particularly excited about Olmo 3 models' precise instruction following abilities and their good generalization performance on IFBench!
Lucky to have been a part of the Olmo journey for three iterations already.
20.11.2025 15:12 — 👍 24 🔁 3 💬 0 📌 0

Happy Halloween!
31.10.2025 10:48 — 👍 16 🔁 2 💬 0 📌 0
There’s plenty of evidence for political bias in LLMs, but very few evals reflect realistic LLM use cases — which is where bias actually matters.
IssueBench, our attempt to fix this, is accepted at TACL, and I will be at #EMNLP2025 next week to talk about it!
New results 🧵
29.10.2025 16:11 — 👍 32 🔁 11 💬 1 📌 0

I will be giving a talk at @eth-ai-center.bsky.social next week, on RLVR for verifiable instruction following, generalization, and reasoning! 📢
Join if you are in Zurich and interested in hearing about IFBench and our latest Olmo and Tülu works at @ai2.bsky.social
27.10.2025 14:22 — 👍 6 🔁 0 💬 0 📌 0

Title page of the paper: WUGNECTIVES: Novel Entity Inferences of Language Models from Discourse Connectives, with two figures at the bottom
Left: Our figure 1 -- comparing previous work, which usually predicted the connective given the arguments (grounded in the world); our work flips this premise by getting models to use their knowledge of connectives to predict something about the world.
Right: Our main results across 7 types of connective senses. Models are especially bad at Concession connectives.
"Although I hate leafy vegetables, I prefer daxes to blickets." Can you tell if daxes are leafy vegetables? LM's can't seem to! 📷
We investigate if LMs capture these inferences from connectives when they cannot rely on world knowledge.
New paper w/ Daniel, Will, @jessyjli.bsky.social
16.10.2025 15:27 — 👍 32 🔁 10 💬 2 📌 2

Next up we had @tsvetshop ‘s Yulia Tsvetkov talk about ethics, safety, and reliability of LLMs in the health domain.
10.10.2025 16:09 — 👍 2 🔁 0 💬 0 📌 0

💡We kicked off the SoLaR workshop at #COLM2025 with a great opinion talk by @michelleding.bsky.social & Jo Gasior Kavishe (joint work with @victorojewale.bsky.social and
@geomblog.bsky.social
) on "Testing LLMs in a sandbox isn't responsible. Focusing on community use and needs is."
10.10.2025 14:31 — 👍 15 🔁 4 💬 1 📌 0

Third Workshop on Socially Responsible Language Modelling Research (SoLaR) 2025
COLM 2025 in-person Workshop, October 10th at the Palais des Congrès in Montreal, Canada
Hi #COLM2025! 🇨🇦 I will be presenting a talk on the importance of community-driven LLM evaluations based on an opinion abstract I wrote with Jo Kavishe, @victorojewale.bsky.social and @geomblog.bsky.social tomorrow at 9:30am in 524b for solar-colm.github.io
Hope to see you there!
09.10.2025 19:32 — 👍 9 🔁 6 💬 1 📌 0
Now accepted to #neurips25 datasets & benchmarks!
See you in San Diego! 🥳
20.09.2025 06:56 — 👍 9 🔁 0 💬 0 📌 0


🚀 Can open science beat closed AI? Tülu 3 makes a powerful case. In our new #WiAIRpodcast, we speak with Valentina Pyatkin (@valentinapy.bsky.social) of @ai2.bsky.social and the University of Washington about a fully open post-training recipe—models, data, code, evals, and infra. #WomenInAI 1/8🧵
19.09.2025 16:13 — 👍 6 🔁 1 💬 1 📌 0

"𝐋𝐋𝐌 𝐏𝐨𝐬𝐭-𝐭𝐫𝐚𝐢𝐧𝐢𝐧𝐠: 𝐎𝐩𝐞𝐧 𝐒𝐜𝐢𝐞𝐧𝐜𝐞 𝐓𝐡𝐚𝐭 𝐏𝐨𝐰𝐞𝐫𝐬 𝐏𝐫𝐨𝐠𝐫𝐞𝐬𝐬 " 🎙️
On Sept 17, the #WiAIRpodcast speaks with @valentinapy.bsky.social (@ai2.bsky.social & University of Washington) about open science, post-training, mentorship, and visibility
#WiAIR #NLProc
12.09.2025 15:00 — 👍 6 🔁 1 💬 0 📌 0

With fresh support of $75M from NSF and $77M from NVIDIA, we’re set to scale our open model ecosystem, bolster the infrastructure behind it, and fast‑track reproducible AI research to unlock the next wave of scientific discovery. 💡
14.08.2025 12:16 — 👍 45 🔁 7 💬 1 📌 7

On my way to Oxford: Looking forward to speaking at OxML 2025
10.08.2025 08:09 — 👍 8 🔁 0 💬 0 📌 0
🔈For the SoLaR workshop
@COLM_conf
we are soliciting opinion abstracts to encourage new perspectives and opinions on responsible language modeling, 1-2 of which will be selected to be presented at the workshop.
Please use the google form below to submit your opinion abstract ⬇️
08.08.2025 12:40 — 👍 8 🔁 4 💬 1 📌 0
I had a lot of fun contemplating about memorization questions at the @l2m2workshop.bsky.social panel yesterday together with Niloofar Mireshghallah and Reza Shokri, moderated by
@pietrolesci.bsky.social who did a fantastic job!
#ACL2025
02.08.2025 15:04 — 👍 12 🔁 2 💬 1 📌 1
I'll be at #ACL2025🇦🇹!!
Would love to chat about all things pragmatics 🧠, redefining "helpfulness"🤔 and enabling better cross-cultural capabilities 🗺️ 🫶
Presenting our work on culturally offensive nonverbal gestures 👇
🕛Wed @ Poster Session 4
📍Hall 4/5, 11:00-12:30
26.07.2025 02:46 — 👍 4 🔁 1 💬 0 📌 0
I did! very very good!!
19.07.2025 05:19 — 👍 1 🔁 0 💬 0 📌 0

🔥tokenization panel!
18.07.2025 22:45 — 👍 7 🔁 0 💬 0 📌 0
why is vancouver sushi so good? 🤤 (vancouver food in general actually)
18.07.2025 20:27 — 👍 9 🔁 0 💬 3 📌 0

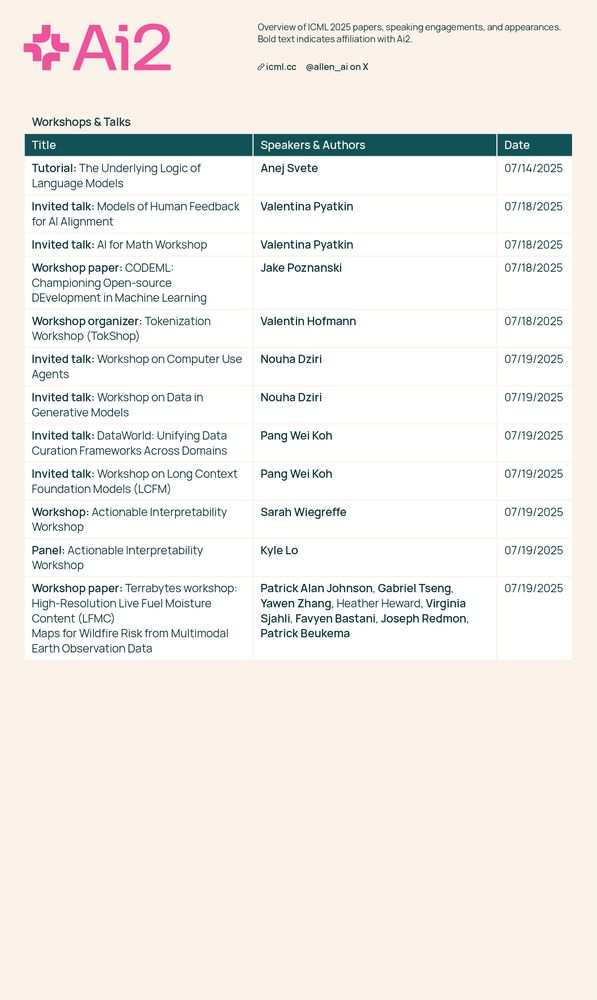
This week is #ICML in Vancouver, and a number of our researchers are participating. Here's the full list of Ai2's conference engagements—we look forward to connecting with fellow attendees. 👋
14.07.2025 19:30 — 👍 3 🔁 2 💬 0 📌 0
Let me know if you want to meet up! Always happy to chat!
11.07.2025 14:09 — 👍 0 🔁 0 💬 0 📌 0
ICML Poster Diverging Preferences: When do Annotators Disagree and do Models Know?ICML 2025
07/17, Poster: Diverging Preferences: When do Annotators Disagree and do Models Know? icml.cc/virtual/2025...
07/16, Poster: SafetyAnalyst: Interpretable, transparent, and steerable safety moderation for AI behavior
icml.cc/virtual/2025...
11.07.2025 14:09 — 👍 3 🔁 0 💬 1 📌 0
I'll be at ICML in Vancouver next week! #ICML2025
You can find me at the following:
- giving an invited talk at the "Models of Human Feedback for AI Alignment" workshop
- giving an invited talk at the "AI for Math" workshop
I'll also present these two papers ⤵️
11.07.2025 14:09 — 👍 9 🔁 2 💬 1 📌 0
In Geneva🇨🇭to attend the International Open-Source LLM Builders Summit and present OLMo and Tülu!
06.07.2025 17:23 — 👍 10 🔁 0 💬 0 📌 0
AI PhD @ University of Zurich
Research on Personalized News Recommender Systems
https://mamié.ch/
Prof at EPFL
AI • Climbing
ML Researcher at research.yandex.com | Working on DL for Tabular Data
I study algorithms/learning/data applied to democracy/markets/society. Asst. professor at Cornell Tech. https://gargnikhil.com/. Helping building personalized Bluesky research feed: https://bsky.app/profile/paper-feed.bsky.social/feed/preprintdigest
Agents, memory, representations, robots, vision. Sr Research Scientist at Google DeepMind. Previously at Oxford Robotics Institute. Views my own.
Associate Professor in Data Science and AI at Chalmers University of Technology. Neuro-symbolic AI, AI for maths, a bit of NLP and stir.
Uses machine learning to study literary imagination, and vice-versa. Likely to share news about AI & computational social science / Sozialwissenschaft / 社会科学
Information Sciences and English, UIUC. Distant Horizons (Chicago, 2019). tedunderwood.com
AI for Science, deep generative models, inverse problems. Professor of AI and deep learning @universitedeliege.bsky.social. Previously @CERN, @nyuniversity. https://glouppe.github.io
Account dell'Associazione Italiana di Linguistica Computazionale / Account of the Italian Association of Computational Linguistics, http://www.ai-lc.it/
Cornell Tech professor (information science, AI-mediated Communication, trustworthiness of our information ecosystem). New York City. Taller in person. Opinions my own.
Postdoc @ Princeton AI Lab
Natural and Artificial Minds
Prev: PhD @ Brown, MIT FutureTech
Website: https://annatsv.github.io/
PhDing @BrownCS | Algorithm auditing & accountability | Understanding Algorithmic Systems | victorojewale.github.io/ | https://victorojewale.substack.com/
Director, Center for Tech Responsibility@Brown. FAccT OG. AI Bill of Rights coauthor. Former tech advisor to President Biden @WHOSTP. He/him/his. Posts my own.
organizer/researcher critically investigating how AI systems impact communities. cs phd @ brown cntr. she/her.
🌷 https://michelle-ding.github.io/
💭 https://michellelding.substack.com/
PhD student @ Saarland University
WiAIR is dedicated to celebrating the remarkable contributions of female AI researchers from around the globe. Our goal is to empower early career researchers, especially women, to pursue their passion for AI and make an impact in this exciting field.
Postdoc @stanfordnlp.bsky.social / previously @milanlp.bsky.social / Computational social science, LLMs, algorithmic fairness
Principal AI research scientist @Vanguard_Group | Founder&Host @WiAIR_podcast | Research in NLP, multimodal AI, LLMs, evaluation | own opinions only 🇨🇦🇪🇺🏳️🌈
CS Prof at Brown University, PI of the GIRAFFE lab, former AI Policy Advisor in the US Senate, co-chair of the ACM Tech Policy Subcommittee on AI and Algorithms.
PhD at MIT CSAIL '23, Harvard '16, former Google APM. Dog mom to Ducki.
























