I hope you've found this post insightful.
Video by @VictorKaiWang1.
Follow me @_mwitiderrick for more thought-provoking posts.
Like/Retweet the first tweet below to share with your friends:
23.06.2025 10:48 — 👍 0 🔁 0 💬 0 📌 0
Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights
Drag-and-Drop LLMs unlock a future without fine-tuning bottlenecks.
No more hours of GPU time per task.
No more gradient descent.
Just drop in prompts and generate weights.
Get the repo: jerryliang24.github.io/DnD.
23.06.2025 10:48 — 👍 0 🔁 0 💬 1 📌 0
DnD uses a hyper-conv decoder, not diffusion.
It works with Qwen2.5 from 0.5B to 7B.
Uses Sentence-BERT to encode prompts, then generates full LoRA layers.
It's open-source and insanely efficient.
Instant LoRA generation is now real.
23.06.2025 10:48 — 👍 0 🔁 0 💬 1 📌 0
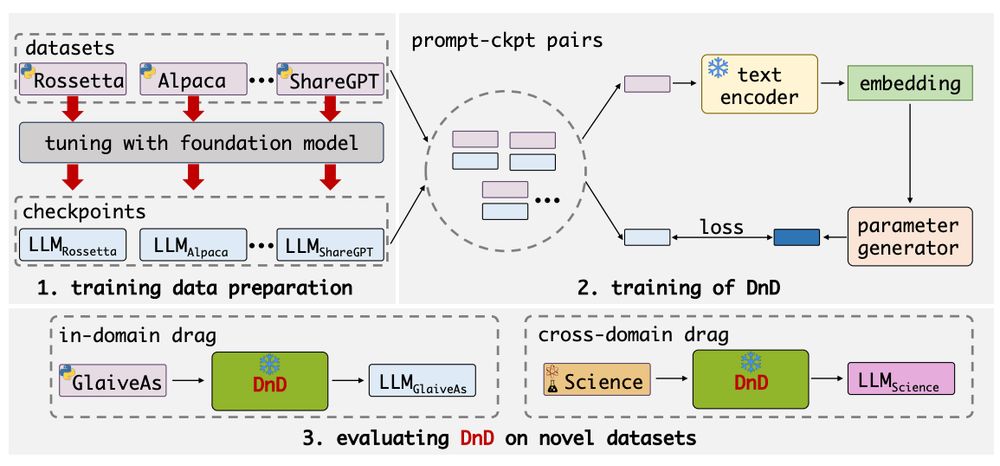
Outperforms LoRA on math, coding, reasoning, even multimodal.
Beats GPT-style baselines without seeing labels.
On HumanEval: pass@1 jumps from 17.6 to 32.7.
On gsm8k: better than fine-tuned models.
DnD generalizes across domains and model sizes.
23.06.2025 10:48 — 👍 0 🔁 0 💬 1 📌 0
DnD lets you customize LLMs in seconds.
Trained on prompt–checkpoint pairs, not full datasets.
It learns how prompts reshape weights, then skips training.
It’s like LoRA, but without the wait.
Zero-shot, zero-tuning, real results.
23.06.2025 10:48 — 👍 0 🔁 0 💬 1 📌 0
DnD lets you customize LLMs in seconds.
Trained on prompt–checkpoint pairs, not full datasets.
It learns how prompts reshape weights, then skips training.
It’s like LoRA, but without the wait.
Zero-shot, zero-tuning, real results.
23.06.2025 10:48 — 👍 0 🔁 0 💬 1 📌 0
Drag-and-Drop LLMs just changed fine-tuning forever.
No training. No gradients. No labels.
Just prompts in, task-specific LoRA weights out.
12,000x faster than LoRA. Up to 30% better.
Here’s everything you need to know.
23.06.2025 10:48 — 👍 0 🔁 0 💬 1 📌 0
Inspired by COIL, fixed for real-world use:
✔ No expansion.
✔ Word-level, not token-level.
✔ Sparse by design.
✔ Generalizes out-of-domain.
And yes, it runs on a CPU in under a minute per word.
16.06.2025 08:58 — 👍 0 🔁 0 💬 1 📌 0
miniCOIL adds a semantic layer to BM25.
Each word gets a 4D vector that captures meaning*
Trained per word using self-supervised triplet loss.
Fast to train. Fast to run.
Fits inside classic inverted indexes.
16.06.2025 08:58 — 👍 0 🔁 0 💬 1 📌 0
BM25 can’t tell a fruit bat from a baseball bat.
Dense retrieval gets the meaning, but loses precision.
Now there’s miniCOIL: a sparse neural retriever that understands context.
It’s lightweight, explainable, and outperforms BM25 in 4 out of 5 domains.
Here’s how it works.
16.06.2025 08:58 — 👍 0 🔁 0 💬 1 📌 0
I hope you've found this post insightful.
Follow me @_mwitiderrick for more thought-provoking posts.
Like/Retweet the first tweet below to share with your friends:
12.06.2025 09:00 — 👍 0 🔁 0 💬 0 📌 0
Read the full article: qdrant.tech/documentati...
12.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
Use Qdrant’s `hnsw_config(m=0)` to skip HNSW for rerank vectors.
Dense vectors = fast first pass.
Multivectors = precise rerank.
Both live in the same Qdrant collection.
One API call handles it all.
12.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
Most retrieval uses one vector per doc.
Multivector search? Hundreds.
Token-level embeddings let you match query phrases exactly.
Perfect for reranking with ColBERT or ColPali.
But don't index everything or you'll regret it.
12.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
Everyone loves multivector search.
But most are doing it wrong.
Too many vectors. Too much RAM. Too slow.
@qdrant_engine + ColBERT can be blazing fast, if you optimize right.
Here’s how to rerank like a pro without blowing up your memory:
12.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
I hope you've found this post insightful.
Follow me @_mwitiderrick for more thought-provoking posts.
Like/Retweet the first tweet below to share with your friends:
11.06.2025 09:00 — 👍 0 🔁 0 💬 0 📌 0
TLDR: Visual RAG works.
But don’t scale it naïvely.
Pooling + rerank = fast, accurate, scalable document search.
This is the cheat code for ColPali at scale.
Start here before your vector DB explodes.
Full guide: qdrant.tech/documentati...
11.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
Qdrant supports multivector formats natively.
Use MAX_SIM with mean-pooled + original vector fields.
Enable HNSW only for pooled vectors.
ColPali’s row-column patch structure makes this easy to implement.
11.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0

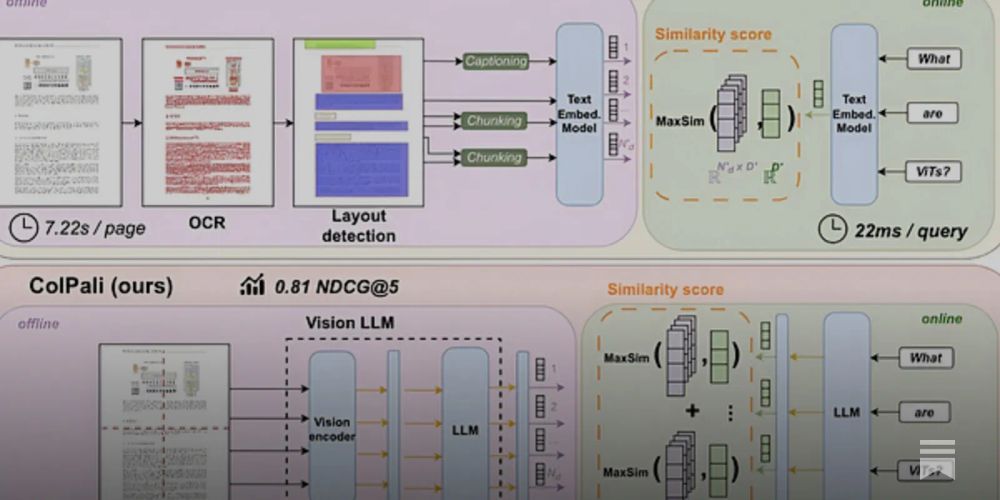
Step 1: Use mean-pooled vectors for first-pass retrieval.
Step 2: Rerank results with full multivectors from ColPali/ColQwen.
Result: 10x faster indexing.
Same retrieval quality.
No hallucinated tables, no dropped layout info.
11.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
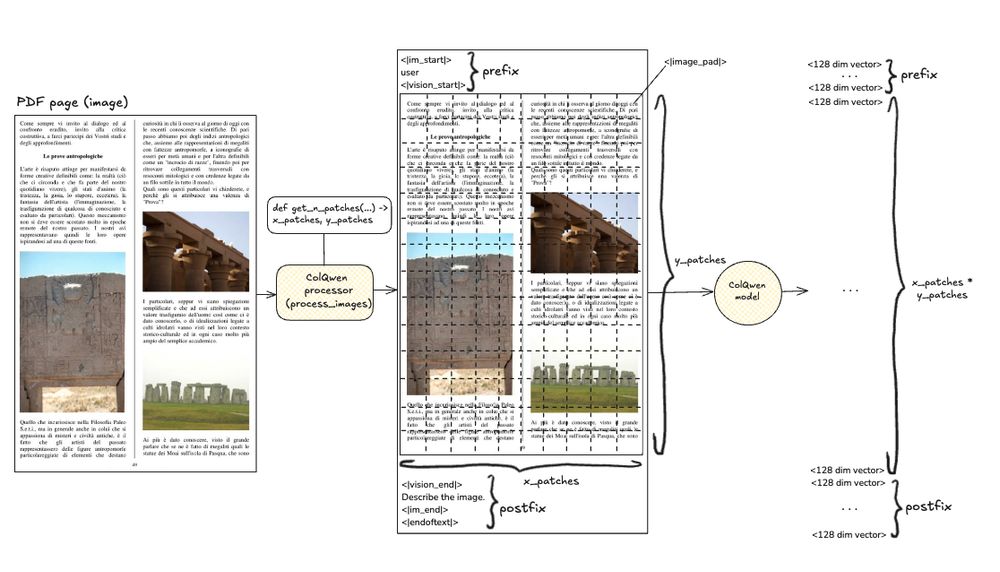
ColPali generates ~1,000 vectors per page.
ColQwen brings it down to ~700.
But that’s still too heavy for HNSW indexing at scale.
The fix: mean pooling.
Compress multivectors by rows/columns before indexing.
11.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
ColPali is cool.
But scaling it to 20,000+ PDF pages? Brutal.
VLLMs like ColPali and ColQwen create thousands of vectors per page.
@qdrant_engine solves this, but only if you optimize smart.
Here’s how to scale visual PDF retrieval without melting your GPU:
11.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
The King of Multi-Modal RAG: ColPali
Query your rich visual PDFs under a RAG web app
I hope you've found this post insightful.
Follow me @_mwitiderrick for more thought-provoking posts.
See the full implementation here: decodingml.substack.com/p/the-king-...
10.06.2025 09:02 — 👍 0 🔁 0 💬 0 📌 0
Why this matters:
ColPali unlocks true page-level understanding.
No more hallucinated rows or broken figures.
Text-only RAG is obsolete.
10.06.2025 09:02 — 👍 0 🔁 0 💬 1 📌 0
The pipeline:
PDF ➝ image ➝ ColQwen 2.5 ➝ vector embeddings ➝ @qdrant_engine.
Then an LLM reads the actual page images to answer questions.
It’s like ChatGPT, but with eyes.
Tables and diagrams are no longer black boxes.
10.06.2025 09:02 — 👍 0 🔁 0 💬 1 📌 0
ColPali skips text extraction.
It feeds document images into a vision-language model.
Every table, chart, and layout element is preserved.
Embeddings capture not just content, but spatial relationships.
Visual memory for documents is finally real.
10.06.2025 09:02 — 👍 0 🔁 0 💬 1 📌 0
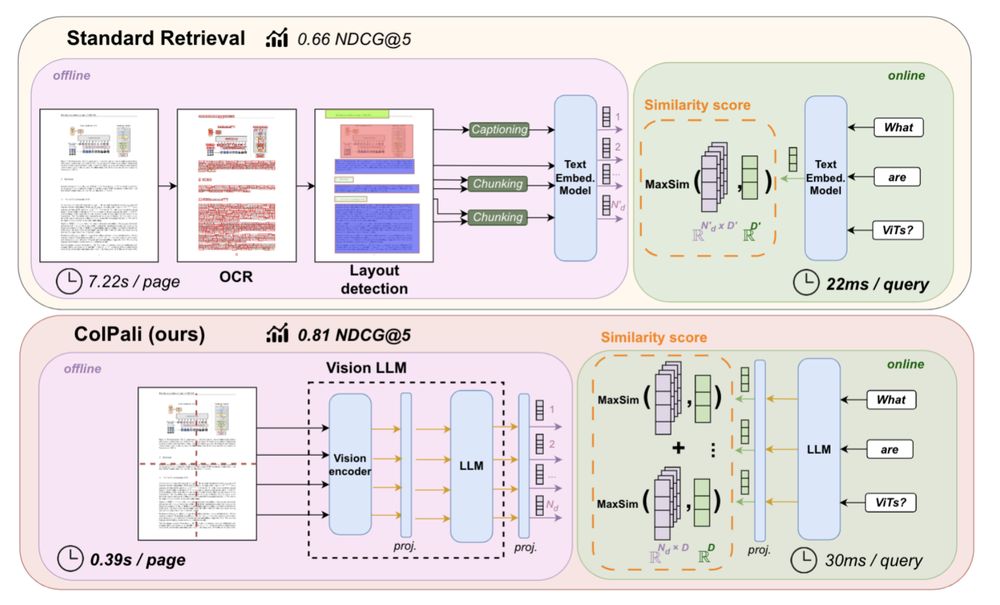
RAG is broken for complex docs.
Tables? Lost.
Layouts? Scrambled.
Now there's ColPali, a breakthrough visual RAG system that sees like a human.
It doesn’t read documents. It looks at them.
Here’s how it changes everything:
10.06.2025 09:02 — 👍 0 🔁 0 💬 1 📌 0
Anthropic’s move is strategic and could reshape AI defense norms.
Their partnership with Palantir and AWS is a game-changer.
This isn't just business.
It's about staying ahead in AI safety.
07.06.2025 09:00 — 👍 0 🔁 0 💬 0 📌 0
This isn’t just about Anthropic – the trend is widespread.
OpenAI, Meta, and Google are also eyeing defense.
The intersection of AI and national security is heating up.
Powerhouses are aligning their models with defense needs.
07.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
Both AI and national security are evolving fast.
Anthropic’s new models focus on security applications.
They've added Fontaine to boost strategic decisions.
His past includes advising Senator McCain.
This move strengthens Anthropic’s governance and safety focus.
07.06.2025 09:00 — 👍 0 🔁 0 💬 1 📌 0
The world's leading publication for data science and artificial intelligence professionals.
Website 🌐 towardsdatascience.com
Submit an Article ✍️ https://contributor.insightmediagroup.io
Subscribe to our Newsletter 📩 https://bit.ly/TDS-Newsletter
TEDx Speaker, Google GDE, AWS Community Builder, Podcaster, Founder Malaysia R User Group, Artificial Intelligence & Machine Learning Malaysia User Group
GDE in AI and Google Cloud | Google Cloud Champion Innovator |Alumni- GitHub Campus Expert🚩|SIG & WG Member
@TensorFlow__JS |@tfugdurg Organizer
CTO en Quix | Divulgador de Inteligencia Artificial (Youtube) | @GoogleDevExpert en ML & AI | @MVPAward en AI | Cloud Champion Innovator
CEO / AI researcher @ Lablup Inc.
ML Engineer at Zendata, Google Developer Expert in AI/ML and Cloud. Currently working with cybersecurity and privacy.
https://rubenszimbres.phd
Data Scientist - GDE in ML
Mentor, Writer, Mental, Attsion to detail, and CIO and founder in Infinite Red
My Fiction Newsletter: https://forms.gle/zXb39QNiV1seiRfL9
Idealizador e Fundador do app DENGA LOVE
Empreendedor Social tentando usar meu conhecimento pra trazer mais igualdade 🧡
ai @CSatUSC, ml @USC_ICT and @USCCinema, @googledevexpert prev @harman @letsunifyai, gsoc, words @pyimagesearch, old words in @Weights_Biases, @TDataScience
Co-founder https://callchimp.ai, #GoogleDevExpert in ML & Cloud,
@TEDx Speaker, 2x DL books author, Tech Generalist, Kindness is easy - be kind
Mostly building stuff in ML (Writing a dissertation on Operating Systems 🦀)
Github: https://github.com/SauravMaheshkar
10x AI & Open Source Award Winner • @GoogleDevExpert • Author @DataForML • @PyBay Program Chair • @OReillyMedia Reviewer • prev @Meta, @WomenWhoCode Director
Sr. ML Engineer | Keras 3 Collaborator | @GoogleDevExpert in Machine Learning | @TensorFlow addons maintainer l ML is all I do | Views are my own!
Machine Learning Expert and enthusiast. Talk Ethics to me 🙃
I love hot dogs, afternoon naps, wine, and Lego.
Helping 100,000+ solopreneurs build a fulfilling life through lean, profitable, one-person business at justinwelsh.me
Founding list[float] engineer. LLMs 😬. Information retrieval. Infra. Systems. Normcore code. Nutella. Vectors. Words. Vibes. Bad puns (soon).
https://vickiboykis.com/what_are_embeddings/
Building Argilla @ 🤗 HuggingFace
🏗️ Software Architect ~ 🧮 Software Engineer ~ 🥋 Software Craftsman ~ 🎤 Speaker | Making software with passion applying the craftsmanship principles






















