🚀 I’m excited to announce the launch of our new research chair DevAI&Speech (2025–2029), funded by the Grenoble AI Institute MIAI Cluster IA!
The project explores how human developmental processes can inspire more grounded and socially aware conversational AI (1/6).
02.07.2025 11:39 — 👍 8 🔁 5 💬 1 📌 0
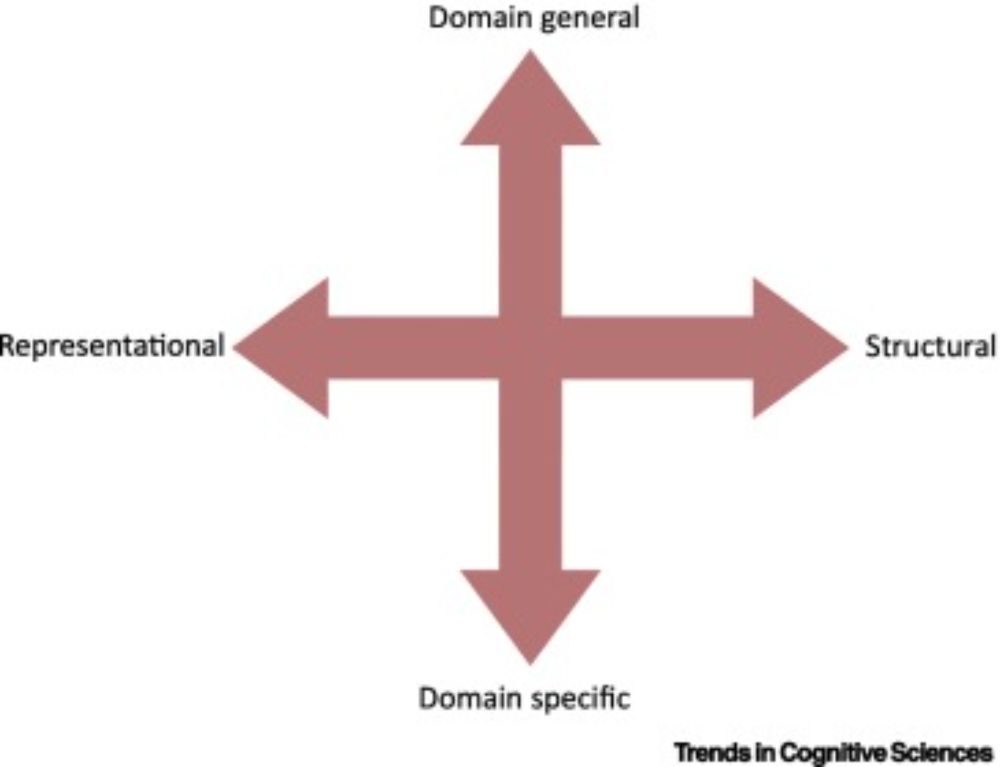
Constructing language: a framework for explaining acquisition
Explaining how children build a language system is a central goal of research in language
acquisition, with broad implications for language evolution, adult language processing,
and artificial intelli...
Children are incredible language learning machines. But how do they do it? Our latest paper, just published in TICS, synthesizes decades of evidence to propose four components that must be built into any theory of how children learn language. 1/
www.cell.com/trends/cogni... @mpi-nl.bsky.social
27.06.2025 05:19 — 👍 152 🔁 58 💬 8 📌 12

Next we jump from analyzing text models to predictive speech models! Phoneticists have claimed for decades that humans rely more on contextual cues when processing vowels compared to consonants. Turns out so do speech models!
12.06.2025 18:56 — 👍 6 🔁 2 💬 1 📌 0

Text: ICIS Webinars - Thursday, June 19 2025 - Beyond Who’s Speaking When: Machine Learning Tools to Extract Rich Multi-Dimensional Features from Home Audio Recordings
Don't miss our next ICIS webinar! June 19 2025.
Join leading researchers for a deep dive into cutting-edge work in infancy research.
infantstudies.org/icis-online-...
#InfantResearch #InfantStudies
03.06.2025 15:41 — 👍 7 🔁 2 💬 0 📌 1
A great opportunity to learn how speech technology can advance research on how children learn language (and vice versa)
You know, beyond surveillance and chatbots 🙊
27.05.2025 16:27 — 👍 1 🔁 0 💬 0 📌 0
👀
26.05.2025 14:42 — 👍 1 🔁 0 💬 0 📌 0


Interested in collecting and processing naturalistic audio data using new AI tools?
If so, join us for our free, two-day workshop; 'Long Form Audio Recordings: A to Z', generously supported by Cardiff University Doctoral Academy.
23.05.2025 08:34 — 👍 4 🔁 1 💬 1 📌 1
@mpoli.fr check this out if you haven't read it yet! Really cool work!
22.05.2025 21:21 — 👍 2 🔁 0 💬 0 📌 0

A schematic of our method. On the left are shown Bayesian inference (visualized using Bayes’ rule and a portrait of the Reverend Bayes) and neural networks (visualized as a weight matrix). Then, an arrow labeled “meta-learning” combines Bayesian inference and neural networks into a “prior-trained neural network”, described as a neural network that has the priors of a Bayesian model – visualized as the same portrait of Reverend Bayes but made out of numbers. Finally, an arrow labeled “learning” goes from the prior-trained neural network to two examples of what it can learn: formal languages (visualized with a finite-state automaton) and aspects of English syntax (visualized with a parse tree for the sentence “colorless green ideas sleep furiously”).
🤖🧠 Paper out in Nature Communications! 🧠🤖
Bayesian models can learn rapidly. Neural networks can handle messy, naturalistic data. How can we combine these strengths?
Our answer: Use meta-learning to distill Bayesian priors into a neural network!
www.nature.com/articles/s41...
1/n
20.05.2025 19:04 — 👍 154 🔁 43 💬 4 📌 1

title of paper (in text) plus author list
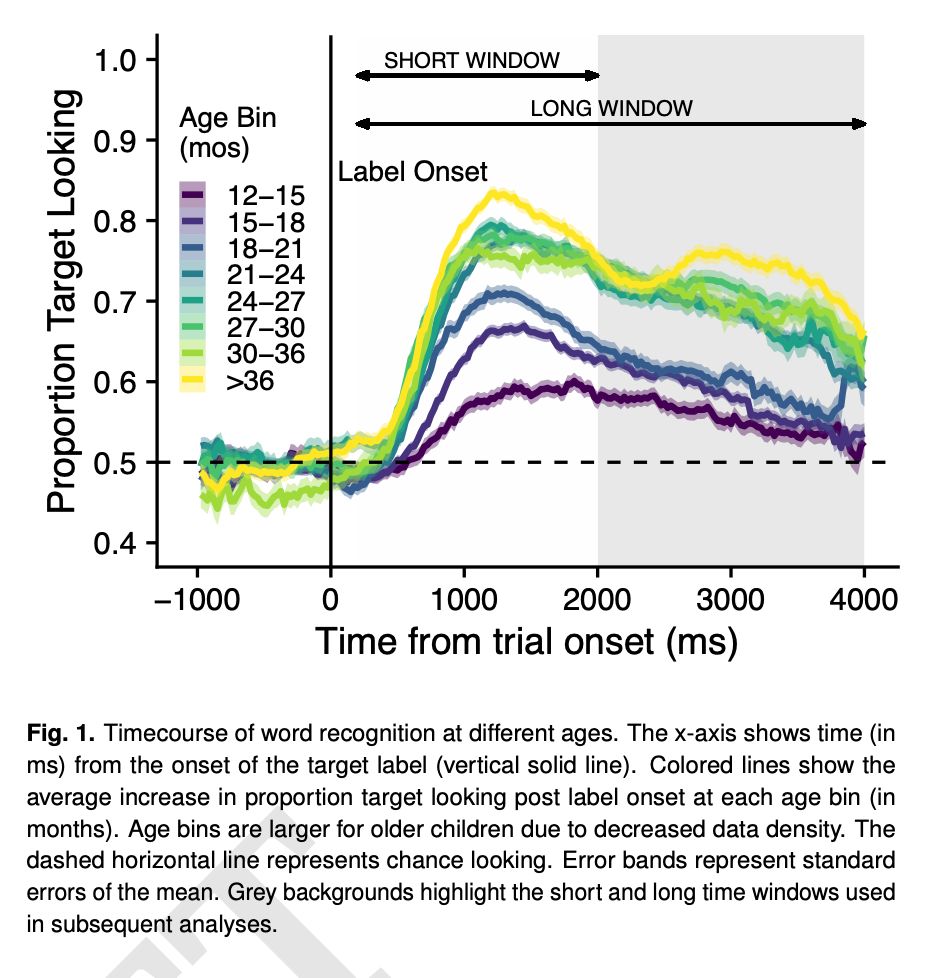
Time course of word recognition for kids at different ages.
Super excited to submit a big sabbatical project this year: "Continuous developmental changes in word
recognition support language learning across early
childhood": osf.io/preprints/ps...
14.04.2025 21:58 — 👍 68 🔁 27 💬 1 📌 1
Tagging the ACLEW people I found on bluesky, and the researchers I know are working with LENA or ACLEW who might be interested
@acristia.bsky.social @mcxfrank.bsky.social @carorowland.bsky.social @bergelsonlab.bsky.social @profsamwass.bsky.social @hbredin.bsky.social @celiarosemberg.bsky.social
07.04.2025 20:56 — 👍 2 🔁 0 💬 0 📌 1
Truly amazing collab. with:
Lisa Hamrick
Bridgette Kelleher @drbkelleher.bsky.social
Amanda Seidl
12/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
🔬 2) For researchers studying language development across neurodevelopmental conditions: these tools seem to perform reliably across diverse populations.
Cross-population differences found by the algorithms likely reflect real differences, not artifacts of the algo.
11/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
⁉️ What does all of this mean?
1) We now understand better each algorithm's strengths and weaknesses.
LENA excels at precise speaker classification with fewer false alarms (good for acoustic analyses), while ACLEW better captures the full range of language interactions.
10/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0

🧩 Performance variations were driven more by participants' speech patterns than by diagnostic groups, with the amount of other children's vocalizations, female and male adult speech predicting the performance of both algorithms.
9/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0

⚖️ Despite being trained exclusively on typically-developing children, both algorithms maintained consistent performance across all diagnostic groups (low-risk, Angelman, fragile X, Down, siblings of children with ASD)!
8/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0

⚖️ What about automatic counts: CTC, AWC, CVC?
Both algorithms capture a large portion of variance in human counts (Pearson's r from .78 to .92)
ACLEW seems better on CTC (.92 vs .83)
LENA is slightly better on AWC (.82 vs .78)
ACLEW is slightly better on CVC (.88 vs .83)
7/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
⚖️ ACLEW, by comparison, correctly classified 69 hours out of those same 100 hours, missing only about 15 hours, confused the speaker category for 15 hours, but generated 99 hours of false alarms.
ACLEW makes a lot of mistakes but retrieved most of the speech.
6/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0

⚖️ We found very different segmentation strategies.
For every 100 hours of speech, LENA correctly classified 45 hours, missed 41 hours, generated 27 hours of false alarms, and confused the speaker category for 14 hours.
LENA makes few mistakes but misses a lot of speech.
5/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
📝 In this study, we annotated 25 hours of audio from 50 children across various neurodevelopmental profiles.
We ask two questions:
1) How do LENA and ACLEW compare across their key performance metrics?
2) Do these algorithms have lower performance for certain populations?
4/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0

🤖 Both algorithms start by segmenting the audio into speaker categories: key child, other children, male and female adult. From this segmentation step, they extract key metrics: Conversational Turn Count (CTC), Adult Word Count (AWC), and Child Vocalization Count (CVC).
3/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
🎙️Wearables are revolutionizing early language research! These devices + AI/speech tech help analyze vast amounts of audio from children's daily lives. Two main algorithms are used to analyze child-centered daylong recordings: the proprietary LENA and open-source ACLEW.
2/12
07.04.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
OSF
Glad to share this new study comparing the performance and biases of the LENA and ACLEW algorithms in analyzing language environments in Down, Fragile X, Angelman syndromes, and populations at elevated likelihood for autism 👶📄
osf.io/preprints/ps...
🧵1/12
07.04.2025 20:56 — 👍 7 🔁 4 💬 1 📌 1
Associate Professor of Psychology at the University of Warwick (@warwickpsych.bsky.social). Interested in #gesture, #language, #learning #evolution, #communication, #development, #Rstats, & #openscience.
Personal Webpage: https://suzanneaussems.github.io/
Machine Learning & Developmental Psychology @ Leuphana University
asst prof @Stanford linguistics | director of social interaction lab 🌱 | bluskies about computational cognitive science & language
Explorer pour faire société - Transformer les défis contemporains en opportunités de progrès. Université citoyenne et responsable, nous explorons, nous inventons, nous partageons pour bâtir une société plus juste et durable.
https://www.univ-amu.fr
Organisme public 🇫🇷 de recherche pluridisciplinaire, le Centre national de la recherche scientifique c'est 33 000 personnes qui font avancer la connaissance. #HelloESR
European Research Council, set up by the EU, funds top researchers of any nationality, helping them pursue great ideas at the frontiers of knowledge. #HorizonEU
Exploring how new words convey novel meanings in ERC Consolidator project #BraveNewWord🧠Unveiling language and cognition insights🔍Join our research journey!
https://bravenewword.unimib.it/
Principal Scientist at Naver Labs Europe && Professor at University Grenoble Alpes
#NLP #AI #LLMs
Philosopher of Artificial Intelligence & Cognitive Science
https://raphaelmilliere.com/
AI @ OpenAI, Tesla, Stanford
Cognitive scientist, philosopher, and psychologist at Berkeley, author of The Scientist in the Crib, The Philosophical Baby and The Gardener and the Carpenter and grandmother of six.
Ph.D. student @kinderstudien.bsky.social
musical interactions in infancy ♫👶🧠🫀
she/her
ManyLanguages is a globally distributed network of language science laboratories that coordinates data collection for democratically selected studies.
http://many-languages.com
account managed by @congzhang.bsky.social and @timoroettger.bsky.social
Platinum open access journal == No fees for readers or authors. https://ldr.lps.library.cmu.edu
Postdoc at Meta FAIR, Comp Neuro PhD @McGill / Mila. Looking at the representation in brains and machines 🔬 https://dongyanl1n.github.io/
Collective cognition. Postdoctoral fellow @ University of Missouri. Previously: University of Wuppertal, ENS Paris and ENS Paris-Saclay. Former publication director / data journalist @ Le Média.
https://lucasgautheron.github.io.
Researcher trying to shape AI towards positive outcomes. ML & Ethics +birds. Generally trying to do the right thing. TIME 100 | TED speaker | Senate testimony provider | Navigating public life as a recluse.
Former: Google, Microsoft; Current: Hugging Face
Developmental Psycholinguist | Wiss. Mitarbeiterin @tuBraunschweig | Studying how we acquire language across the lifespan | IASCL Media Coordinator @iasclchildlang.bsky.social | she/her - sie/ihr
CNRS researcher in cognition : neuroscience / psychology / psycholinguistics
Institut Mondor de Recherche Biomédicale, Créteil & Ecole normale supérieure-PSL, Paris
Head of Department of Cognitive Studies, ENS-PSL
Views are my own, not my employer.
Du lundi au jeudi de 16h à 17h sur France Culture
- Nos émissions à la (ré)écoute par ici : https://www.radiofrance.fr/franceculture/podcasts/la-science-cqfd
- La science sur BlueSky en un seul clic : https://go.bsky.app/CFvzzJP





















