Drew’s post is well worth reading as DSPy seems to be a missing link in thinking about LLM usage. Very readable and interesting. www.dbreunig.com/2025/06/10/l...
Thank you @simonwillison.net
06.10.2025 11:42 — 👍 2 🔁 1 💬 0 📌 0
YouTube video by Databricks
Let the LLM Write the Prompts: An Intro to DSPy in Compound AI Pipelines
If you've been trying to figure out DSPy - the automatic prompt optimization system - this talk by @dbreunig.bsky.social is the clearest explanation I've seen yet, with a very useful real-world case study www.youtube.com/watch?v=I9Zt...
My notes here: simonwillison.net/2025/Oct/4/d...
04.10.2025 23:05 — 👍 100 🔁 13 💬 7 📌 3

#pydatabos interesting! How the Arbor library works under the hood hand in hand with DSPy
15.10.2025 23:42 — 👍 3 🔁 1 💬 0 📌 0
premature optimization is the sqrt of all evil
29.10.2025 16:26 — 👍 3 🔁 0 💬 0 📌 0

#pydatabos one line motivation for using DSPy!
15.10.2025 23:56 — 👍 3 🔁 1 💬 0 📌 1
Stop what you are doing and try out GEPA now!
"GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning" presents such elegant ideas by a collection of amazing researchers!
Here is a tldr of how it works:
21.10.2025 15:03 — 👍 3 🔁 2 💬 1 📌 0
Btw there’s no trouble in storage at all either.
ColBERT vectors are often 10 bytes each. Ten bytes. That’s like 4 numbers.
It’s not “many vectors work better than one vector”. It’s “set similarity works better than dot product”.
Even with the same storage cost.
28.09.2025 02:20 — 👍 2 🔁 0 💬 1 📌 0

A diagram illustrating a dual-encoder retrieval model using MaxSim scoring.
• On the left (green box): labeled “Query Encoder, f_Q”. It takes a Query as input and produces multiple vector embeddings (rectangles).
• On the right (blue box): labeled “Document Encoder, f_D”. It takes a Document as input and produces multiple vector embeddings (rectangles). This block is marked with “Offline Indexing” along the side, showing that documents are pre-encoded.
• Between the two encoders: dotted and solid arrows connect query embeddings to document embeddings, representing similarity comparisons.
• Each comparison goes through a “MaxSim” operation (highlighted boxes), which selects the maximum similarity for each query token across document tokens.
• At the top: outputs of MaxSim flow into a summation node (Σ) to produce a single score for ranking.
This shows the ColBERT (Contextualized Late Interaction) retrieval framework: query and document are encoded separately, interactions are computed via maximum similarity per query token, and results are aggregated into a score.
colbert-muvera-micro a 4M(!!) late interaction model
late interaction models do embedding vector index queries and reranking at the same time leading to far higher accuracy
huggingface.co/NeuML/colber...
19.09.2025 11:15 — 👍 14 🔁 1 💬 2 📌 0
Let the Model Write the Prompt | Drew Breunig #dspy #promptengineering #llms #generativeai
19.06.2025 15:54 — 👍 2 🔁 1 💬 0 📌 0
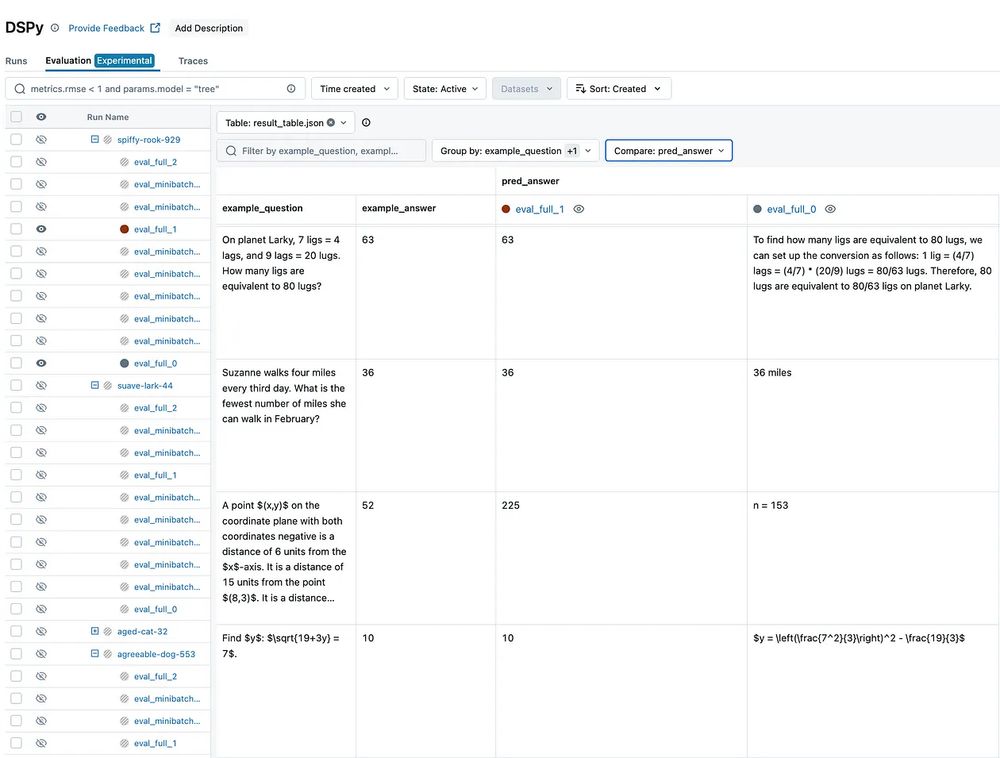
Have you heard the news? #MLflow now supports tracking for DSPy optimization workflows—just like it does for #PyTorch training!
Keep reading to see what this means for your #LLM projects… 👇
#opensource #dspy #oss
30.05.2025 15:08 — 👍 7 🔁 3 💬 1 📌 0

MLflow Community Meetup | April 23 · Luma
Join us for the next MLflow Community Meetup — Wednesday, April 23 at 4PM PT!
We’re bringing two exciting presentations to the community:
🔹 MLflow + DSPy…
📣 TODAY at 4PM PT - MLflow Community Meetup!
🔗 Register today 👉 lu.ma/mlflow423
Join the global MLflow community for two exciting tech deep dives:
🔹 MLflow + #DSPy Integration
🔹 Cleanlab + #MLflow
🎥 Streaming live on YouTube, LinkedIn, and X
💬 Live Q&A with the presenters
#opensource #oss
23.04.2025 19:21 — 👍 6 🔁 1 💬 1 📌 0
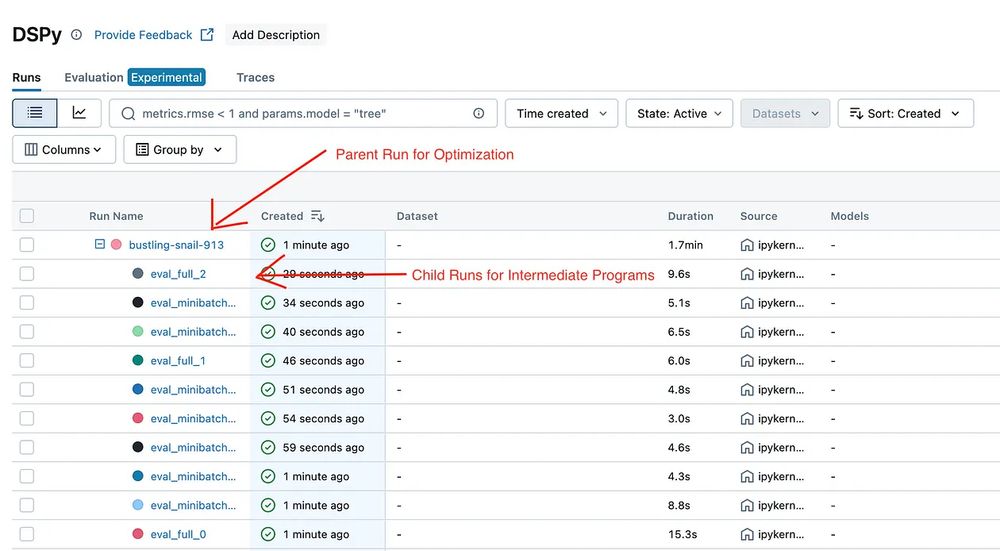
MLflow now supports tracking for #DSPy (Community) optimization — just like it does for @pytorch.org training! 🙌
#MLflow is the first to bring full visibility into DSPy’s prompt optimization process. More observability, less guesswork.
Get started today! ➡️ medium.com/@AI-on-Datab...
#opensource
21.04.2025 19:20 — 👍 5 🔁 3 💬 1 📌 0

MLflow Monthly Meetup · Luma
Join us for the next MLflow Community Meetup — Wednesday, April 23 at 4PM PT!
We’re bringing two exciting presentations to the community:
🔹 MLflow + DSPy…
Join us for the next MLflow Community Meetup — Wednesday, April 23 at 4PM PT! 🗓️
🔹 Explore the new MLflow + #DSPy integration
🔹 Learn how Cleanlab adds trust to AI workflows with MLflow
💬 Live Q&A + demos
📺 Streamed on YouTube, LinkedIn, and X
👉 RSVP: lu.ma/mlflow423
#opensource #mlflow #oss
15.04.2025 19:51 — 👍 4 🔁 2 💬 0 📌 0
This was built by a long-time DSPy community member!
04.03.2025 00:34 — 👍 4 🔁 0 💬 2 📌 0
Yes there's an evals crisis, but evaluating *models* is not even the right question most of the time
LangProBe from Shangyin Tan, @lakshyaaagrawal.bsky.social, Arnav Singhvi, Liheng Lai, @michaelryan207.bsky.social et al begins to ask what complete *AI systems* we should build & under what settings
03.03.2025 19:42 — 👍 10 🔁 2 💬 0 📌 0
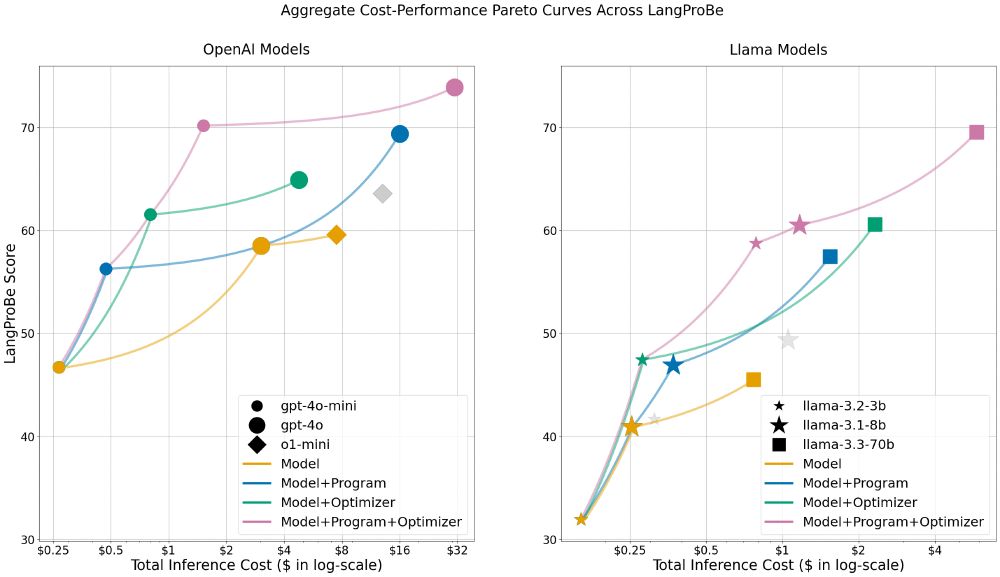
🧵Introducing LangProBe: the first benchmark testing where and how composing LLMs into language programs affects cost-quality tradeoffs!
We find that, on avg across diverse tasks, smaller models within optimized programs beat calls to larger models at a fraction of the cost.
03.03.2025 18:58 — 👍 6 🔁 3 💬 1 📌 2
It doesn't help that the we in ML often only design abstractions leak all kinds of implementation details. Folks often define ML itself in terms of techniques, not problems!
But it's prematurely abstracting that leads to the bitterness of wasted effort, and not "modularity doesn't work for AI". 2/2
26.02.2025 21:59 — 👍 4 🔁 1 💬 0 📌 0
Composition & abstraction are the foundations of CS, but are clearly absent in modern ML.
It's not that they're not crucial for intelligent software. But it takes building many half-working systems to abstract successfully, and it takes good abstractions to have primitives worth composing.
🧵1/2
26.02.2025 21:59 — 👍 8 🔁 1 💬 1 📌 0
4) By default, IR methods that use "multiple vectors" (e.g., cross-encoders) are unscalable. It seems like a necessary tradeoff, but the fascinating thing in late interaction is that it's easy to implement in asymptotically sub-linear ways, thanks to pruning.
Hope this was useful!
26.02.2025 19:14 — 👍 1 🔁 0 💬 1 📌 0
3) "Multi-vector" makes it sound like these approaches win because they store "more stuff".
But that's not true: if you look at how aggressive ColBERTv2 representations are compressed, it's often ~20 bytes per vector (like 5 floats), which can be smaller than popular uncompressed single vectors!
26.02.2025 19:14 — 👍 2 🔁 0 💬 1 📌 0
For dot products, every time you "fix" one query--document pair, you likely break so many other pairs by moving the query and/or document representations.
For ColBERT, you typically *fix* more than you break because you're moving *tokens* in a much smaller (and far more composable!) space.
26.02.2025 19:14 — 👍 1 🔁 0 💬 1 📌 0
The problem isn't the vector representation, it's the **learnability of the scoring function**.
A dot product is just very hard to learn. An intuition I learned from Menon et al (2021) is that:
26.02.2025 19:14 — 👍 1 🔁 1 💬 1 📌 0
2) More importantly, there's nothing to say you can't store a TON of information in a single vector. And it's easy to use multiple vectors and gain *zero* improvement over a single-vector, e.g. if you replace MaxSim with AvgSim in ColBERT, without any other changes, it doesn't work!
26.02.2025 19:14 — 👍 1 🔁 0 💬 1 📌 0
1) If you take ColBERT and force it to use only a constant number of vectors (e.g., 16), it'll barely outperform one vector in the general case.
It's not that you need token-level alignment per se (you don't either!) but you want fine-grained representations, not just *multiple* representations.
26.02.2025 19:14 — 👍 1 🔁 0 💬 1 📌 0
Some quick thoughts: On why we gave the ColBERT paradigm the name "late interaction" instead of "multi-vector", a term that emerged later and that has proven to be more intuitive.
**The mechanism is actually not about having multiple vectors at all.** You can see this in four different ways.
🧵1/7
26.02.2025 19:14 — 👍 7 🔁 0 💬 1 📌 0
Btw the full general form to export all message templates is:
```
{name: my_adapter.format(p.signature, demos=p.demos, inputs={k: f'{{{k}}}' for k in p.signature.input_fields}) for name, p in your_program.named_predictors()}
```
20.02.2025 03:42 — 👍 1 🔁 0 💬 0 📌 0
The default Adapter is dspy.ChatAdapter().
But you can do all customization you mentioned with a custom Adapter:
class MyAdapter(dspy.Adapter):
def format(self, signature, demos, inputs):
return {"role": "user", "content": ...}
def parse(self, signature, completion):
return {....}
20.02.2025 03:37 — 👍 1 🔁 0 💬 1 📌 0
AI scientist, roboticist, farmer, and political economist. Governments structure markets. IP is theft.
https://advanced-eschatonics.com
Co-founder and CEO, Mistral AI
Zeta Alpha: A smarter way to discover and organize knowledge in AI and beyond. R&D in Neural Search. Papers and Trends in AI. Enjoy Discovery!
#NLP / #NLProc , #dataScience, #AI / #ArtificialIntelligence, #linguistics (#syntax, #semantics, …), occasional #parenting, #gardening, & what not. PhD. Adjunct prof once in a full red moon. Industry / technical mentor. Not my opinion, never my employer’s
PhD at EPFL 🧠💻
Ex @MetaAI, @SonyAI, @Microsoft
Egyptian 🇪🇬
Señor swesearcher @ Google DeepMind, adjunct prof at Université de Montréal and Mila. Musician. From 🇪🇨 living in 🇨🇦.
https://psc-g.github.io/
PhD @ucberkeleyofficial.bsky.social | Past: AI4Code Research Fellow @msftresearch.bsky.social | Summer @EPFL Scholar, CS and Applied Maths @IIITDelhi | Hobbyist Saxophonist
https://lakshyaaagrawal.github.io
Maintainer of https://aka.ms/multilspy
Senior Scientist (Computing) at Lawrence Berkeley Lab, Adjunct Faculty (EECS) at UC Berkeley. https://people.eecs.berkeley.edu/~aydin/
PhD @ MIT working on Semantic Data Systems
Mathematized philosophy of literature
peligrietzer.github.io
IR/NLP Applied Researcher. PhD from @UWaterloo.
researcher @DBRXMosaicAI - i develop synthetic data and RL methods to test and improve agents. Ex @MSFTResearch and @LivermoreLab. Ph.D. @PurdueECE
Follow for posts about GitHub repos, DSPy, and agents
Independent AI researcher, creator of datasette.io and llm.datasette.io, building open source tools for data journalism, writing about a lot of stuff at https://simonwillison.net/
Jhanas and AI
Founder @ Zenbase AI (YC S24)
Core @ StanfordnNLP/DSPy
Past NousResearch, UWaterloo SYDE
Senior Lecturer #USydCompSci at the University of Sydney. Postdocs IBM Research and Stanford; PhD at Columbia. Converts ☕ into puns: sometimes theorems. He/him.
Teaching Faculty @ Princeton University | CMU, MIT alum | reinforcement learning, AI ethics, equity and justice, baking | ADHD 💖💜💙
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.























