Listen along and learn a bit more about how they efficiently solve this issue ⤵️
17.07.2025 15:22 — 👍 1 🔁 0 💬 0 📌 0
I sat down with Roman Kolesnev and learned that Streambased is building out a product that solves this problem exactly! Allowing your #apacheKafka data to be indexed and available immediately (without copying) and queryable through databases, open table formats like #apacheIceberg, or file systems.
17.07.2025 15:22 — 👍 0 🔁 0 💬 1 📌 0
But when the time comes to use your infinite data, how do you find the *right* data? #apacheKafka is a log. And even with smart partitioning, you still have to re-stream most of the data in order to find the specific account or key that you're looking for. 🔎
17.07.2025 15:22 — 👍 0 🔁 0 💬 1 📌 0
🔙 Back Fill. Use the history of events to rebuild state in other applications/databases.
😰 Anxiety? You don't quite know what you'll do with that data now, but you might need it someday!
17.07.2025 15:22 — 👍 0 🔁 0 💬 1 📌 0
📊 Time Travel Analytics. Having the entire history of data means you can easily go back to any time period and analyze those events for fraud, debugging, etc.
📑 Auditing and Regulatory. Certain industries/companies are required to retain data for a specific length of time
17.07.2025 15:22 — 👍 0 🔁 0 💬 1 📌 0
Infinite storage in #apacheKafka is all the rage. But what exactly is your plan when you decide to keep years' worth of data in Kafka topics? 🤔
From what I've seen, folks opt in for infinite storage for a few reasons:
17.07.2025 15:22 — 👍 1 🔁 0 💬 2 📌 0
I also had a chance to work with Yufei Gu, the Polaris 1.0 release manager, to put together a blog that highlights the most important parts of this release. 👇
www.snowflake.com/en/engineeri...
11.07.2025 16:48 — 👍 2 🔁 0 💬 0 📌 0
It's been a great week because the #apachePolaris (incubating) community just announced a milestone release with version 1.0!
Want to know what's included? You're in luck, because there's a release video for that! 📹
www.youtube.com/watch?v=ST8P...
11.07.2025 16:48 — 👍 5 🔁 0 💬 1 📌 0
I'll consult your calendar for the next one! 😉
10.07.2025 19:26 — 👍 0 🔁 0 💬 1 📌 0

Snowflake + LlamaIndex Data Agent Builders Meetup Amsterdam · Luma
Join local AI engineers, data scientists, and builders for an evening of hands-on talks and open discussion around one challenge we all care about: building…
Hello, #amsterdam-based #AI enthusiasts! Let's have a meetup!
On July 31, LlamaIndex and Snowflake are coming together to host folks for an evening of discussion around building effective data agents.
Register now to secure your slot! 🎟️
lu.ma/vzwsj72w
10.07.2025 16:47 — 👍 3 🔁 0 💬 1 📌 0
We'll talk all things #apacheIceberg, #dataLakehouse, open table formats, and more. This is a great chance to connect with #openSource community members like @russellspitzer.bsky.social, stay up to data on what's new in the space, and learn more about the open lakehouse movement.
26.06.2025 18:05 — 👍 5 🔁 1 💬 1 📌 0
📖 enjoy creating developer-focused content around #openSource #dataEngineering technologies (think #apacheIceberg, #postgres, #apacheNifi, and more)
🫂 love building, supporting, and championing the technical community
... then this just might be the role for you!
25.06.2025 16:55 — 👍 2 🔁 0 💬 1 📌 0
If you...
🏛️ have experience with #openSource foundations (like the Apache Software Foundation, Linux Foundation, etc.)
⚙️ want the opportunity to work closely with and drive our evolving #OSPO
25.06.2025 16:55 — 👍 2 🔁 0 💬 1 📌 0
Not convinced? Let's hear from Lester Martin, #starburst, on why else you should care and give #apacheNifi a try 👇
24.06.2025 17:14 — 👍 0 🔁 0 💬 0 📌 0
What about from a #Snowflake perspective?
#apacheNifi is the foundation for Snowflake's data integration service, #openFlow. It's especially useful for multi-modal datasets that you might need for your #AI workflows.
docs.snowflake.com/en/user-guid...
24.06.2025 17:14 — 👍 0 🔁 0 💬 1 📌 0
#apacheNifi is an #openSource data workflow tool that's great for #etl, #dataStreaming ingestion, and #dataProcessing pipelines. Its drag-and-drop, no-code interface that makes it easy for developers and #dataEngineering folks to get started.
nifi.apache.org
24.06.2025 17:14 — 👍 2 🔁 0 💬 1 📌 0

Have you heard about #apacheNifi? No, well here's your chance to learn a bit about it! 🧵
24.06.2025 17:14 — 👍 3 🔁 0 💬 1 📌 0
YouTube video by Snowflake Developers
Snowflake Summit 2025 Builders Keynote
#snowflakeSummit is over, but all of the keynotes are up on our #Snowflake Youtube channels! For no reason at all, start with the Builders keynote. 😉
See #agentic workflows in action, an #apacheIceberg #dataMesh, and how the community is coming together on #AI.
www.youtube.com/watch?v=slyY...
23.06.2025 17:22 — 👍 2 🔁 0 💬 0 📌 0

Seattle Apache Iceberg™ Community Meetup · Luma
Seattle Apache Iceberg™ Community Meetup! 🧊❄️🍦
Join us on July 15th (Tuesday) from 5:00-8:30 PM
At Snowflake Bellevue Office
Connect with fellow enthusiasts,…
The #apacheIceberg meetup series continues in the #seattle area with a stop at the brand new Snowflake office in Bellevue! ❄️
Join fellow Iceberg enthusiasts, committers, and users on July 15th for networking, great technical discussions, and more! RSVP to reserve your spot. 🎟️
lu.ma/q9w0j1ky
18.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0

Apache Iceberg™ Europe Community Meetup - July 2025 Edition · Luma
Apache Iceberg™ Meetup Europe - live in Berlin! 🌍
Join us for the very first Apache Iceberg™ Meetup Europe in Berlin! Our event is hosted in Berlin,…
Psst, did you know that there's an #apacheIceberg meetup coming to #berlin in just a few weeks?
Join fellow community members at Snowflake's Berlin office for a night of networking and technical discussion around the #openLakehouse!
👉 lu.ma/pposobem
17.06.2025 07:04 — 👍 1 🔁 0 💬 0 📌 0
This means that any organization (large or small) can use Polaris and rest assured that it can scale with them and their users. 💥
Check out the blog to learn more about the refactor, what went into it, and more specifics around the benchmarking the team used. 👇
medium.com/snowflake/ap...
12.06.2025 17:47 — 👍 0 🔁 0 💬 0 📌 0
What do you get out of it? 🤔
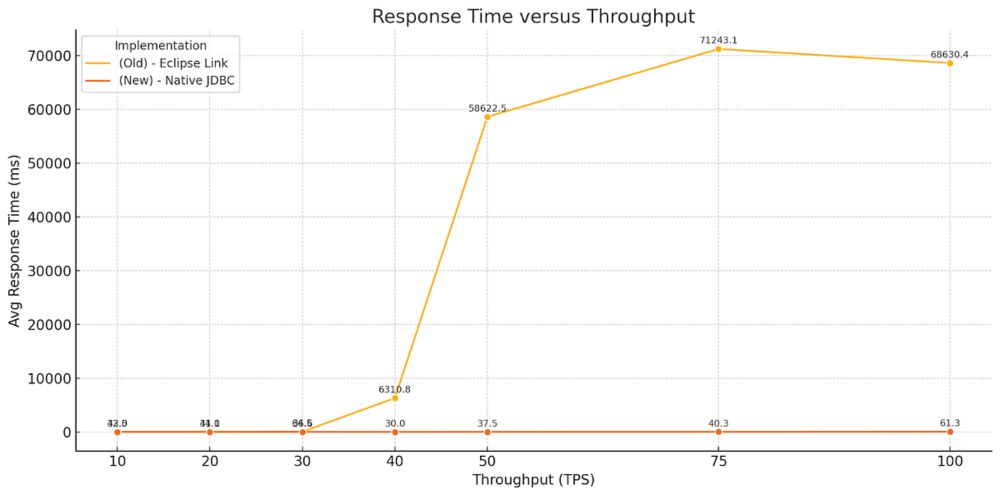
✅ Better reliability and performance on both concurrent and sequential operations
✅ Improved scalability of Polaris
✅ Easier to manage deployments due to a simpler schema and better configurability
12.06.2025 17:47 — 👍 0 🔁 0 💬 1 📌 0
Apache Polaris™ (incubating) Now Supports 3X Concurrent Transactions with New Relational JDBC…
Note: Apache Polaris is currently undergoing Incubation at the Apache Software Foundation
NEWS: The #openSource #apachePolaris community has just refactored the catalog persistence layer, delivering an awesome performance boost for users!
Specifically, a new JDBC-based persistence layer has taken the place of the old EclipseLink backend.
medium.com/snowflake/ap...
12.06.2025 17:47 — 👍 5 🔁 0 💬 2 📌 0

Snowflake’s Native Support for Apache Iceberg Tables
Build secure, high-performance pipelines with native Apache Iceberg support in Snowflake—enabling seamless batch, streaming, and AI-driven data workflows.
I'm looking forward to seeing what's next as we continue building out our native support for all Iceberg workflows! Learn more about all we have to offer 👇
www.snowflake.com/en/product/f...
And, of course, watch this space for even more! 👀
12.06.2025 16:29 — 👍 0 🔁 0 💬 0 📌 0
Principal Developer Advocate @ Snowflake
- Hands-on @ https://github.com/iamontheinet
- Nature, Landscape, and Abstract Photog @ natureunraveled.com
- LinkedIn @ https://www.linkedin.com/in/dash-desai
The global home for open source software, powering some of the world’s most ubiquitous software projects in web, big data, Java, IoT, cloud computing, and more. Learn more at https://apache.org.
Technologist. Event-Driven Architectures and Data. Author of O'Reilly's "Building Event-Driven Microservices" and "Building an Event-Driven Data Mesh".
Work. Life. Code. Game. Lather. Rinse. Repeat. — Husband and father of three. Son of mountain men. Geek. Graybeard. Gamemaster. Works at @redis.io. W8GUY.
She/her. 🏳️🌈👩🏽💻
I like to create things and connect people! Lead Developer Advocate interested in all things Web/Mobile/DevOps/Testing.
Vue Fangirl 💚 Atlanta JavaScript organizer 🍑 Dog picture aficionado 🐶 Definitely a human 🤖
Senior Developer Advocate at Confluent
Based in Raleigh, NC
#Indigenous in tech
All things #datastreaming #apachekafka #apacheflink #java
I'll talk sports - especially golf and basketball - all day
Taking a breather from politics for a minute... whew..
Kafka Streams Specialist at Michelin 🦦 - French - passionate about discussing #Kafka, #EventDrivenArchitecture, #Programming, #Scrum, #Agile, #Dev, #Japan 🗾, and many other topics😉... Love building solutions with my 🧠 but above all, with my ♥️.
Product @ Confluent
Opinions my own
🇨🇦
And this is where you add a funny & creative bio
Committer & PMC member @ Apache Kafka
Software developer @ Responsive
Convinced otter 🦦
Responsive is a stream processing solution that adds disaggregated state, autoscaling, observability, and enterprise-grade support to Kafka Streams.
-> https://www.responsive.dev/
Apache Kafka PMC/committer, Founding Engineer at Responsive, Kafka Streams dev/fan, otter advocate. My debugging rubber duck is a 5 ft giraffe, please refer any questions to him
Genius, billionaire, playboy, and philanthropist. This is Tony Stark. I'm Ricardo, one who believes this 💩 is chocolate yogurt.
https://riferrei.com
Entrepreneur, software engineer, non-conformist.
🔥 Creator of shadowtraffic.io
Data nerd, “recovering data scientist”, author, podcaster, occasional athlete
Co-Founder of @responsive.dev. Views are my own.
Developer 🥑 Advocate at Decodable, Ex-Red Hat, formerly Engineer/Trainer/Consultant - also proud husband, 🦁 hearted dad of 2 and ☕️ aficionado.
Head of Event Operations Devoxx UK
Virtual JUG Leader | OpenUK Volunteer Manager
Jfokus founder, Java Champion, JUG leader, Software Vagabond, Family father, Motorcyclist & Kiva supporter. Check out @jfokus.bsky.social