Future directions include exploring more complex architectures, further optimising adapter design, and investigating potential quantum speedups for compound matrix operations.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0
Our findings suggest Quantum-Inspired Adapters offer a promising direction for efficient adaptation of language and vision models in resource-constrained environments. The method's adaptability across different benchmarks underscores its generalisability.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0
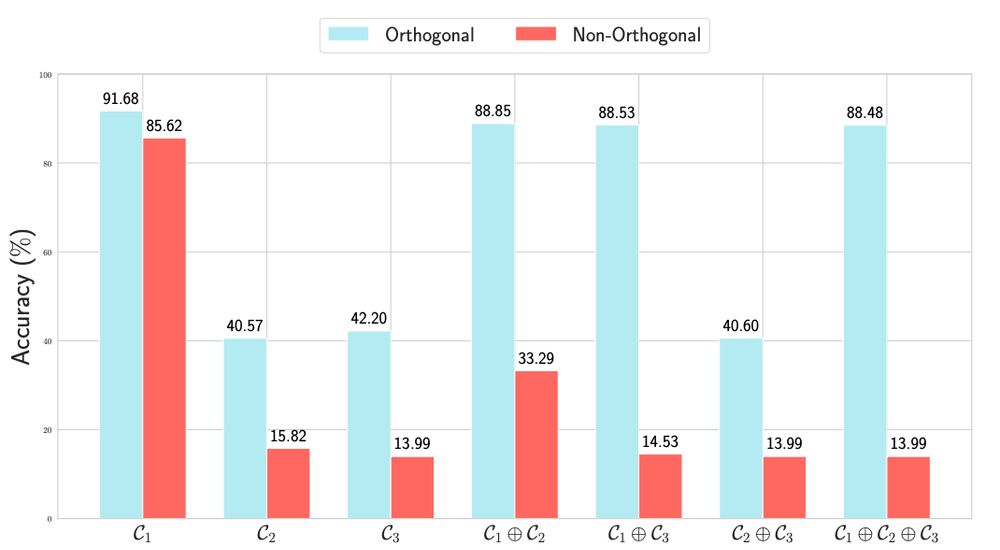
We found that combining multiple Hamming-weight orders with orthogonality and matrix compounding are essential for performant fine-tuning. Enforcing orthogonality is critical for the success of compound adapters.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0
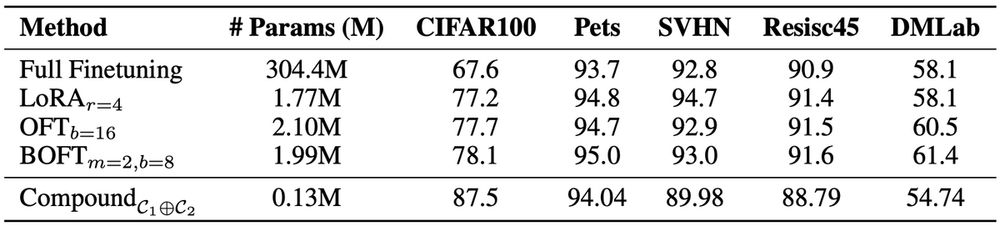
VTAB results are also promising! Our method achieves a comparable performance to LoRA with ≈ 13.6x fewer parameters. In some instances, such as CIFAR100, accuracy was significantly increased relative to other methods.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0

On GLUE, we achieved 99.2% of LoRA's performance with a 44x parameter compression. Compared to OFT/BOFT, we achieved 98% relative performance with 25x fewer parameters.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0
We tested our adapters on GLUE and VTAB benchmarks. Results show our method achieves competitive performance with significantly fewer trainable parameters compared to LoRA, OFT, and BOFT.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0
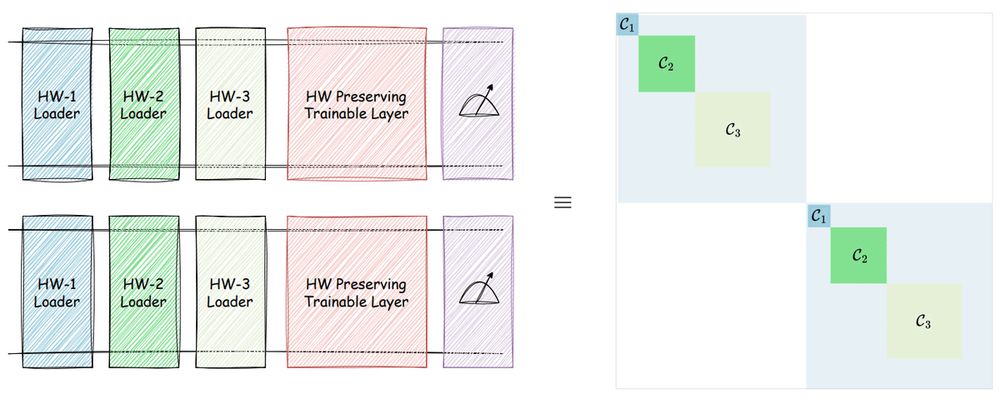
Our approach draws inspiration from Hamming-weight preserving quantum circuits to create parameter-efficient adapters that operate in a combinatorially large space while preserving orthogonality in weight parameters.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0
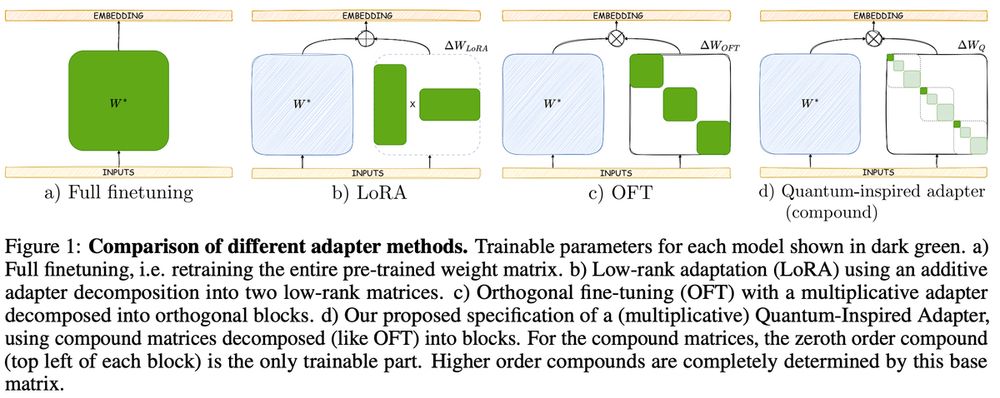
Fine-tuning large models is computationally expensive. This challenge has spurred interest in parameter efficient methods like LoRA which aim to adapt large foundation models to new tasks by updating only a small subset of parameters or introducing lightweight adaptation modules.
12.02.2025 14:57 — 👍 0 🔁 0 💬 1 📌 0
PhD student in theoretical quantum physics at the University of Sydney
Building distributed quantum systems
Grad student in quantum @Uni of Edinburgh
Previously: IBM Q & Cisco R&D
Also find me in : https://linktr.ee/grageragarces
Researcher in quantum error correction and fault-tolerant quantum computation (Alice&Bob, Paris, France).
He/Him
Quantum physicist with a focus on the fundamental aspects of the theory. Blog at www.quantumquia.com
PhD student @ Eisert Group, FU Berlin. Quantum Information Theory
Experimental quantum physicist working on dipolar supersolids based on ultracold magnetic atoms at @dysprosiumlab.bsky.social
MIT PhD, now Postdoc at Columbia Center For Computational Electrochem
I study how materials work using computational and mathematical methods. ardavanfarahvash.com
Likes to spend days struggling with quantum mechanics.
PhD Candidate, Institut de Mathematiques de Toulouse. Quantum Information, Symmetries, Tensors, and their ε-neighbourhood.
PhD student working in quantum computing at the University of Maryland, College Park.
Husband. Dad. Researcher | NRC Postdoctoral Research at NIST Ion Storage | Open Source Quantum.
Condensed Matter Theory Postdoc at CNLS. Interests include frustrated magnetism, random circuits, and benchmarking quantum hardware.
Quantum Algorithms Researcher at Fraunhofer IAO
Feminist | Democrat | Pro-Choice | Pro-LGBT | Spiritual | Producer | Artist | Writer | Actor | Traveller | Human Rights proponent | Trans Rights Advocate | Mental Health Matters | Music Lover.
Christian. Quantum experimental physicist and science writer. PhD @ UBC ECE. 2025 Xanadu resident. Former Software Eng @ Photonic Inc. MSc Quantum Info Sci @ UWaterloo. BSc CS and Physics @ Laurier. Views my own.
IZTECH-Chemistry, I like to be Polymath(learning different subjects), Polygot(interested in the learning different languages) comments and opinions are my own RT≠ is not endorsement (he/him)





















