@jayaprabhakar.bsky.social Interesting read on formal verification.
09.12.2025 16:50 — 👍 2 🔁 0 💬 0 📌 0
YouTube video by Apache Iceberg™ Meetup
Iceberg Use Cases at DoorDash
Short talk on Iceberg use cases in last week's Seattle Iceberg meetup.
youtu.be/F7qpOVVnxek?...
31.10.2025 02:42 — 👍 1 🔁 0 💬 0 📌 0
It has three increasingly more verbose levels of description. They are probably trying to optimize the initial set of searches. And with markdown based skills, custom workflows are approachable for a broader audience compared to MCP, and probably safer too.
It is only available in Claude desktop.
31.10.2025 02:40 — 👍 2 🔁 0 💬 0 📌 0
Tools, prompts, sampling - all these seem to be a result of generalizing how Claude code / research feature was built over time, and extracting ask out of those patterns. Uniformity is the biggest and probably only benefit.
And maybe the goal is not about solutions that spend less tokens?
29.09.2025 22:48 — 👍 2 🔁 0 💬 0 📌 0
Intend to follow this along. Done with chapter 1, looking forward to the next one!
28.09.2025 01:23 — 👍 1 🔁 0 💬 0 📌 0
2/ This mindset improves productivity and outcome significantly overtime.
27.09.2025 20:59 — 👍 2 🔁 0 💬 0 📌 0

Time to Adapt and Become a Better Engineer
A colleague recently asked if I think AI agents could do all the jobs humans do. My answer was an unequivocal yes. Given the same sensory…
1/ Nice read:
medium.com/@xiafan/time...
Software engineer growth in AI era:
* Build composable tools.
* Assume non deterministic outcomes from a group of ai agents.
* Understand how LLM works to the next level, like how you would understand to read a query plan.
27.09.2025 20:58 — 👍 2 🔁 0 💬 1 📌 0
SQLync
Just added sqlync.com to SlateDB's adopters list! They're building a streaming system that speaks MQTT or PostgreSQL across millions of connected users and devices. 🤯
25.08.2025 19:05 — 👍 4 🔁 1 💬 0 📌 0
3/ And as an extension, how it handles maintenance operations such as vacuum on iceberg tables dones out of band.
24.08.2025 14:20 — 👍 3 🔁 0 💬 0 📌 0
2/ I assume the iceberg writes uses iceberg open source libraries. This would ensure the write part continues to evolve with iceberg advancements.
I don't yet know if this handles compacted topics (which would introduce deletes on iceberg)
24.08.2025 14:19 — 👍 2 🔁 0 💬 1 📌 0

Introducing Tableflow: Unifying Streaming and Analytics
Seamlessly integrate Apache Kafka data into your lakehouse as Apache Iceberg or Delta Lake tables, bridging the operational and analytical divide, with Tableflow. Read more in our blog post.
1/ Leveraging Remote storage manager and storing Kafka segments as parquet files + iceberg metadata is really good. Avoids having to consume, serialize and manage a separate process.
I wonder if confluent's TableFlow launched about a year back has a similar design. www.confluent.io/blog/introdu...
24.08.2025 14:15 — 👍 1 🔁 0 💬 1 📌 0
Love the idea. Could some of these eventually become sub projects, and hosted in the SlateDB organization as a separate repo? Starting projects that have that potential as GitHub issues with a specific tag would make it easy to track.
07.07.2025 01:37 — 👍 1 🔁 0 💬 1 📌 0
Insane amount of SlateDB work going on:
- snapshot reads
- split/merge DBs (zero copy)
- deterministic simulation testing
And someone just pushed Python bindings in a PR! 🤯
18.06.2025 14:48 — 👍 9 🔁 3 💬 0 📌 0
YouTube video by Data Council
Internals of SlateDB: An Embedded Key Value Store Built On Object Storage
My Data council talk on SlateDB.
youtu.be/gcTRXZeKbNg?...
30.05.2025 05:33 — 👍 22 🔁 3 💬 0 📌 0
Got it. So, if I wanted a view to update, say once an hour incrementally, would I create a "hourly view" that uses now() and join against it?
27.05.2025 16:53 — 👍 2 🔁 0 💬 1 📌 0
Clock tick as an input is indeed a way to model it! Would the clock tick table be joined in all views that need this property?
27.05.2025 14:45 — 👍 0 🔁 0 💬 1 📌 0
Finally got to read this.
One additional aspect to ivm, is reasoning about the data in the computed. For a lot of use cases, it is often easy to think of a view/table to move in predictable increments (day, hour, 15 minutes etc). This notion is not modeled as a first class concept in many.
26.05.2025 23:28 — 👍 1 🔁 0 💬 1 📌 0

SlateDB 0.6.0 is out!
github.com/slatedb/slat...
Highlights include a hybrid cache (using Foyer), a lot of internal cleanup, and more groundwork for transactions.
Oh, and put performance jumped ~80% for write-heavy workloads :)
slatedb.io/performance/...
24.04.2025 19:04 — 👍 8 🔁 1 💬 0 📌 0

SlateDB - An embedded storage engine built on object storage | SlateDB
Description will go into a meta tag in <head />
Today marks SlateDB’s one year anniversary! It’s been a lot of fun. Thanks to @rohanpd.bsky.social @flaneur2024.bsky.social @almog.ai @vigneshc.bsky.social @paulbutler.org Jason Gustafson, David Moravek, and many others for joining the project. 😀
22.04.2025 21:55 — 👍 16 🔁 5 💬 0 📌 1

🎂 Commonhaus Turns One — A Look Back, and the Road Ahead
Commonhaus Foundation celebrates its first anniversary and lays down expectations for its future
Commonhaus is 1! 🎂
14 projects, solid foundations, and more on the way.
If you believe in light governance, shared care, and thoughtful support for open source, come see what we’re building.
www.commonhaus.org/activity/253...
10.04.2025 14:05 — 👍 31 🔁 19 💬 0 📌 1

Yo SF Bay Area #databs crew, want to talk lakehouses at a real Lake House? :)
Next week after Data Council, join the founders of @clickhouse.com, @motherduck.com, @startreedata.bsky.social, and @tobikodata.com to talk real-time databases and next-generation ETL.
www.rilldata.com/events/data-...
15.04.2025 23:44 — 👍 10 🔁 3 💬 1 📌 0
Release v0.5.0 · slatedb/slatedb
What's Changed
Refactor Block Tests to Use Table-Driven Test Cases by @samsond in #410
Update await calls in README.md by @criccomini in #425
chore: Apply table driven test for sst.rs by @jeffreyl...
SlateDB 0.5.0 is out!
Features:
- Checkpoints
- Clones
- Read only client
- Split/merge database foundation
- TTL filtering on reads
- Last version with breaking byte format changes
By the numbers:
- 62 commits
- 2 new contributors
- 10 total contributors
github.com/slatedb/slat...
17.03.2025 17:23 — 👍 22 🔁 3 💬 2 📌 1
CALL FOR GRAND CHALLENGE SOLUTIONS
DEBS2025
DEBS conference hosts a grand challenge every year. This year's challenge is detecting outliers in a stream of images from laser powder bed fusion.
The challenge involves submitting a kubernetes app (constraint: 2 cores 8 gb). Interesting to try if you have the time!
2025.debs.org/call-for-gra...
23.02.2025 18:40 — 👍 1 🔁 0 💬 0 📌 0
Great episode!
Towards the end @vanlightly.bsky.social mentions about alloytools.org finding a data model bug.
Never thought of an intersection between data model and formal verification. Do you have more details on this?
15.02.2025 04:06 — 👍 0 🔁 0 💬 1 📌 0
Python Folks - which data/workflow engine has the best developer experience for packaging code? We have looked into - Modal, Beam, Airflow, Flyte, AWS Lambda, Prefect, Dagster and Spark. Haven’t seen any approach which is fast, reliable and intuitive.
17.12.2024 16:09 — 👍 10 🔁 2 💬 6 📌 0
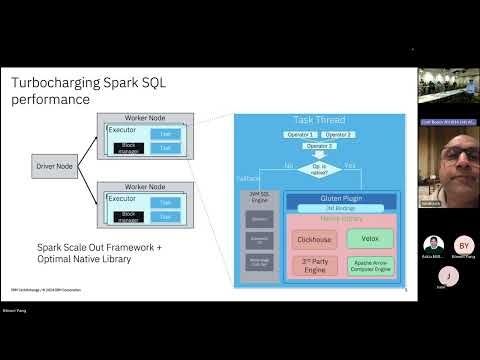
YouTube video by BDB
Big Data Bellevue: Apache Gluten: Accelerating SparkSQL with Spark on Velox
Great talk by Binwei Yang on Apache Gluten last week.
youtu.be/GWTj3INSzPg?...
Apache Gluten moves execution of spark operators to native backend like Velox, accelerating query performance.
It has basic iceberg support too!
github.com/apache/incub...
19.01.2025 02:06 — 👍 1 🔁 0 💬 0 📌 0
The financial transactions database designed to power the next 30 years of online transaction processing.
Mostly posts about PostgreSQL, Snowflake Postgres, and PostgreSQL extensions.
Formerly Crunchy Data, Microsoft, Citus Data, AWS, TCD, VU
http://github.com/frankmcsherry/blog
A programming language empowering everyone to build reliable and efficient software.
Website: https://rust-lang.org/
Blog: https://blog.rust-lang.org/
Mastodon: https://social.rust-lang.org/@rust
Co-founder arroyo.dev, building next-gen streaming systems. Prev Splunk, Lyft, Sift, Quantcast.
search every byte 🔍 {vector, full-text} search engine built from first principles on object storage. 10x cheaper, scales to 100B. powers Notion, Cursor, Linear
The global home for open source software, powering some of the world’s most ubiquitous software projects in web, big data, Java, IoT, cloud computing, and more. Learn more at https://apache.org.
The unoffical Apache Kafka Streams account. Long live the otter.
Serverless, databases, and serverless databases at AWS. Views my own.
Check out my blog: https://brooker.co.za/blog/
Committer & PMC member @ Apache Kafka
Software developer @ Responsive
Convinced otter 🦦
The Proceedings of the VLDB Endowment (PVLDB)
https://vldb.org/pvldb/
RSS Feed: https://db.cs.cmu.edu/files/rss/pvldb-rss.xml
Automated by @andypavlo.bsky.social
Apache {DataFusion PMC}, Database Internals
Building distributed systems and data infra.
Previously co-creator of Apache Flink (https://flink.apache.org/),
now building Restate (https://restate.dev/) to make distributed apps more easily resilient and scalable.
Systems engineer @turbopuffer.bsky.social. Former CTO @materialize.com.
CEO @ feldera.com, the incremental compute engine for AI, ML and data teams.
Formerly a systems researcher in distributed systems, databases, cloud, OS, PL, and networking. Sci-fi and gaming nerd.
lalith.in/research
maintainer of SlateDB
loves Rust, Datasys, Cloud Infra, AI
https://flaneur2020.github.io
breaking databases @tur.so W1 '21 @recursecenter.bsky.social
excited about databases, storage engines and message queues
ceo & cofounder of turbopuffer.com. prev infra @Shopify 🇩🇰->🇨🇦