
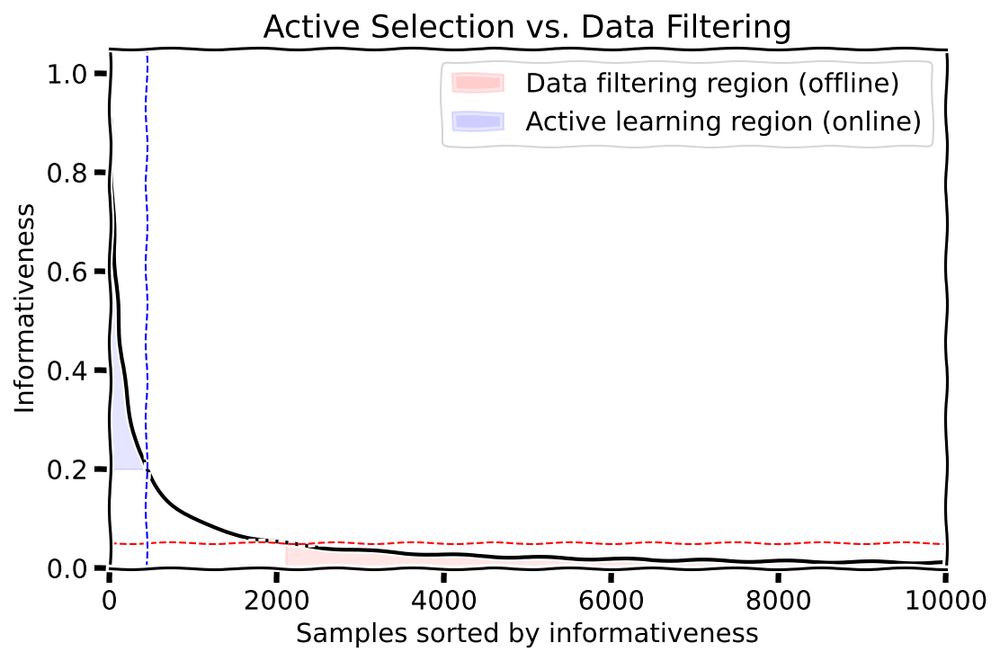
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
I want to share my latest (very short) blog post: "Active Learning vs. Data Filtering: Selection vs. Rejection."
What is the fundamental difference between active learning and data filtering?
Well, obviously, the difference is that:
1/11
This is peak performance whether you believe it or not 😂😂
10.03.2025 14:08 — 👍 1 🔁 0 💬 0 📌 0
Summary:
x.com/A_K_Nain/sta...
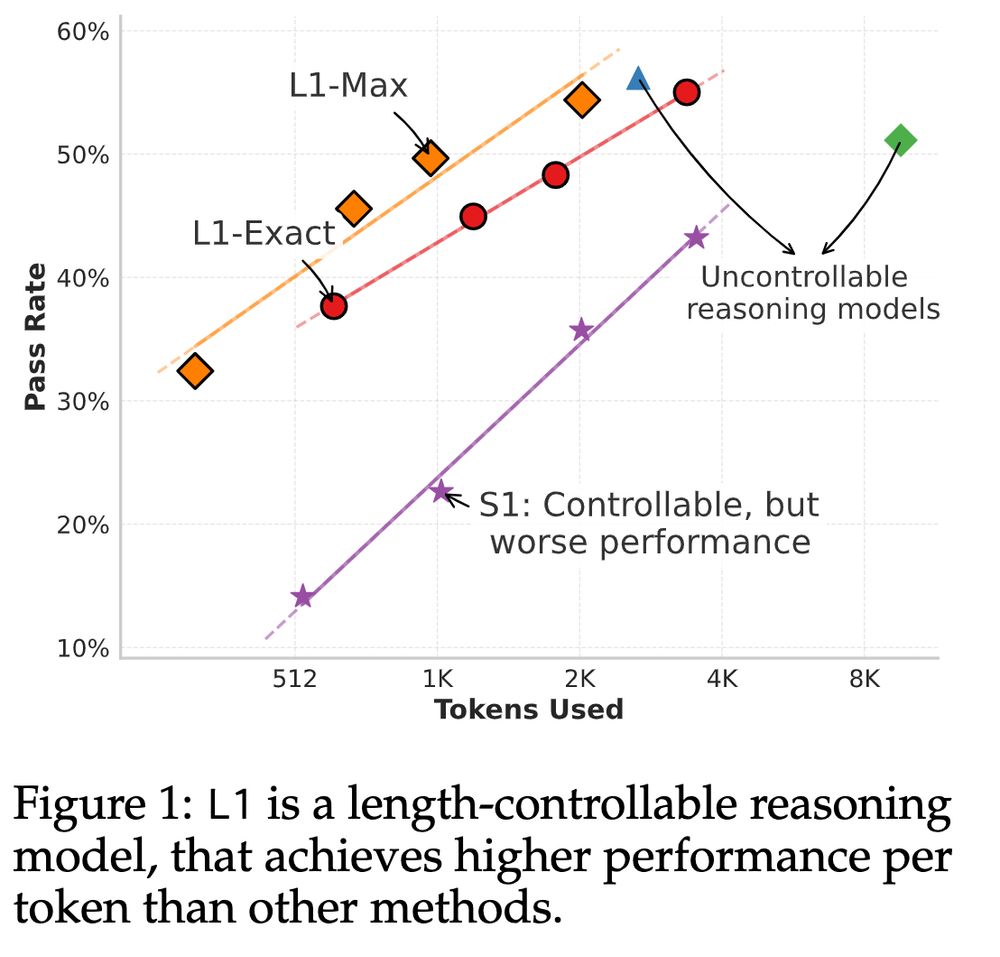
What if you want to control the length of CoT sequences? Can you put a budget constraint at test time for the reasoner models while maintaining performance? This latest paper from CMU addresses these two questions via RL. Here is a summary of LCPO in case you are interested:
10.03.2025 01:50 — 👍 0 🔁 0 💬 1 📌 0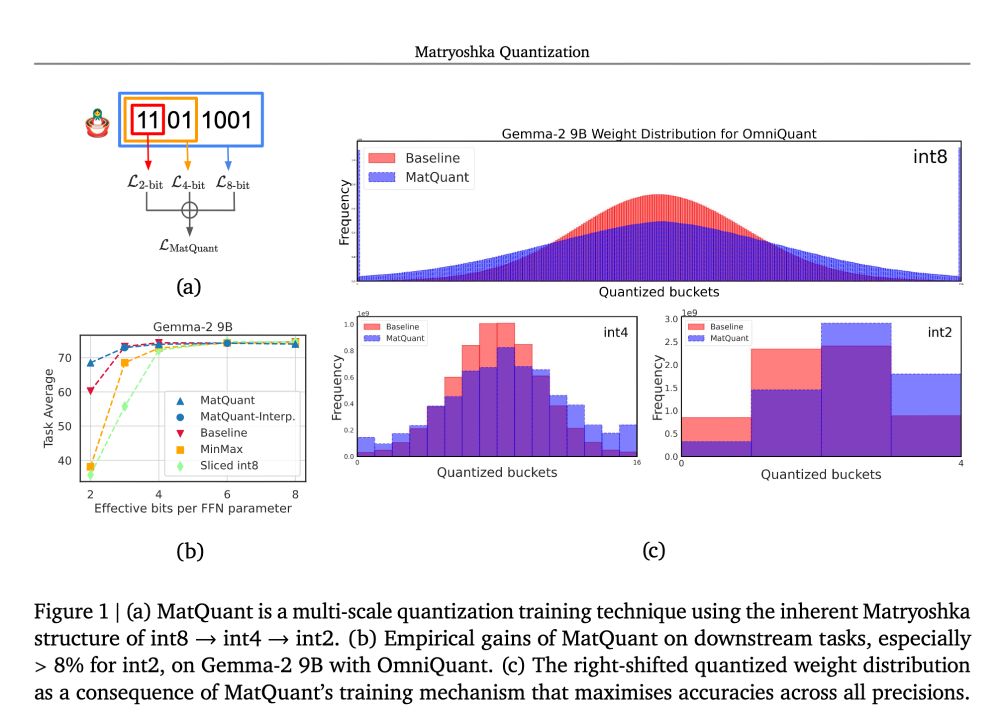
https://x.com/A_K_Nain/status/1890226873332092997
Matryoshka Quantization: Another fantastic paper from GDM! MatQuant came out last week. It was a very refreshing read. Here is a summary in case you are interested:
14.02.2025 02:38 — 👍 1 🔁 0 💬 1 📌 0
2/3
Now, we are starting a new series on Flow Matching with the same objective. To that end, I am happy to announce the first post of the series (link in the thread). Enjoy! 🍻
1/3
Two years ago, we started a series on Diffusion Models that covered everything related to these models in-depth. We decided to write those tutorials covering intuition and the fundamentals because we could not find any high-quality diffusion tutorials then.

JanusPro is here, the next generation of the Janus model, with a few surprises (even for me!). I liked JanusFlow a lot, but the JanusPro 1B is what caught my eye. Here is a summary of the paper in case you are interested:
28.01.2025 02:20 — 👍 3 🔁 0 💬 1 📌 0
I put up all these summaries here as well. Will update by EOD:
aakashkumarnain.github.io/blog.html
Yes, that is doable. Thanks
21.01.2025 07:22 — 👍 0 🔁 0 💬 0 📌 0This site does not allow long content yet 😞
21.01.2025 07:05 — 👍 0 🔁 0 💬 1 📌 0
I read the R1 paper last night, and here is a summary cum highlights from the paper (technical report to be more precise)
21.01.2025 02:22 — 👍 3 🔁 0 💬 1 📌 0Everyone has heard enough about the scaling inference-time compute for LLMs in the past month. Diffusion models, on the other hand, have an innate flexibility for allocating varied compute at inference time. Here is a summary of how researchers at GDM exploit this property: 👇
20.01.2025 03:53 — 👍 2 🔁 0 💬 1 📌 0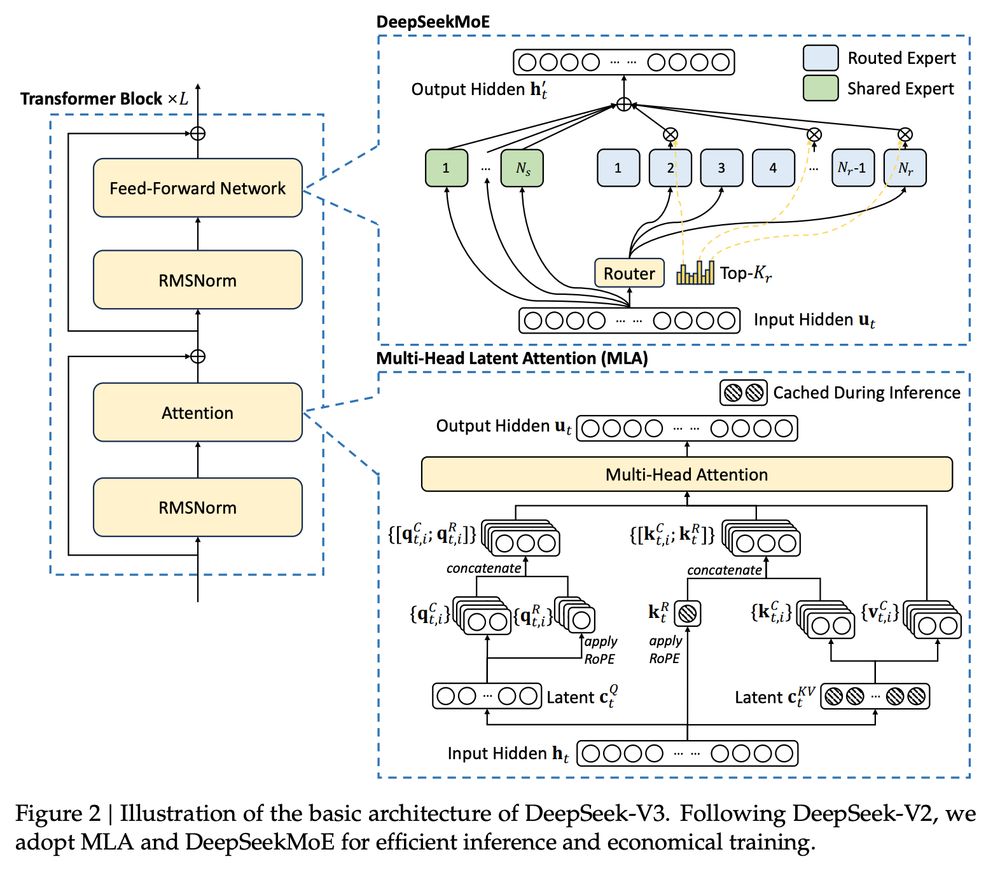
I just finished reading the DeepSeekv3 paper. Here is everything you need to know about it: 👇
x.com/A_K_Nain/sta...

https://x.com/A_K_Nain/status/1870068712709173645
I just finished reading one of the latest papers from Meta Research, MetaMorph. Except for two things (both not good), it is an okay paper, simple, concise, and to the point. Here is a quick summary in case you are interested:
x.com/A_K_Nain/sta...
Super cool. Congrats! 💥
16.12.2024 17:25 — 👍 1 🔁 0 💬 0 📌 0
Proud to see the release of Veo V2! deepmind.google/technologies...
"Veo has achieved state of the art results in head-to-head comparisons of outputs by human raters over top video generation models"
What if I tell you you can train a SOTA Gaze estimation model in 1 hour on an RTX4090 GPU? Too good to be true? I was also skeptical of that claim made in the Gaze-LLE paper, but it is true. DINOv2 FTW! I finished reading the paper, and here is a summary :
x.com/A_K_Nain/sta...
Summary:
x.com/A_K_Nain/sta...
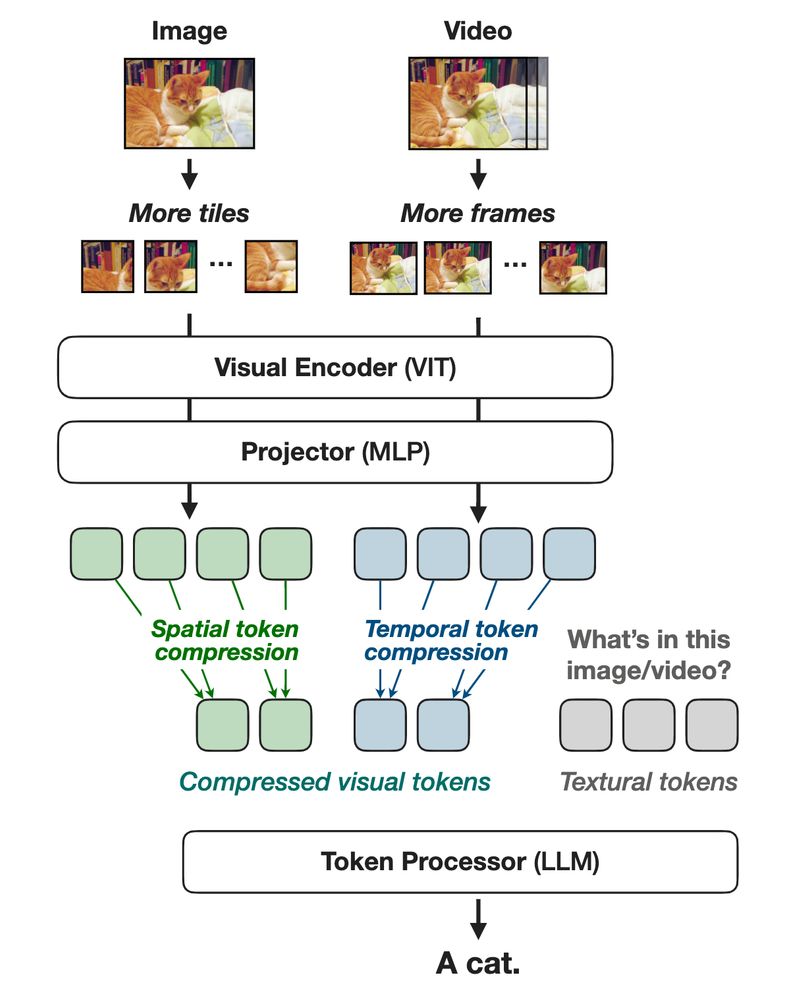
Can you pre-train and fine-tune your VLMs in FP8? Can you get more than 2x efficiency with some simple tricks? Nvidia presents NVILA, an efficient frontier VLM that achieves all of the above. I finished reading the paper, and here is a summary in case you are interested:
13.12.2024 11:50 — 👍 1 🔁 0 💬 1 📌 0
https://aakashkumarnain.github.io/posts/ml_dl_concepts/rope.html
I am back to writing math-heavy yet intuitive blog posts. Almost two years ago, I wrote the diffusion tutorials with a similar intention. This time, I am targeting the fundamental concepts of LLMs and MLLMs. And here is the first post in that direction: Rotary Position Encodings. Enjoy reading! 🍻
11.12.2024 03:04 — 👍 13 🔁 0 💬 2 📌 1
1/2
Google DeepMind announced PaliGemma 2 last week. It is an upgrade of the PaliGemma open Vision-Language Model (VLM) based on the Gemma 2 family of language models. What does this generation of PaliGemma bring to the table? I finished reading the technical report, and here is a summary:
It will be interesting to find out how it will fare with Sonnet. Sonnet has been my go-to model for a while now. The one thing I hate about it is that it is too verbose and chatty. If Gemini 2.0 performs on a similar scale without being verbose, I would happily use it for my tasks.
08.12.2024 17:31 — 👍 0 🔁 0 💬 0 📌 0