just realized bsky doesn't support gifs lol
15.12.2024 14:40 — 👍 1 🔁 0 💬 0 📌 0
functions can even compose, here's the model using the output of one as the input into another
13.12.2024 20:24 — 👍 0 🔁 0 💬 1 📌 0
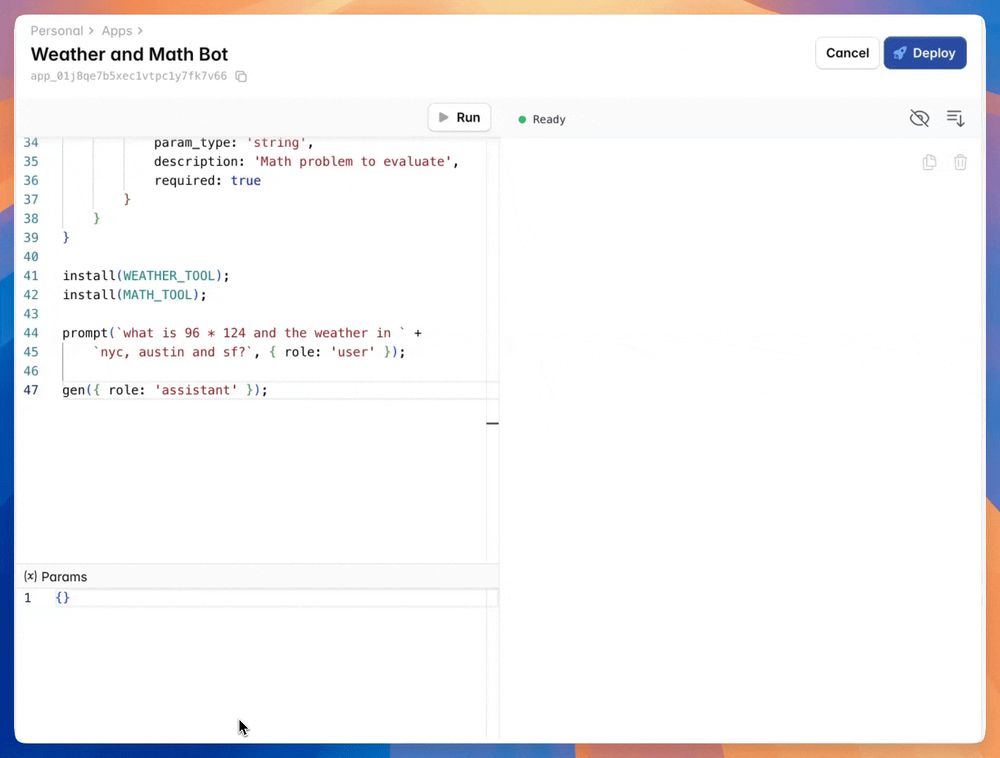
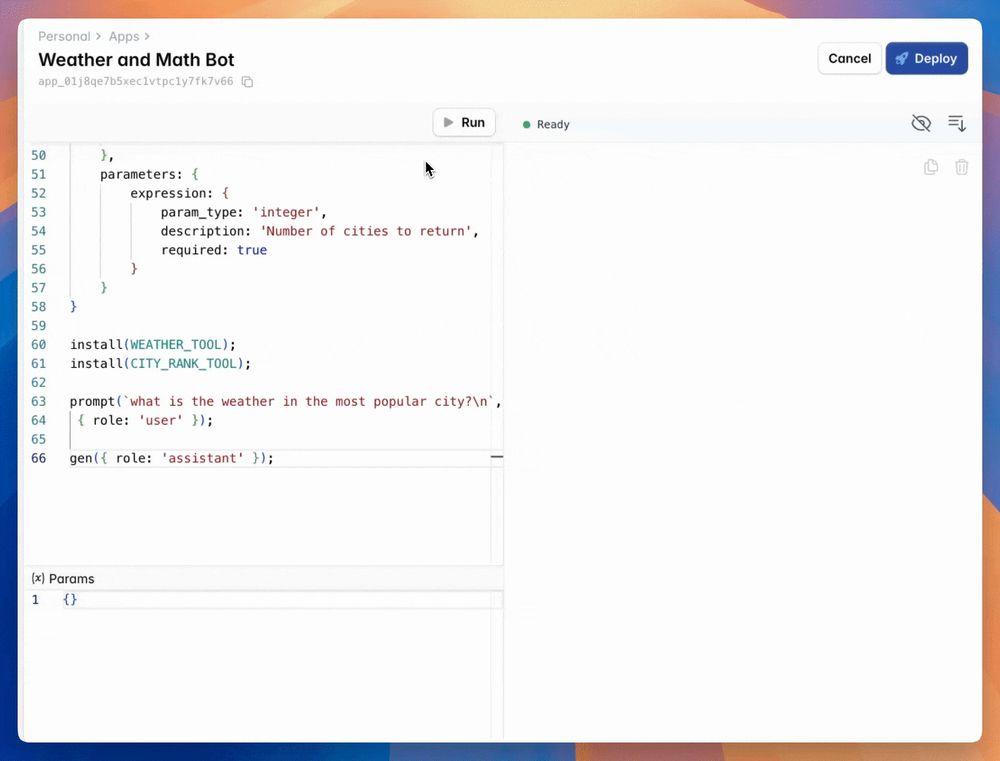
one of the most slept on capabilities of newer AI models is the ability to call multiple tools in a single shot. here's the newest llama 70b running on mixlayer calling 4 tools (lookup weather in 3 cities and perform some arithmetic)
13.12.2024 20:24 — 👍 2 🔁 0 💬 1 📌 0
weird that the instruction tuned Llama3 8b models are downloaded less than the original?
04.12.2024 15:53 — 👍 0 🔁 0 💬 1 📌 0
I doubt they switch to a lower precision model, but would not be surprised if they start using a quantized or fp8 KV cache. Much easier to switch out dynamically in response to load vs the model weights.
23.11.2024 17:43 — 👍 0 🔁 0 💬 0 📌 0
woke up in a 3am fit of terror last night bc I dreamt I left an 8x a100 gpu cluster running by accident 🫠
17.11.2024 13:58 — 👍 2 🔁 0 💬 0 📌 0
it was not like nothing else but i'll describe it with average words
💙🧡
meows.zip
✨ Weird CAD and graphics research
⚙️ Embedded software and Rust
🌎 Cambridge, MA
🏠 mattkeeter.com
Former Hootsuite + Commit founding team, working on something new.
CTO & Co-founder of projectread.ai. Previously at Figma.
Biochem, microbio, and protein science. Learning Rust for machine learning.
LLMs, AI, Psychology and Speaking - Seeking to infuse technology with empathy. That's why I founded www.neuroflash.com. An AI platform driving brand-aligned marketing, and helping people connect and understand each other's perspectives.
Co-Chair, Arnold Ventures
Data Scientist | Computer Vision Engineer | AI Educator | Hugging Face Fellow 🤗 // johko.github.io //
Book: https://thecon.ai
Web: https://faculty.washington.edu/ebender
Researcher trying to shape AI towards positive outcomes. ML & Ethics +birds. Generally trying to do the right thing. TIME 100 | TED speaker | Senate testimony provider | Navigating public life as a recluse.
Former: Google, Microsoft; Current: Hugging Face
Climate & AI Lead @HuggingFace, TED speaker, WiML board member, TIME AI 100 (She/her/Dr/🦋)
A LLN - large language Nathan - (RL, RLHF, society, robotics), athlete, yogi, chef
Writes http://interconnects.ai
At Ai2 via HuggingFace, Berkeley, and normal places
ML Engineering @adobe
Previously: @huggingface
Data Visualization Enthusiast | Latent Space Explorer
ML/AI researcher & former stats professor turned LLM research engineer. Author of "Build a Large Language Model From Scratch" (https://amzn.to/4fqvn0D) & reasoning (https://mng.bz/Nwr7).
Also blogging about AI research at magazine.sebastianraschka.com.
forget this i didn’t know you can share block lists here. call me when you fixed this
Always growing, she/her, RAG builder, LLM whisperer, tech generalist
Penguin of great renown.
The penguin revolution is nigh, only the feathered and the tuxedoed will be spared.
Except for seagulls, they can get fucked.
https://pngwn.at




















