Is it just me or is fucking linkedin taking over some of the functions that twitter used to fill?
08.05.2025 08:30 — 👍 0 🔁 0 💬 1 📌 0


🔥🔥🔥 CV Folks, I have some news! We're organizing a 1-day meeting in center Paris on June 6th before CVPR called CVPR@Paris (similar as NeurIPS@Paris) 🥐🍾🥖🍷
Registration is open (it's free) with priority given to authors of accepted papers: cvprinparis.github.io/CVPR2025InPa...
Big 🧵👇 with details!
21.03.2025 06:43 — 👍 137 🔁 51 💬 8 📌 10
Wow, neet! Reannotation is key here.
Conjecture:
As we are get more and more well-aligned text-image data, it will become easier and easier to train models.
This will allow us to explore both more streamlined and more exotic training recipes.
More signals that exciting times are coming!
03.03.2025 11:50 — 👍 2 🔁 2 💬 1 📌 0
arxiv.org/abs/2310.16834
More likely, they just use this very nice work of theirs.
28.02.2025 02:20 — 👍 0 🔁 0 💬 0 📌 0
Wild guess: VAE-Bidirectional transformers as text embedder for per-token low dimension embeddings suitable to diffusion.
That would be an cool thing to try anyway.
28.02.2025 01:31 — 👍 1 🔁 0 💬 1 📌 0
A game changer. A lot of people suspected it *should* work, but actually seeing it in action is something.
28.02.2025 00:25 — 👍 1 🔁 0 💬 1 📌 0

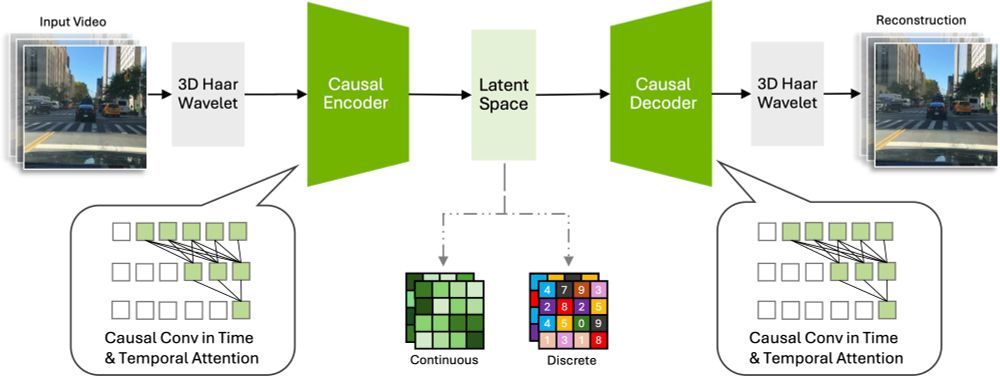
🚗 Ever wondered if an AI model could learn to drive just by watching YouTube? 🎥👀
We trained a 1.2B parameter model on 1,800+ hours of raw driving videos.
No labels. No maps. Just pure observation.
And it works! 🤯
🧵👇 [1/10]
24.02.2025 12:53 — 👍 24 🔁 7 💬 1 📌 2
Bluesky is less engaging because the algorithm is less predatory.
08.02.2025 13:14 — 👍 0 🔁 0 💬 0 📌 0
The plateau on training scaling and the shift to test-time scaling created favorable conditions for a competitor like DeepSeek to raise and catch up with OpenAI.
Nah, I just made that up. Need to put more thoughts into this. 🤔
29.01.2025 00:23 — 👍 2 🔁 0 💬 0 📌 0

Also, the whole system could already almost be seen as a form of self-improvement with some minimal human signals.
14.12.2024 11:26 — 👍 0 🔁 0 💬 0 📌 0
We've reached a point where synthetic data is just better and more convenient than messy noisy web-crawled data.
It's been true for multimodal data for a while, and semi-automated data as in the Florence-2 paper has been very succesful. arxiv.org/abs/2311.06242
14.12.2024 11:23 — 👍 0 🔁 0 💬 1 📌 0
Better VQ-VAEs with this one weird rotation trick!
I missed this when it came out, but I love papers like this: a simple change to an already powerful technique, that significantly improves results without introducing complexity or hyperparameters.
02.12.2024 19:52 — 👍 87 🔁 13 💬 1 📌 0
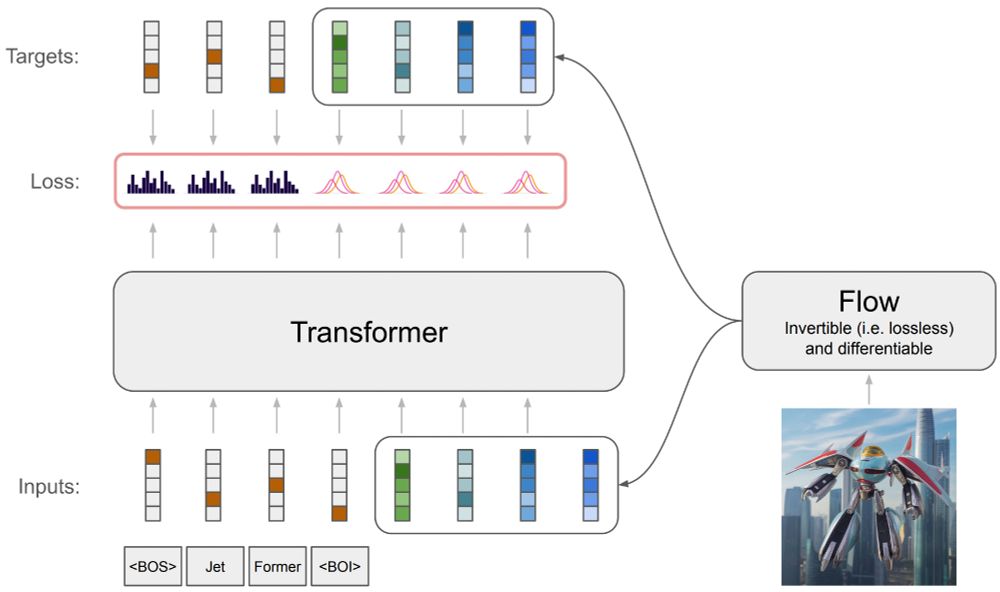
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
02.12.2024 16:41 — 👍 155 🔁 36 💬 4 📌 7
For AI to be fair and sustainable, we'd need to figure out attribution, i.e. "How much does training sample X contribute to model output Y?" Then the creator of sample X gets paid an amount proportional to what the user paid for the inference call that produced output Y.
21.11.2024 09:31 — 👍 5 🔁 1 💬 2 📌 2
A great place for students interested in AI/CV research internship. It's a very strong team, invested with all of their students. Check it out.
23.11.2024 13:50 — 👍 1 🔁 0 💬 0 📌 0

Andrei Bursuc on LinkedIn: #cvpr2024 #cvpr
In case you missed our PointBeV poster at #CVPR2024 here's a quick presentation by the lead author Loïck C..
PointBEV brings a change of paradigm in…
ICYMI our PointBeV #CVPR2024 poster here's a quick talk by lead author Loïck Chambon.
It brings a change of paradigm in multi-camera bird's-eye-view (BeV) segmentation via a flexible mechanism to produce sparse BeV points that can adapt to situation, task, compute
www.linkedin.com/posts/andrei...
22.11.2024 11:18 — 👍 11 🔁 3 💬 1 📌 0
This is ridiculous. And then people will talk about inclusivity and mental health. Sorry to speak my mind so openly, but this has to be the most toxic idea in a very long time.
18.11.2024 19:23 — 👍 14 🔁 2 💬 1 📌 0
PhD Student at IMAGINE (ENPC)
Working on camera pose estimation
thibautloiseau.github.io
PhD student at École Polytechnique (Vista) and École des Ponts (IMAGINE)
Working on conditional diffusion models
PhD student at IMAGINE (ENPC) and GeoVic (Ecole Polytechnique). Working on image generation.
http://nicolas-dufour.github.io
Pioneering a new generation of LLMs.
Compte officiel de l’Insee. #Statistiques et études sur l'#économie et la #société françaises.
https://www.insee.fr/fr/accueil
Humoriste de talent. Stand up. Manque de travail. Attention second trimestre.
22 | 1.4M+ on YouTube | @MeidasTouch.com
Join me now on Substack for more content at AdamMockler.com!
PhD student at Sorbonne University
AI & CV scientist, CEO at @kyutai-labs.bsky.social
☄️ Docteur en astrochimie, ingénieur chimiste
🎙️ Vulgarisateur sur twitch : twitch.tv/toutsecomprend (twitch partner)
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
Professor of Statistics @ ESSEC Business School Asia-Pacific campus Singapore 🇸🇬
https://pierrealquier.github.io/
Previously: RIKEN AIP 🇯🇵 ENSAE Paris 🇫🇷 🇪🇺 UCD Dublin 🇮🇪 🇪🇺
Random posts about stats/maths/ML/AI, poor jokes & birds photo 🌈
Video game concept artist and art director. TTRPG illustrator and designer. Premier Pointy Hat Youtuber. Dog enjoyer. Opinions are my own, regrettably.
Streamer politique sur #Twitch depuis 2015.
Co-Producteur, animateur et diffuseur de l'émission BACKSEAT.
Tweet #politique & #gaming
contact : pro(at)jeanmassiet(point)fr
Personal Account
Founder: The Distributed AI Research Institute @dairinstitute.bsky.social.
Author: The View from Somewhere, a memoir & manifesto arguing for a technological future that serves our communities (to be published by One Signal / Atria
Senior research scientist at Unity | Generative models, Computer Graphics
Research Scientist @GoogleDeepMind. Representation learning for multimodal understanding and generation.
mitscha.github.io
Explainability, Computer Vision, Neuro-AI.🪴 Kempner Fellow @Harvard.
Prev. PhD @Brown, @Google, @GoPro. Crêpe lover.
📍 Boston | 🔗 thomasfel.me
Ph.D. Candidate at VRG, CTU in Prague