3️⃣ We explain why structural information in PE has proven to be empirically successful.
We go back to 1️⃣ and use the content-context connection to show that the higher is the mutual information between data and its positional representation, the better is task performance.
08.04.2025 04:52 — 👍 0 🔁 0 💬 0 📌 0
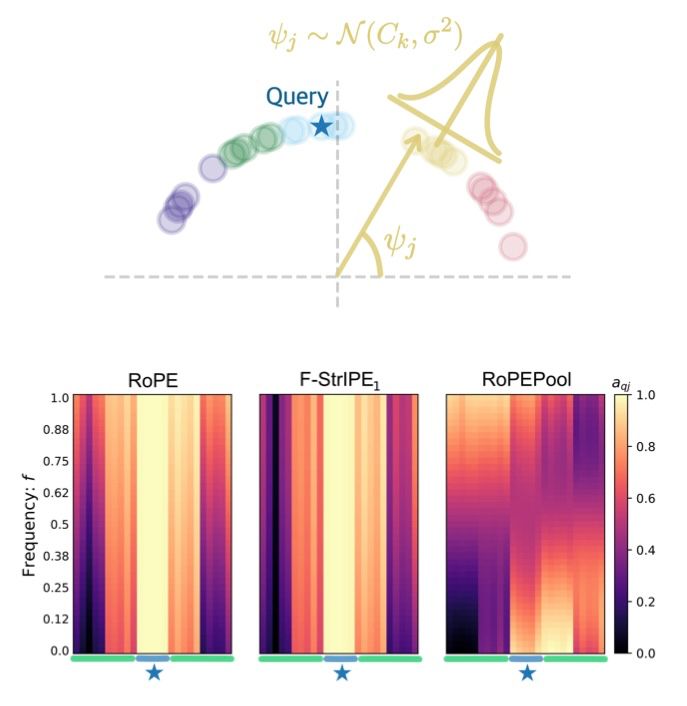
2️⃣ We introduce a new positional encoding method - RoPEPool - that can model causality.
How does RoPEPool compare to RoPE and F-StrIPE? Our analysis with a toy example says: RoPEPool isn’t just different, it’s also richer in terms of expressivity.
08.04.2025 04:52 — 👍 0 🔁 0 💬 1 📌 0

1️⃣ We show how different families of positional encoding - rotation-based (RoPE) and random fourier features-based (F-StrIPE) - can be compared using kernel methods.
It’s not just vibes - we characterize precisely how queries and keys are affected by positional information.
08.04.2025 04:52 — 👍 0 🔁 0 💬 1 📌 0
🚨 We just submitted a follow-up to this work, now available as a preprint: hal.science/hal-05021809
08.04.2025 04:52 — 👍 0 🔁 1 💬 1 📌 0
With these two interventions, we obtain better performance at lower cost! 🚀
Curious? Check out the companion webpage: bit.ly/faststructurepe
07.04.2025 11:48 — 👍 0 🔁 0 💬 0 📌 0
In our paper, we show that stochastic positional encoding is, in fact, a noisy version of a well-known kernel approximation technique: Random Fourier Features. We also show how prior knowledge (e.g. related to musical structure) can be used in such linear-complexity Transformers.
07.04.2025 11:48 — 👍 0 🔁 0 💬 1 📌 0
However, there was a piece missing: how do you handle relative positional encoding in these linear-complexity transformers? 🤔
Enter Stochastic Positional Encoding! It brings relative positional information back into the picture without going to quadratic cost.
07.04.2025 11:48 — 👍 0 🔁 0 💬 1 📌 0
Luckily, there's a solution: you can think of attention as a kernel function and use kernel approximation techniques to reduce the cost from quadratic to linear. ⚡
This was the idea used by Performers, for example.
07.04.2025 11:48 — 👍 0 🔁 0 💬 1 📌 0
Transformers are powerful, but there's a problem: their cost grows quadratically with sequence length. 📈
This makes it really hard to apply them to lengthy sequences, like music, where long-term connections carry important information.
07.04.2025 11:48 — 👍 0 🔁 0 💬 1 📌 0

ICASSP 2025 has begun! I will be presenting "F-StrIPE: Fast Structure-Informed Positional Encoding for Symbolic Music Generation" on April 11 in the lecture session "Machine learning for speech, audio and music processing II" at 2 PM.
More details below 🧵
07.04.2025 11:48 — 👍 1 🔁 0 💬 1 📌 1
 01.12.2024 13:22 — 👍 1 🔁 0 💬 0 📌 0
01.12.2024 13:22 — 👍 1 🔁 0 💬 0 📌 0
Are you at @c4dm.bsky.social in the next days? Let’s talk music + machines ✨
We also have a project available for a Master’s student. Advert below!
01.12.2024 13:22 — 👍 1 🔁 1 💬 1 📌 0




