
HF model collection for transformers:
huggingface.co/collections/...
HF model collection for OpenCLIP and timm:
huggingface.co/collections/...
And of course big_vision checkpoints:
github.com/google-resea...

@mtschannen.bsky.social
Research Scientist @GoogleDeepMind. Representation learning for multimodal understanding and generation. mitscha.github.io
HF model collection for transformers:
huggingface.co/collections/...
HF model collection for OpenCLIP and timm:
huggingface.co/collections/...
And of course big_vision checkpoints:
github.com/google-resea...

Paper:
arxiv.org/abs/2502.14786
HF blog post from @arig23498.bsky.social et al. with a gentle intro to the training recipe and a demo:
huggingface.co/blog/siglip2
Thread with results overview from Xiaohua (only on X, sorry - these are all in the paper):
x.com/XiaohuaZhai/...
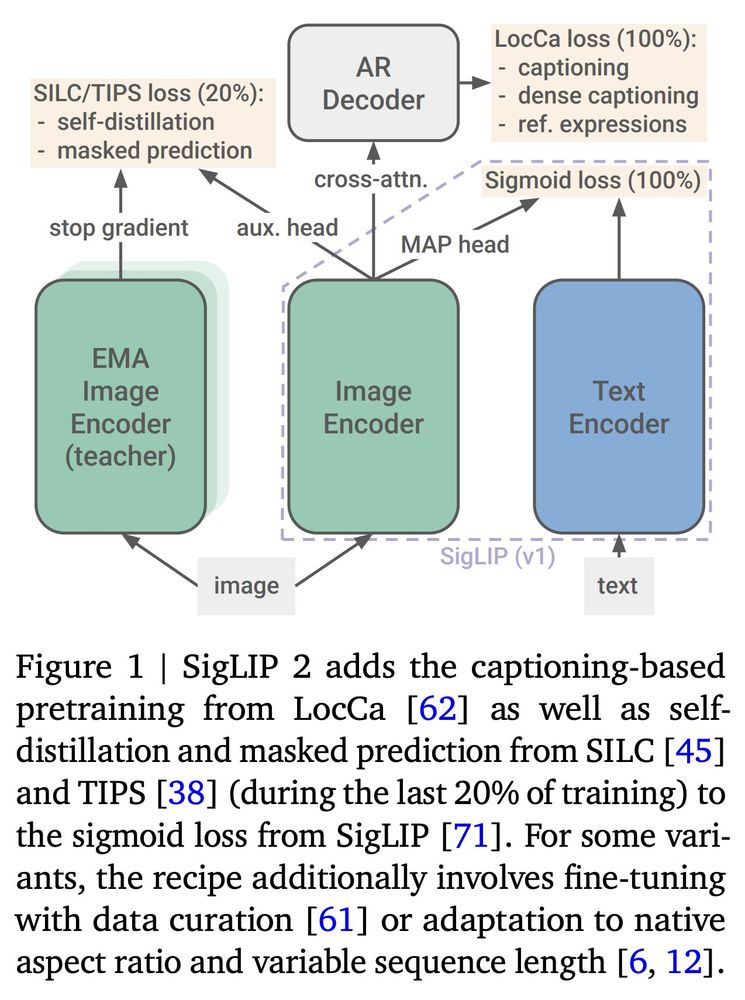
📢2⃣ Yesterday we released SigLIP 2!
TL;DR: Improved high-level semantics, localization, dense features, and multilingual capabilities via drop-in replacement for v1.
Bonus: Variants supporting native aspect and variable sequence length.
A thread with interesting resources👇
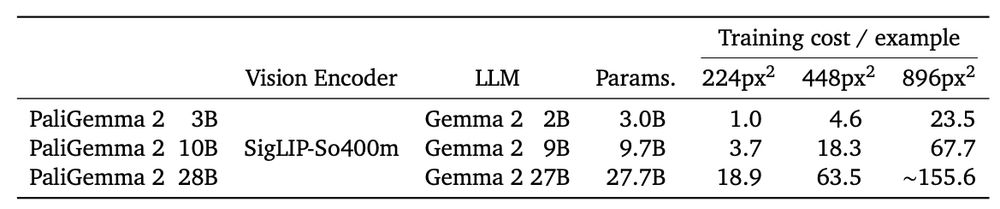
Looking for a small or medium sized VLM? PaliGemma 2 spans more than 150x of compute!
Not sure yet if you want to invest the time 🪄finetuning🪄 on your data? Give it a try with our ready-to-use "mix" checkpoints:
🤗 huggingface.co/blog/paligem...
🎤 developers.googleblog.com/en/introduci...
Check out our detailed report about *Jet* 🌊 - a simple, transformer-based normalizing flow architecture without bells and whistles.
Jet is an important part of JetFormer's engine ⚙️ As a standalone model it is very tame and behaves predictably (e.g. when scaling it up).
Attending #NeurIPS2024? If you're interested in multimodal systems, building inclusive & culturally aware models, and how fractals relate to LLMs, we've 3 posters for you. I look forward to presenting them on behalf of our GDM team @ Zurich & collaborators. Details below (1/4)
07.12.2024 18:50 — 👍 12 🔁 5 💬 1 📌 0
🚀🚀PaliGemma 2 is our updated and improved PaliGemma release using the Gemma 2 models and providing new pre-trained checkpoints for the full cross product of {224px,448px,896px} resolutions and {3B,10B,28B} model sizes.
1/7
It’s not, good catch.
03.12.2024 21:51 — 👍 0 🔁 0 💬 0 📌 0Very nice! I knew some soft-token TTS papers, but none so far using AR + normalizing flows. Thanks for sharing!
03.12.2024 09:44 — 👍 0 🔁 0 💬 0 📌 0The noise curriculum guides the (image generation) learning process to first learn high-level, global structure and later low-level structure/texture. Maximum likelihood “tends to focus” mostly on the latter.
03.12.2024 08:02 — 👍 0 🔁 0 💬 1 📌 0In arxiv.org/abs/2303.00848, @dpkingma.bsky.social and @ruiqigao.bsky.social had suggested that noise augmentation could be used to make other likelihood-based models optimise perceptually weighted losses, like diffusion models do. So cool to see this working well in practice!
02.12.2024 18:36 — 👍 52 🔁 11 💬 0 📌 0I always dreamed of a model that simultaneously
1. optimizes NLL of raw pixel data,
2. generates competitive high-res. natural images,
3. is practical.
But it seemed too good to be true. Until today!
Our new JetFormer model (arxiv.org/abs/2411.19722) ticks on all of these.
🧵
Did you ever try to get an auto-regressive transformer to operate in a continuous latent space which is not fixed ahead of time but learned end to end from scratch?
Enter JetFormer: arxiv.org/abs/2411.19722 -- joint work in a dream team: @mtschannen.bsky.social and @kolesnikov.ch
Joint work with @asusanopinto.bsky.social and @kolesnikov.ch done @googledeepind.bsky.social.
8/8
To our knowledge, JetFormer is the first model capable of generating high fidelity images and producing strong log-likelihood bounds.
So far we explored a simple setup (image/text pairs, no post-training), and hope JetFormer inspires more (visual) tokenizer-free models!
7/
Finally, why getting rid of visual tokenizers/VQ-VAEs?
- They can induce information loss (e.g. small text)
- Removing specialized components was a key driver of recent progress (bitter lesson)
- Raw likelihoods are comparable across models (for hill climbing, scaling laws)
6/
Importantly, this is simple additive Gaussian noise on the training images (i.e. a data augmentation). JetFormer does neither depend on it (or its parameters), nor is it trained for denoising like diffusion models.
5/
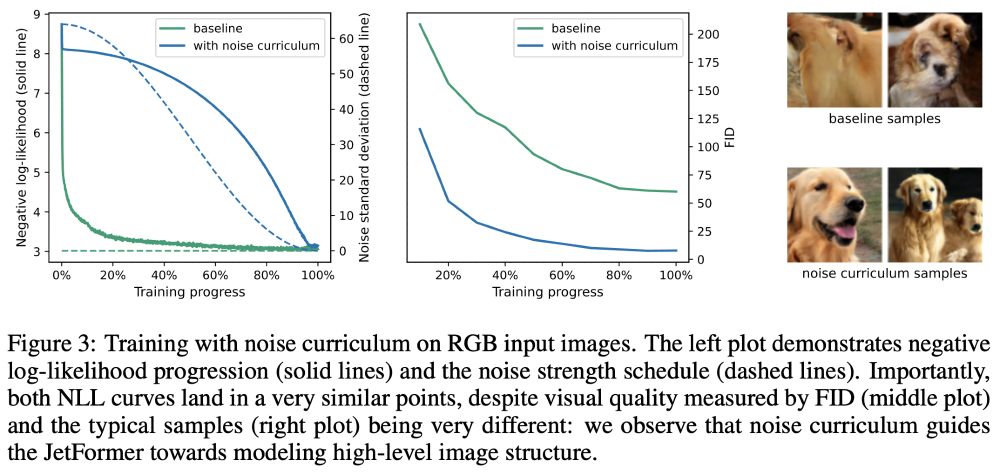
Learning to generate high-fidelity images with maximum likelihood is tricky. To bias the model towards nicer-looking images we introduce a noise curriculum: Gaussian noise added to the input image and annealed to 0 during training, s.t. high-level details are learned first.
4/
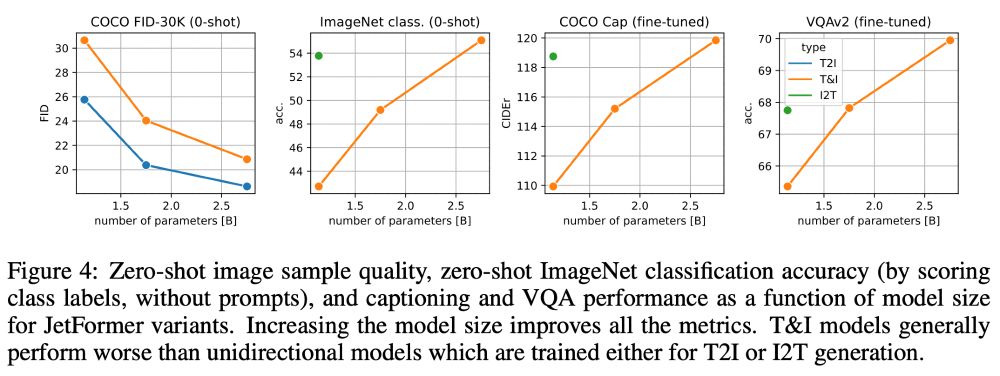
Conceptually, the normalizing flow serves as both an image encoder for perception tasks and an image decoder for image generation tasks during inference.
We train JetFormer to maximize the likelihood of the multimodal data, without auxiliary losses (perceptual or similar).
3/
We leverage a normalizing flow (“jet”) to obtain a soft-token image representation that is end-to-end trained with a multimodal transformer for next-token prediction. The soft token distribution is modeled with a GMM à la GIVT.
arxiv.org/abs/2312.02116
2/
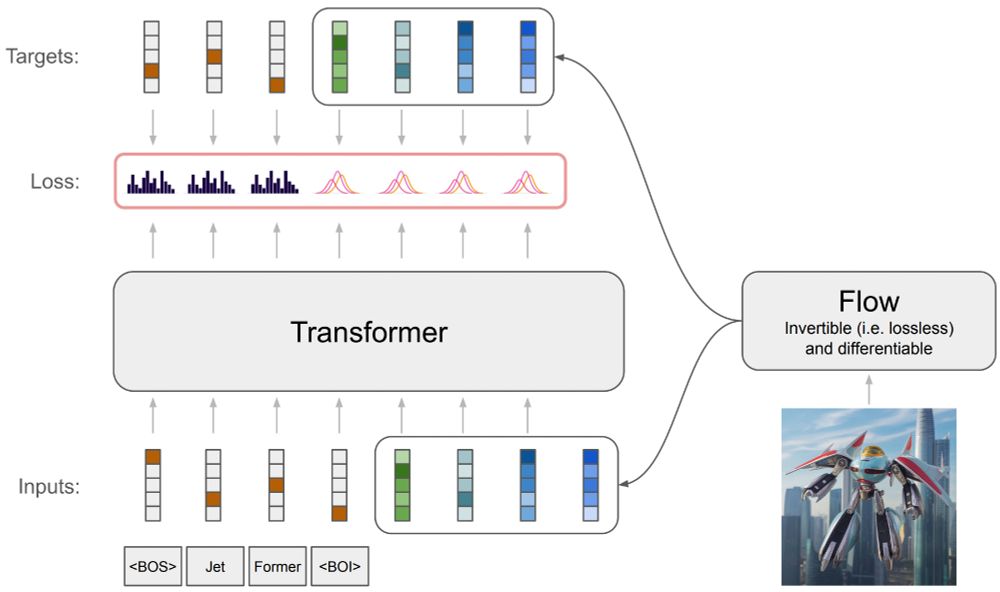
Have you ever wondered how to train an autoregressive generative transformer on text and raw pixels, without a pretrained visual tokenizer (e.g. VQ-VAE)?
We have been pondering this during summer and developed a new model: JetFormer 🌊🤖
arxiv.org/abs/2411.19722
A thread 👇
1/
Thank you!
25.11.2024 18:25 — 👍 1 🔁 0 💬 0 📌 0🙋♂️
24.11.2024 20:14 — 👍 1 🔁 0 💬 1 📌 0


















