Follow me for insights on real-world ML🚀
If this thread helped, drop a like 📷 or repost 📷
21.02.2025 17:31 — 👍 0 🔁 0 💬 0 📌 0
Why use the CPO Pattern?
✅ Scalability – Add new models & components easily.
✅ Maintainability – Elements are decoupled making it easy to change, test and debug individual parts without breaking the entire system.
✅ Reusability – Reuse components across different ML projects.
21.02.2025 17:31 — 👍 1 🔁 0 💬 1 📌 0

3️⃣ Orchestrators 🤖
The orchestrator is responsible for managing the pipeline execution.
This allows us to easily switch components (e.g., swap XGBoost for RandomForest).
21.02.2025 17:31 — 👍 0 🔁 0 💬 1 📌 0

2️⃣ Pipelines 🛤️
A TrainingPipeline ties together components into a single workflow.
Pipelines ensure a clear flow of data, from raw input to final evaluation.
21.02.2025 17:31 — 👍 0 🔁 0 💬 1 📌 0

1️⃣ Components 📦
Each key function (data import, preprocessing, training, evaluation) is wrapped in its own class.
This makes it reusable, testable, and modular.
Example: A DataImporter class to load data!
21.02.2025 17:31 — 👍 1 🔁 0 💬 1 📌 0
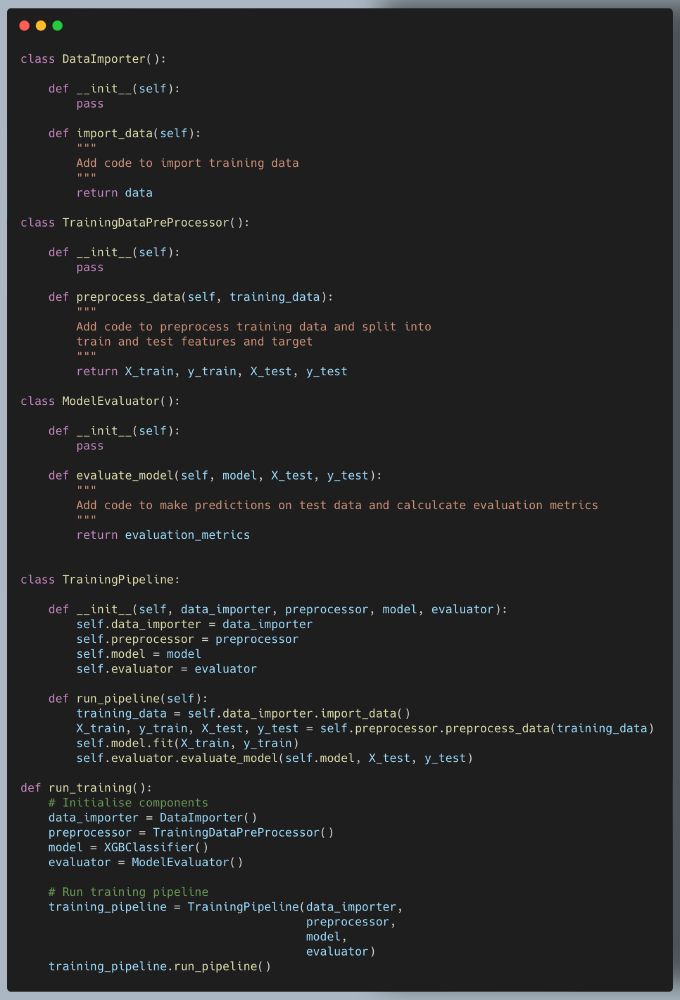
🚀 Want to write production-grade ML code that’s clean, modular & maintainable?
Here’s a simple CPO (components, pipelines, orchestrators) pattern example to structure your code.
Let's break this down with a training pipeline example👇
#MachineLearning #DataScience #MLOps
21.02.2025 17:31 — 👍 0 🔁 0 💬 1 📌 0
DataFramed, Super Data Science, The Data Scientist Show, Ken's Nearest Neighbours
19.02.2025 15:34 — 👍 2 🔁 0 💬 1 📌 0
Follow me for insights on real-world ML🚀
If this thread helped, drop a like 📷 or repost 📷🔁
19.02.2025 15:32 — 👍 0 🔁 0 💬 0 📌 0
EDA isn’t just a formality—it’s the difference between a strong ML model and garbage results. 🚀
✅ Understand your data
✅ Spot issues before modeling
✅ Find strong predictors
These steps serve as a starting point. Analyse further depending on the needs of your project.
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
💡 Why?
👉Detect multicollinearity (too many correlated features = model confusion)
👉Uncover hidden patterns
👉Reduce dimensionality if needed (PCA can help)
📊 Example: If two features are 99% correlated, you probably don’t need both in your model.
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
4️⃣ Multivariate Analysis 🔄 (Relationships Between Features)
Time to go deeper and check how features interact with each other.
🔥 Correlation heatmaps (sns.heatmap(df.corr(), annot=True))
🔥 Pairplots (sns.pairplot(df))
🔥 PCA (if needed) (PCA().fit_transform(df))
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
💡 Why?
👉 Find strong predictors 📈
👉 Identify non-linear relationships (Choose a non-linear model)
👉 Detect leakage (some features might be too correlated with the target!)
📊 Example: A high correlation might mean a strong predictor… or data leakage. Always check!
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
3️⃣ Bivariate Analysis 📊
See how features relate to the target variable
📈 Numerical:
Correlation heatmaps (df.corr())
Scatter plots
📊 Categorical:
Box plots (sns.boxplot(x='category', y='target', data=df))
Grouped means (df.groupby('category')['target'].mean())
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
💡 Why?
👉 Detect skewness (maybe you need log transformations)
👉Spot outliers
👉 Identify imbalanced categories
📊 Example: If a feature is heavily skewed, your linear models might struggle—fix it early!
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
2️⃣ Univariate Analysis 🔍
Let’s get to know each feature individually.
🔍 What to check?
📊 Numerical: Histograms, box plots (df['feature'].hist())
📊 Categorical: Value counts, bar plots (df['feature'].value_counts())
📊 Outliers: Box plots (sns.boxplot(x=df['feature']))
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
💡 Why? This helps spot early issues (wrong dtypes, missing data, duplicates, incorrect values) before they ruin your model.
📊 Example: Checking for missing values can reveal if you need imputation or feature removal.
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
1️⃣ Understanding Data Structure & Metadata 🏗️
Before diving in, know your data.
🔍 What to check?
✅ Dataset shape (df.shape)
✅ Data types (df.dtypes)
✅ Descriptive statistics (df.describe())
✅ Missing values (df.isnull().sum())
✅ Unique values & duplicates
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0

🚀 Many newbies jump straight to feature eng and training ML models... then find models underperform.
Why? They skip Exploratory Data Analysis (EDA).
EDA is an important step for performance and explainability.
Here’s how to start👇
#DataAnalytics #100DaysOfML #MachineLearning
19.02.2025 15:32 — 👍 0 🔁 0 💬 1 📌 0
Should you separate your SQL servers into different resource groups? This depends on your specific use case. if you have a small number of SQL databases and they are tightly integrated with your app then keeping them in the same resource group as your app might be the way to go.
10.02.2025 00:07 — 👍 1 🔁 0 💬 0 📌 0
It's recommended to keep Data Lakes and Blob Storage in a different resource group than your application or project resource group. This limits attack potential security issues and eases resource & cost management.
10.02.2025 00:07 — 👍 0 🔁 0 💬 1 📌 0
It's a good idea to keep data associated with different projects in dedicated Blob storage containers.
10.02.2025 00:06 — 👍 0 🔁 0 💬 1 📌 0
Create dedicated resource groups for each large project or application
10.02.2025 00:06 — 👍 0 🔁 0 💬 1 📌 0
On cloud platforms there are a number of different ways to store your data. Given that it can often be confusing to know what to know how best to organise your data.
Here's a couple of tips for working with blob storage, data lakes and sql servers:
#azure #dataengineering
10.02.2025 00:06 — 👍 1 🔁 0 💬 1 📌 0
Personally, I’m not a fan of building things with certain frameworks or patterns just because company x or developer y does it that way. Prefer to use as ideas to try, see the pros and cons and then use where it makes sense rather than following blindly.
10.02.2025 00:04 — 👍 1 🔁 0 💬 0 📌 0
The more I watch or read about successful people, the more I see that:
- They build things they want to use
- They are smart contrarians
- They don’t assume something will or won’t work, they experiment and adjust.
Also helps if you have rich people in your network😬
31.01.2025 15:00 — 👍 0 🔁 0 💬 0 📌 0
I run Fake Mayo. A newsletter where entrepreneurs share how they got their first customers.
fakemayo.com
💾 Pieter.com est. 1994
📸 PhotoAI.com $120K/m
🏡 InteriorAI.com $38K/m
🛰 RemoteOK.com $37K/m
🌍 Nomads.com $35K/m
🎁 levelsio.com $23K/m
2 decades of exp building business value through code.
Otelic.com - Affordable hosted Logs & Traces for your app. No monthly payments. So easy, junior can use.
#buildinpublic #opentelemetry #logs
I share lessons on AI, SaaS apps and indiehacking. Building https://MicroPoster.so for X & Bluesky | Taranify.com (18k users) | JekyllPad.com (7k users) | DigitalToolpad.com (new)
My Portfolio: https://indiepa.ge/arman
📍 Australia
Bootstrapping http://WallStRank.com with Amrit Rupa
Web developer. Learning iOS dev. Enjoying Toast. I write blogs about CSS animation and other front end dev stuff. Also handstands. He/him.
software. satellites. swimming.
building stuff that lasts.
🦋 skyflow.me - bsky observatory
🔐 pwplz.com - free passwords
🛰️ devarno.com - the lab
supporting & sharing as i #buildinpublic
Solo Entrepreneur, building iOS and web apps
🧑🍳 getjacked.app
🚀 svelteappfast.com
₿ bitcoingauge.app
Shipping 12 products in 25
🟢🟢🟢🟢🟢🟠⚪️⚪️⚪️⚪️⚪️⚪️
I write about what solopreneurship taught me 👇
jogicodes.beehiiv.com
🚧 Independently building SaaS & apps: stronglytyped.uk/work
📥 New: blueskyinbox.com
🙃 Fun: bskyfeels.com
🛠️ Handy(?): playground.bsky.guide
🦀 Aspiring Rustacean
🚴♂️ Cyclist
🤓 Nerd
👶 Dad
Learn 📚 Grow 🚀 Hustle 💼
mangosqueezy.com - AI agent to find and manage affiliates for SaaS businesses 🤖
https://squzy.link/yt - YT 📹
I'm an ML Team Lead with a Master’s in CS, but on 🦋, I’m just a junior solopreneur sharing the journey 🚀.
Download Locator and Save Places you Love 👇🏻
locator.ltd
Sharing boring businesses
👷 Building jupitrr.ai ($4k MRR)
🚀 Passively on http://freehunter.hk ($20k MRR)
✨ A small learning a day keeps autopilot away.
Some side projects -
VoiceRecorder.ai
Torontoeventsweekly.ca
AI Architect | North Carolina | AI/ML, IoT, science
WARNING: I talk about kids sometimes
Futurist, GRC, Compliance, Formula 1, Author of „Business Philosophy according to Enzo Ferrari“ and „Tomorrow’s Business Ethics: Philip K. Dick vs. W. Edwards Deming“
I write Daring Fireball and created Markdown.
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app


















