For those who couldn't attend, the recording of Hsieh Cheng-Yu's seminar is now available on our YouTube channel.
Watch the full presentation here: youtu.be/v7DHox_6duE

@ercbravenewword.bsky.social
Exploring how new words convey novel meanings in ERC Consolidator project #BraveNewWord🧠Unveiling language and cognition insights🔍Join our research journey! https://bravenewword.unimib.it/
For those who couldn't attend, the recording of Hsieh Cheng-Yu's seminar is now available on our YouTube channel.
Watch the full presentation here: youtu.be/v7DHox_6duE

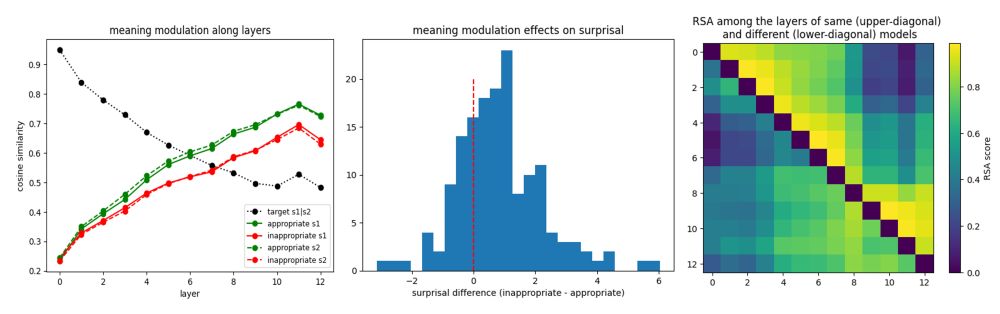
How does the brain handle semantic composition?
Our new Cerebral Cortex paper shows the left inferior frontal gyrus (BA45) does it automatically, even when task-irrelevant. We used fMRI + computational models.
Congrats Marco Ciapparelli, Marco Marelli & team!
doi.org/10.1093/cerc...

🚨 New publication: How to improve conceptual clarity in psychological science?
Thrilled to see this article with @ruimata.bsky.social out. We discuss how LLMs can be leveraged to map, clarify, and generate psychological measures and constructs.
Open access article: doi.org/10.1177/0963...

A fascinating read in @theguardian.com on the psycholinguistics of swearing!
Did you know Germans averaged 53 taboo words, while Brits e Spaniards listed only 16?
Great to see the work of our colleague Simone Sulpizio & Jon Andoni Duñabeitia highlighted! 👏
www.theguardian.com/science/2025...

Join us for our next seminar! We're excited to host Hsieh Cheng-Yu (University of London)
He'll discuss "Making sense from the parts: What Chinese compounds tell us about reading," exploring how we process ambiguity & meaning consistency
🗓️ 27th Oct ⏰ 2PM (CET)📍UniMiB 💻 meet.google.com/zvk-owhv-tfw
I'm sharing a Colab notebook on using large language models for cognitive science! GitHub repo: github.com/MarcoCiappar...
It's geared toward psychologists & linguists and covers extracting embeddings, predictability measures, comparing models across languages & modalities (vision). see examples 🧵

Sigmoid function. Non-linearities in neural network allow it to behave in distributed and near-symbolic fashions.
New paper! 🚨 I argue that LLMs represent a synthesis between distributed and symbolic approaches to language, because, when exposed to language, they develop highly symbolic representations and processing mechanisms in addition to distributed ones.
arxiv.org/abs/2502.11856

Important fMRI/RSA study by @marcociapparelli.bsky.social et al. Compositional (multiplicative) representations of compounds/phrases in left IFG (BA45), mSTS, ATL; left AG encodes constituents, not their composition, weighing the right element more, vice versa IFG 🧠🧩
academic.oup.com/cercor/artic...




Great week at #ESLP2025 in Aix-en-Provence! Huge congrats to our colleagues for their excellent talks on computational models, sound symbolism, and multimodal cognition. Proud of the team and the stimulating discussions!
25.09.2025 10:28 — 👍 5 🔁 2 💬 0 📌 0
📣The chapter "𝗦𝗽𝗲𝗰𝗶𝗳𝗶𝗰𝗶𝘁𝘆: 𝗠𝗲𝘁𝗿𝗶𝗰 𝗮𝗻𝗱 𝗡𝗼𝗿𝗺𝘀"
w/@mariannabolog.bsky.social is now online & forthcoming in the #ElsevierEncyclopedia of Language & Linguistics
🔍 Theoretical overview, quantification tools, and behavioral evidence on specificity.
👉 Read: urly.it/31c4nm
@abstractionerc.bsky.social
The dataset includes over 240K fixations and 150K word-level metrics, with saccade, fixation, and (word) interest area reports. Preprint osf.io/preprints/os..., data osf.io/hx2sj/. Work conducted with @davidecrepaldi.bsky.social and Maria Ktori. (2/2)
22.08.2025 18:49 — 👍 1 🔁 1 💬 0 📌 0
How can we reduce conceptual clutter in the psychological sciences?
@ruimata.bsky.social and I propose a solution based on a fine-tuned 🤖 LLM (bit.ly/mpnet-pers) and test it for 🎭 personality psychology.
The paper is finally out in @natrevpsych.bsky.social: go.nature.com/4bEaaja

For those who couldn't attend, the recording of Abhilasha Kumar's seminar on exploring form-meaning interactions in novel word learning and memory search is now available on our YouTube channel!!
Watch the full presentation here:
www.youtube.com/watch?v=VJTs...
Happy to share that our work on semantic composition is out now -- open access -- in Cerebral Cortex!
With Marco Marelli (@ercbravenewword.bsky.social), @wwgraves.bsky.social & @carloreve.bsky.social.
doi.org/10.1093/cerc...

Great presentation by @fabiomarson.bsky.social last Saturday at #AMLAP2025! He shared his latest research using EEG to study how we integrate novel semantic representations, “linguistic chimeras”, from context.
Congratulations on a fascinating talk!

For those who couldn't attend, the recording of Prof. Harald Baayen's seminar on morphological productivity and the Discriminative Lexicon Model is now available on our YouTube channel.
Watch the full presentation here:
www.youtube.com/watch?v=zN7G...

New seminar announcement!
Exploring form-meaning interactions in novel word learning and memory search
Abhilasha Kumar (Assistant Professor, Bowdoin College)
A fantastic opportunity to delve into how we learn new words and retrieve them from memory.
💻 Join remotely: meet.google.com/pay-qcpv-sbf

📢 Upcoming Seminar!
A computational approach to morphological productivity using the Discriminative Lexicon Model
Professor Harald Baayen (University of Tübingen, Germany)
🗓️ September 8, 2025
2:00 PM - 3:30 PM
📍 UniMiB, Room U6-01C, Milan
🔗 Join remotely: meet.google.com/dkj-kzmw-vzt
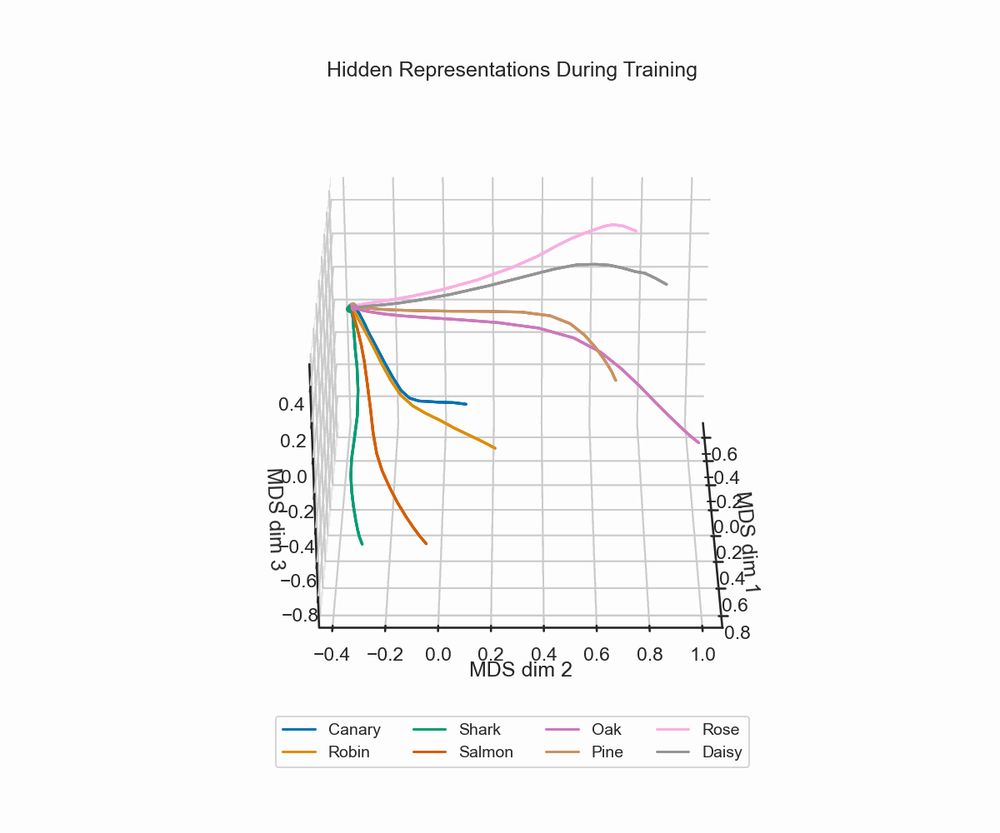
hidden state representation during training
I’d like to share some slides and code for a “Memory Model 101 workshop” I gave recently, which has some minimal examples to illustrate the Rumelhart network & catastrophic interference :)
slides: shorturl.at/q2iKq
code (with colab support!): github.com/qihongl/demo...

🎉We're thrilled to welcome Jing Chen, PhD to our team!
She investigates how meanings are encoded and evolve, combining linguistic and computational approaches.
Her work spans diachronic modeling of lexical change in Mandarin and semantic transparency in LLMs.
🔗 research.polyu.edu.hk/en/publicati...
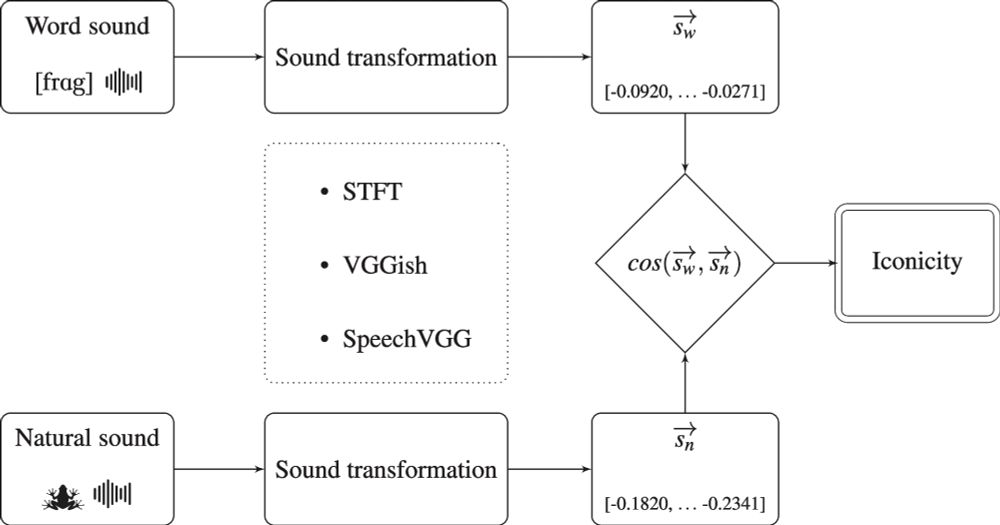
📢 New paper out! We show that auditory iconicity is not marginal in English: word sounds often resemble real-world sounds. Using neural networks and sound similarity measures, we crack the myth of arbitrariness.
Read more: link.springer.com/article/10.3...
@andreadevarda.bsky.social

1/n Happy to share a new paper with Calogero Zarbo & Marco Marelli! How well do LLMs represent the implicit meaning of familiar and novel compounds? How do they compare with simpler distributional semantics models (DSMs; i.e., word embeddings)?
doi.org/10.1111/cogs...

Here's the video of the seminar for those who missed it. Enjoy!
youtu.be/p2YXb6WHCi4

1st post here! Excited to share this work with Marelli & @kathyrastle.bsky.social. We've found readers "routinely" combine constituent meanings for Chinese compound meaning, despite variability in constituent meaning and word structure, even when they're not asked to. See threads👇 for more details:
10.03.2025 15:36 — 👍 7 🔁 4 💬 2 📌 0Link to the seminar: meet.google.com/vwm-hsug-niv
📅 Don’t miss it!

📢 Upcoming Seminar
Words are weird? On the role of lexical ambiguity in language
🗣 Gemma Boleda (Universitat Pompeu Fabra, Spain)
Why is language so ambiguous? Discover how ambiguity balances cognitive simplicity and communicative complexity through large-scale studies.
📍 UniMiB, Room U6-01C, Milan

⚠️ New Study Alert ⚠️
Humans can falsely recognize meaningless pseudowords when they resemble studied words. 🧠✨ This research shows that our brains detect hidden patterns, even without prior knowledge, leading to false memories.
🔗 Read more:
www.researchgate.net/publication/...

📢 Upcoming Seminar
The Power of Words: The contribution of co-occurrence regularities of word use to the development of semantic organization
🗣 Olivera Savic (BCBL)
How do children grasp deeper word connections beyond simple meanings? Discover how word co-occurrence shapes semantic development
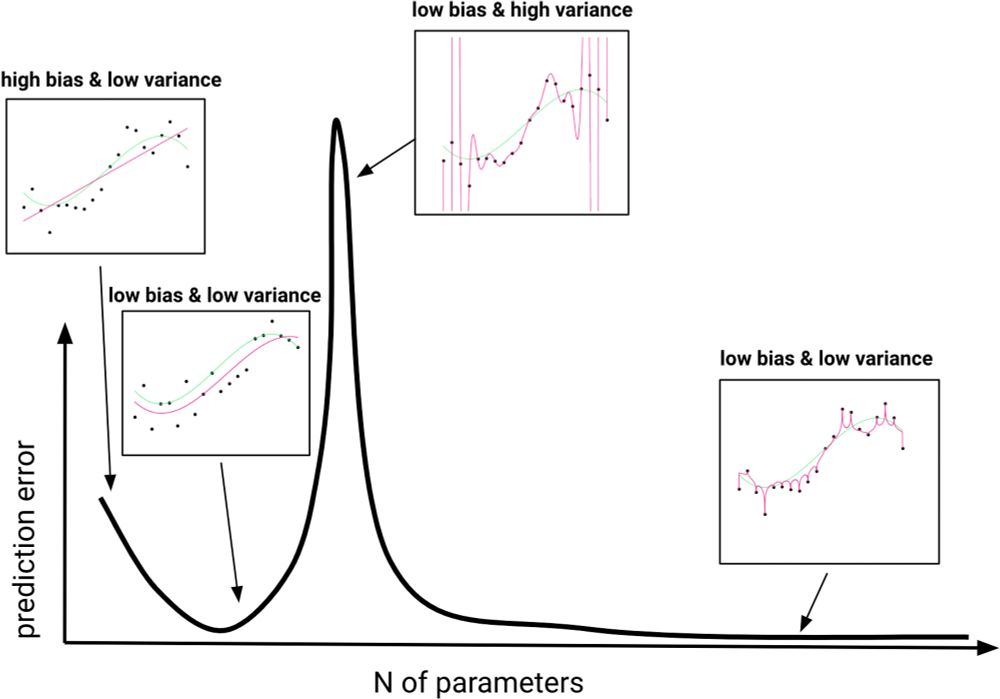
Double descent of prediction error. Degree-one, degree-three, degree-twenty, and degree-one-thousand polynomial regression fits (magenta; from Left to Right) to data generated from a degree-three polynomial function (green). Low prediction error is achieved by both degree-three and degree-one-thousand models.
One of the most-viewed PNAS articles in the last week is “Is Ockham’s razor losing its edge? New perspectives on the principle of model parsimony.” Explore the article here: www.pnas.org/doi/10.1073/...
For more trending articles, visit ow.ly/Me2U50SkLRZ.
Our @RBonandrini was bestowed a "Giovani talenti" award for his studies on word processing.
Congrats Rolando for this achievement! https://x.com/unimib/status/1870046485947265302