congrats!!
26.11.2025 13:36 — 👍 1 🔁 0 💬 1 📌 0

a red building on UPENN's campus photographed during the fall

the Philadelphia skyline, with clear skies and autumn trees
starting fall 2026 i'll be an assistant professor at @upenn.edu 🥳
my lab will develop scalable models/theories of human behavior, focused on memory and perception
currently recruiting PhD students in psychology, neuroscience, & computer science!
reach out if you're interested 😊
25.11.2025 21:36 — 👍 201 🔁 37 💬 21 📌 3
21/ Poster #2510 (Fri 5 Dec, 4:30-7:30pm PT) at the main conference. Also at the Mechanistic Interpretability Workshop at NeurIPS (Sun 7 Dec). Come chat!
18.11.2025 02:10 — 👍 1 🔁 0 💬 0 📌 0
20/ Thanks to the reviewers and the NeurIPS 2025 community. Thanks also to @zfjoshying, Yushu Pan, @eliasbareinboim (and the CausalAI Lab at Columbia University) for helpful feedback on this work.
18.11.2025 02:10 — 👍 1 🔁 0 💬 1 📌 0
19/ Open questions: Do these findings extend to real-world LLMs, more complex causal structures? Could video models like Sora be learning physics simulators internally? We’re excited to explore this in future work.
18.11.2025 02:10 — 👍 1 🔁 0 💬 1 📌 0
18/ Limitations: This is an existence proof in a constrained setting (linear Gaussian SCMs, artificial language). Let us know if you have ideas on how to test this in real LLMs. What may we be missing?
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0
17/ Broader implications: Even when trained using “statistical” prediction, neural networks can develop sophisticated internal machinery (compositional, symbolic structures) that support genuine causal models and reasoning. The “causal parrot” framing may be too limited.
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0
16/ Three lines of evidence that the model possesses genuine causal models: (1) it generalizes to novel structure-query combinations, (2) it learns decodable causal representations, and (3) representations can be causally manipulated with predictable effects.
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

15/ Result 3 (continued): When we intervene on layer activations to change weight w_12 from 0 → 1, the model's predictions flip to match the modified causal structure. This suggests we’re decoding the actual underlying representation the model uses. (See paper for more quantitative results.)
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

14/ Result 3: We can manipulate the model's internal causal representation mid-computation using gradient descent (following the technique from Li et al. 2023). Changing the SCM weights using the probe produces predictable changes in the network’s outputs.
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0
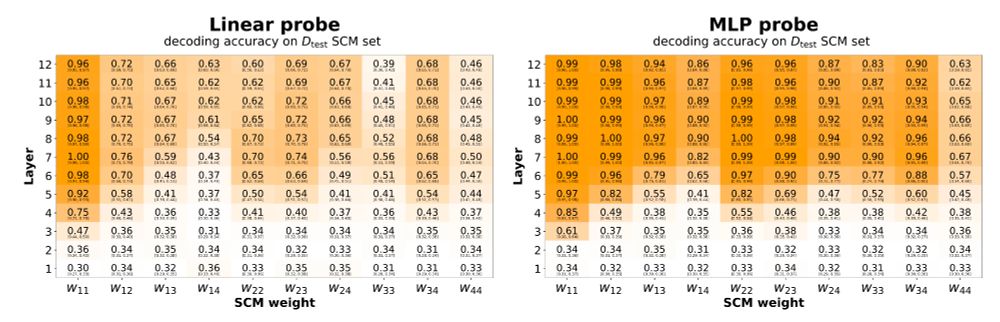
13/ Result 2: We can decode the SCM weights directly from the transformer's residual stream activations using linear and MLP probes. The model builds interpretable internal representations of causal structure.
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0
12/ But does the model really have internal causal models, or is this just lucky generalization? We probe inside to find out...
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

11/ Result 1: Yes! The model generalizes to counterfactual queries about D_test SCMs, reaching near-optimal performance. It must have: (1) learned a counterfactual inference engine, (2) discovered D_test structures from DATA strings, (3) composed them together.
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

10/ The generalization challenge: We hold out 1,000 SCMs (D_test) where the model sees *only* interventional DATA strings during training and zero INFERENCE examples. Can it still answer counterfactual queries about these SCMs?
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

9/ We train a GPT-style transformer to predict the next token in this text. The key question: does it simply memorize the training data, or does it discover causal structure and perform inference?
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

8/ Our setup: ~59k SCMs, each defined by 10 ternary weights. We generate training data using the SCMs in an artificial language with two string types: (1) DATA provide noisy interventional samples and (2) INFERENCE — counterfactual means/stds.
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

7/ Our hypothesis: next-token prediction can drive the emergence of genuine causal models and inference capabilities. We tested this in a controlled setting with linear Gaussian structural causal models (SCMs).
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

6/ Pearl (Amstat News interview, 2023) and Zečević et al. (2023) acknowledge causal info exists in text, but argue LLMs are merely "causal parrots"—they memorize and recite but do not possess actual causal models.
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

5/ But natural language used to train LLMs contains rich descriptions of interventions and causal inferences. Passive data != observational data. Text has L2/L3 information!
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0

4/ Pearl’s vivid metaphor from “The Book of Why” (p. 362): “Like prisoners in Plato's cave, deep-learning systems explore shadows on the wall and learn to predict their movements. They lack understanding that shadows are mere projections of 3D objects in 3D space.”
18.11.2025 02:10 — 👍 1 🔁 0 💬 1 📌 0

3/ Pearl's argument: DNNs trained on “passive” observations using statistical prediction objectives are fundamentally limited to associations (L1) and cannot reason about interventions (L2) or counterfactuals (L3).
18.11.2025 02:10 — 👍 0 🔁 0 💬 1 📌 0
2/ Paper: “Causal Discovery and Inference through Next-Token Prediction” (Butkus & Kriegeskorte)
OpenReview: openreview.net/pdf?id=MMYTA...,
NeurIPS: neurips.cc/virtual/2025...
18.11.2025 02:10 — 👍 1 🔁 0 💬 1 📌 0

1/ Can causal models and causal inference engines emerge through next-token prediction? Judea Pearl and others (Zečević et al. 2023) have argued no. We present behavioral and mechanistic evidence that this is possible. #neurips2025 #NeurIPS
18.11.2025 02:10 — 👍 8 🔁 1 💬 1 📌 0
Hippocampal encoding of memories in human infants
Humans lack memories for specific events from the first few years of life. We investigated the mechanistic basis of this infantile amnesia by scanning the brains of awake infants with functional magne...
Why do we not remember being a baby? One idea is that the hippocampus, which is essential for episodic memory in adults, is too immature to form individual memories in infancy. We tested this using awake infant fMRI, new in @science.org #ScienceResearch www.science.org/doi/10.1126/...
20.03.2025 18:36 — 👍 483 🔁 165 💬 20 📌 22

Key-value memory in the brain
Classical models of memory in psychology and neuroscience rely on similarity-based retrieval of stored patterns, where similarity is a function of retrieval cues and the stored patterns. While parsimo...
Key-value memory is an important concept in modern machine learning (e.g., transformers). Ila Fiete, Kazuki Irie, and I have written a paper showing how key-value memory provides a way of thinking about memory organization in the brain:
arxiv.org/abs/2501.02950
07.01.2025 09:21 — 👍 122 🔁 30 💬 3 📌 1
reminds me of Dennett's take that we should be building "tools not colleagues"
05.01.2025 22:41 — 👍 4 🔁 0 💬 1 📌 0

Deep neural networks are complex, but looking inside them ought to be simple. Check out TorchLens, a package that can visualize any PyTorch network and extract all activations and metadata in just one line of code:
github.com/johnmarktayl...
www.nature.com/articles/s41...
27.12.2024 03:14 — 👍 55 🔁 15 💬 2 📌 0
For mechanistic interpretability, being able to intervene on the activations would be amazing. TransformerLens allows that, but only for certain pre-defined transformer models. Would be amazing to have this for arbitrary models! (There may be technical challenges why this is tricky though...)
27.12.2024 03:54 — 👍 2 🔁 0 💬 2 📌 0

Are you a grad student in AI interested in neuroscience and neuroAI?
Become a summer neuroAI intern at CSHL!
www.schooljobs.com/careers/cshl...
03.12.2024 14:14 — 👍 47 🔁 21 💬 3 📌 2
Faculty fellow at NYU CDS. Previously: PhD @ BIU NLP.
Recurrent computations and lifelong learning.
Postdoc at IKW-UOS@DE with @timkietzmann.bsky.social
Prev. Donders@NL, CIMeC@IT, IIT-B@IN
sushrutthorat.com
🧛🏻♀️ assist prof in brain & cognitive science @USC
(postdoc @caltech, phd @princeton)
🔎 computational approaches to reinforcement learning, memory & decision-making at individual & collective level; comp psychiatry
http://www.rouhanilab.com
Cognitive scientist at Princeton, personally & scientifically interested in collaboration | science sketcher | thinking in non-English 🇵🇷
Associate Director of Cognitive Science @PennMindCORE. Treasurer @5thsq, Board Vice-President @pandpinst. he/him. Cancer survivor and ADHD haver. I sell land value tax, and land value tax accessories.
Uruguayo 🇺🇾 Incoming Asst. Prof. UPenn. HSFP fellow at Harvard. PhD in HU Berlin. Systems Neuro, Neuroethologist of fun rodents, Natural Neuro! Painter, Improviser, Artist.
computational cog sci • problem solving and social cognition • asst prof at NYU • https://codec-lab.github.io/
Neuro, Psycho, Pharmaco •
Ketamine, Opioids and others • 🧠🧪
PhD, Pharmacology and Toxicology • Behavioral Neuroscience
Diversity, Inclusion, Equity, Justice • A little to the left of progressive • We can do better…
Language processing - Neuroscience - Machine Learning - Assistant Professor at Stanford University - She/Her - 🏳️🌈
NIH Postdoc Fellow @Yale | Previously @NYU @UCLA | Memory, auditory cognition, consciousness, machine learning
Assistant professor at NYU.
Researching human and computational vision.
Learning to entertain paradoxes.
Machine Learning (Kietzmann) & Neurobiopsychology (König) @ Uni Osnabrück
psulewski.de
Phd student at @MPI_NL@Donders, working on multimodal semantic representations in 🖥️ and 👶🧠 https://tianaidong.github.io/
Assistant Professor of Clinical Psychology
@ UPenn | Quant-curious | Lv. 11 Dwarf paladin
Inflammatory phenotyping, physiometrics, precision psychiatry
Statistics, Transparency, + Rigor Editor @ Psychological Science
neuromantic - ML and cognitive computational neuroscience - PhD student at Kietzmann Lab, Osnabrück University.
⛓️ https://init-self.com
Emmy-nominated reporter. Russia Today called me “notorious,” China kicked me out. Formerly Asia, Doha, California, more 🌏. Author of graphic novel YOU MUST TAKE PART IN REVOLUTION out now!
PhD student in the Object Vision Group at CIMeC, University of Trento. Interested in neuroimaging and object perception. He/him 🏳️🌈
https://davidecortinovis-droid.github.io/
PhD Student | Memory Researcher in the Aly Lab | GRFP Fellow | Cat Parent 🐈|enby
PhD student @ NYU (computer graphics + human vision)
jennakangg.github.io