
Website: wimmerth.github.io/anyup/
Code: github.com/wimmerth/anyup
Paper: arxiv.org/abs/2510.12764

@campbell.fi.bsky.social
Data enthusiast, Father, consultant
Website: wimmerth.github.io/anyup/
Code: github.com/wimmerth/anyup
Paper: arxiv.org/abs/2510.12764

For myself to more easily find again later. (GitHub Markdown "alerts")
docs.github.com/en/get-start...
I figured out a uv recipe for running tests for any project with pyproject.toml or setuppy using any Python version:
uv run --python 3.14 --isolated --with-editable '.[test]' pytest
I've wrapped it in a uv-test script:
uv-test -p 3.11
Full details here: til.simonwillison.net/python/uv-te...

Death to Data Pipelines: The Banana Peel Problem 🍌
Data at the Centre vs. Pipeline-First Data Management, What Constitutes Resiliency in Data Systems Today, and Defensive Designs that are Built to Mistrust
open.substack.com/pub/modernda...

If you can stand to listen to me about model economics and synthetic environments for two hours, I have the podcast for you. www.youtube.com/watch?v=ZZKM...
05.10.2025 11:06 — 👍 29 🔁 2 💬 1 📌 1A $196 fine-tuned 7B model outperforms OpenAI o3 on document extraction | Discussion
30.09.2025 17:40 — 👍 3 🔁 1 💬 0 📌 0
the owners of TikTok scandalously release:
REER: a learning method that exposes the logic that led to a good result
Booty: when shaken properly elicits creative writing
ASS: (they couldn’t get an acronym to work, but i’m sure they tried)
huggingface.co/papers/2509....

I got introduced to @randyau.com's 'Data Cleaning IS Analysis, Not Grunt Work' post during the #dataBS Conf this week: www.counting-stuff.com/data-cleanin... . I just finished--it was a great read.
Here are some quotes and thoughts I'm walking away with 👇
1/9 #RStats

Google DeepMind's paper on EmbeddingGemma, which scores really well on MTEB (huggingface.co/spaces/mteb/...) for a such a small model (300M)
"EmbeddingGemma: Powerful and Lightweight Text Representations"

Lucy Edit Dev is the first open-source instruction-guided video editing model that performs instruction-guided edits on videos using free-text prompts.
github.com/DecartAI/luc...

Alibaba released Qwen3-Omni, a natively end-to-end multilingual omni-modal (text, images, audio, video) foundation model, responding as real-time stream in both text and natural speech, available under open-source license.
github.com/QwenLM/Qwen3...
Now this looks fun to play with!
24.09.2025 07:54 — 👍 5 🔁 1 💬 0 📌 0
First Look at #onelake #apacheiceberg REST Catalog, please notice it is coming soon and not in production yet #MicrosoftFabric
www.youtube.com/watch?v=_QRE...
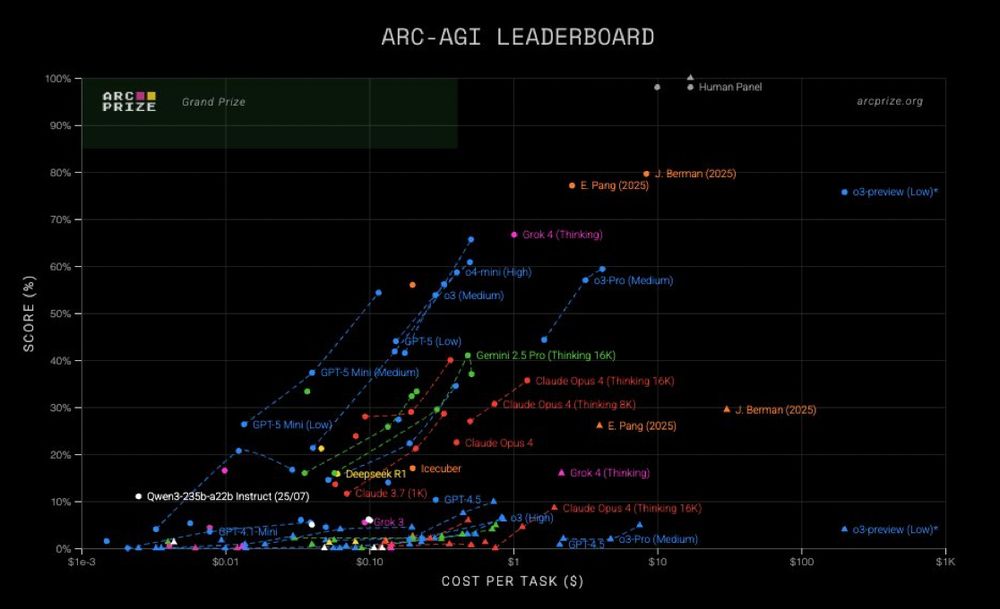
The chart is titled “ARC-AGI LEADERBOARD” and plots Score (%) on the y-axis (0–100%) against Cost per Task ($) on the x-axis (log scale, $1e-3 → $1K).** At the very top near 90–100% score: • Human Panel (grey dot) sits around 95–100% accuracy at very high cost (far right side, >$100). Just below the Human Panel, in the 70–80% score range: • J. Berman (2025) (orange triangle) and E. Pang (2025) (orange circle) are positioned in the 70–80% band, further right in cost (approx $10–$100). • Grok 4 (Thinking) (magenta triangle) reaches around 70% accuracy, sitting higher than most models, at mid-to-high cost ($1–$10). In the 60–70% band near the top left/mid: • o3-Pro (Medium) (blue circle) scores around 65%, with costs around $1–$10. • o4-mini (High) (blue circle) also scores 65%, at slightly lower cost ($1). A bit lower but still clustered near the upper half: • Gemini 2.5 Pro (Thinking 16K) (green dot) around 55–60% score, with moderate cost (~$0.10–$1). • Claude Opus 4 (Thinking 16K) (red dot) 55–60% score at higher cost ($1–$10). Summary: • Highest performers: Human Panel (~95–100%), Grok 4 (Thinking) (~70%), o3-Pro and o4-mini (~65%). • Notable human entries: J. Berman and E. Pang (2025) scoring 70–80%. • Strong models at moderate costs: Gemini 2.5 Pro (Thinking 16K) and Claude Opus 4 (Thinking 16K).
the top 2 ARC entries are by individuals
here, Eric Pang breaks down how he added memory to avoid recomputing learned lessons
ctpang.substack.com/p/arc-agi-2-...

i did not foresee the future in which Markdown was the machine interop format for all human readable documents
blog.xeynergy.com/what-is-micr...
Give me a one liner bash script... Four hundred lines later...
15.09.2025 14:49 — 👍 2 🔁 0 💬 0 📌 0
Does a smaller latent space lead to worse generation in latent diffusion models? Not necessarily! We show that LDMs are extremely robust to a wide range of compression rates (10-1000x) in the context of physics emulation.
We got lost in latent space. Join us 👇
i wanted to understand the current landscape better, so i did a deep dive on current embedding sizes and architectures vickiboykis.com/2025/09/01/h...
01.09.2025 16:15 — 👍 89 🔁 13 💬 4 📌 2
simple little uv-runnable python script to generate interactive diffs for arxiv papers based on the underlying latex source.
github.com/apoorvalal/a...

Who doesn't love a good narrow-gauge train
21.08.2025 18:54 — 👍 0 🔁 0 💬 0 📌 0
The trains in Spain run mainly on the plain
21.08.2025 18:50 — 👍 0 🔁 0 💬 0 📌 0
Here's a sight you won't see for too much longer, a DB riding in a ferry between Denmark and Germany
21.08.2025 18:49 — 👍 0 🔁 0 💬 0 📌 0
Here's a tram in Krakow
21.08.2025 18:46 — 👍 0 🔁 0 💬 0 📌 0
These Austrian engines make a musical scale while applying power to pull out of the station
21.08.2025 18:42 — 👍 0 🔁 0 💬 0 📌 0
Schottentor U2 station in Vienna. Fun story, before the U2 was constructed the trams ran on the current cut-and-cover metro tracks. The under the street trams were still in use on the south west side of the city.
21.08.2025 18:40 — 👍 0 🔁 0 💬 0 📌 0
How about an eastern-bloc Hungarian engine
21.08.2025 18:31 — 👍 0 🔁 0 💬 0 📌 0
Its about time for some random pictures of public transportation. How about some double-decker trams in HK
21.08.2025 18:25 — 👍 1 🔁 0 💬 7 📌 0@mollyjongfast.bsky.social Re: your latest pod, Trump's bond purchase explains his insistence on lowering interest rates. Bond values have an inverse relationship to interest rates, so it is just another instance of corrupt self-dealing
21.08.2025 05:46 — 👍 2 🔁 1 💬 0 📌 1Helsinki extended its metro 12 miles between 2016 and 2023. The new track was all done in tunnels, most of them blasted out of rock. Total cost was 2.35 billion euros
18.08.2025 19:45 — 👍 1 🔁 0 💬 0 📌 0



















