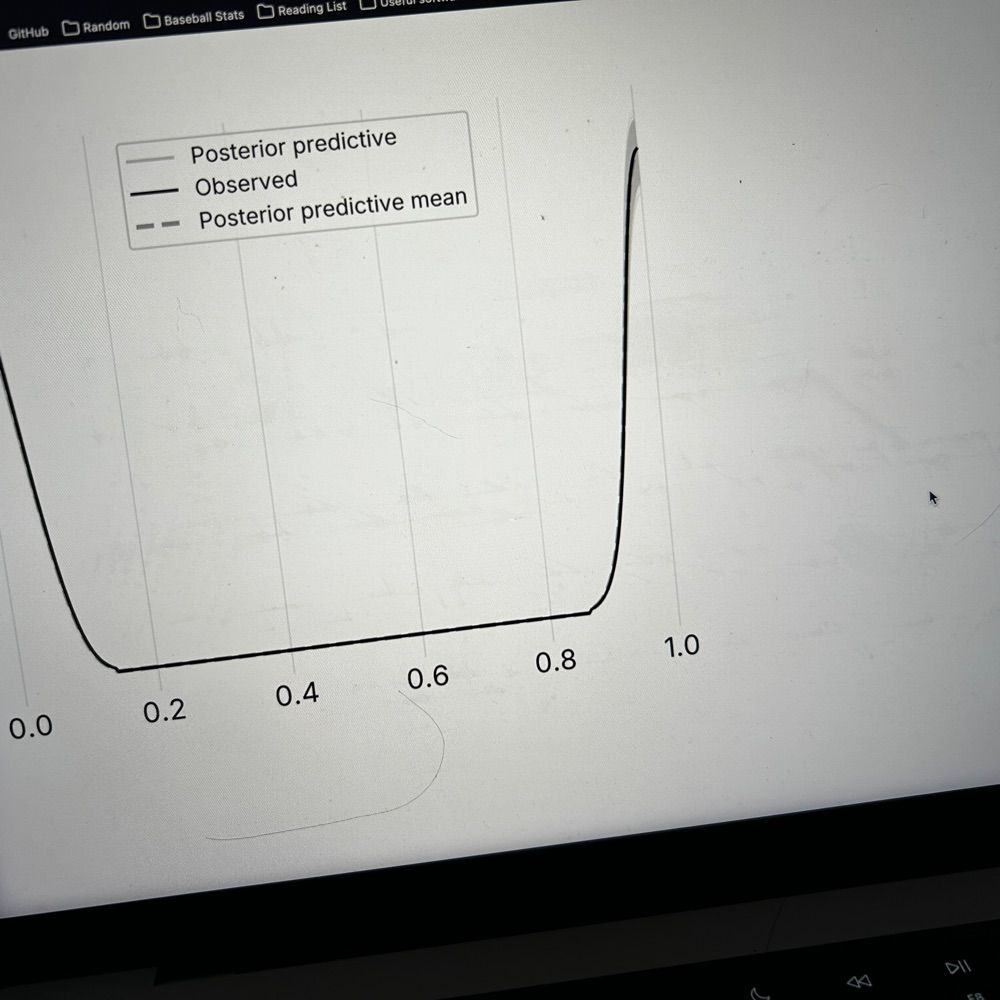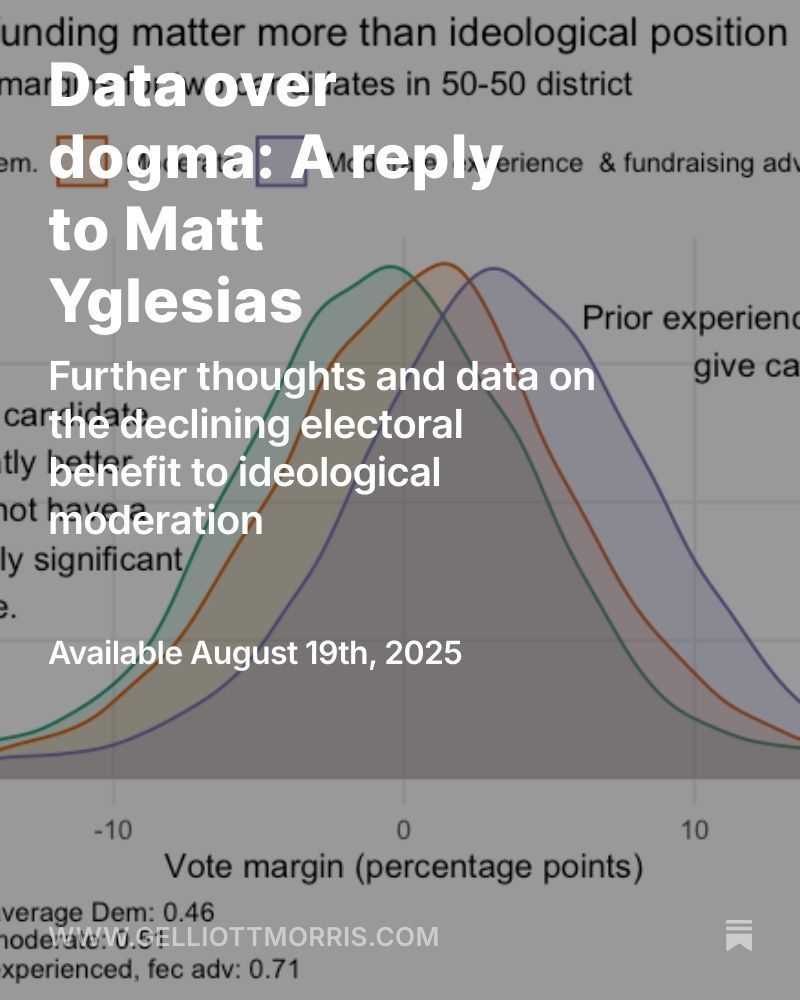
Good morning. Here is my reply to Matt Yglesias' "reply" to my article on moderates. This is a comprehensive accounting of my and other evidence, with some clarifications of findings and my position. I hope you will read and share.
www.gelliottmorris.com/p/data-over-...
19.08.2025 12:05 — 👍 171 🔁 38 💬 11 📌 10
> voice as a primary input method for using your PC
No.
13.08.2025 22:59 — 👍 565 🔁 15 💬 3 📌 1
I see a lot of folks posting about that NYTimes article. So I'm just going to say something I know you all already know, but is important.
You cannot infer the effect on unemployment of majoring in one topic vs another by comparing the unemployment rates of folks who chose those majors.
10.08.2025 21:05 — 👍 25 🔁 5 💬 3 📌 0
Imagine if we had something like cmdstan with Zig — take advantage of compile time execution
10.08.2025 22:02 — 👍 1 🔁 0 💬 0 📌 0
llms have great potential but incentives favor being stupid. to “know less”, you need abstraction — omit some details for clearer picture, keep a recipe you can unfold to go back. lose that recipe, and you’re doomed to forever treat the symptoms, while the symptoms get ever more complicated
10.08.2025 09:50 — 👍 53 🔁 2 💬 2 📌 0
Noooo you must carefully engineer your prompt in a way that properly accommodates the properties of the token-based model space, the better to manage the quasi-aliasing that happens at token boundaries; moreover the probabilistic character of model outputs makes the tool a poor choice for the evaluation of certain deterministic world-knowledge topics; furthermo
34%
34%
I don't trust this fucken thing
I don't trust this fucken thing
14%
14%
0.1%
Ю score
55
2%
2%
0.1%
70
85
100
115
130
145
08.08.2025 11:37 — 👍 659 🔁 116 💬 5 📌 7
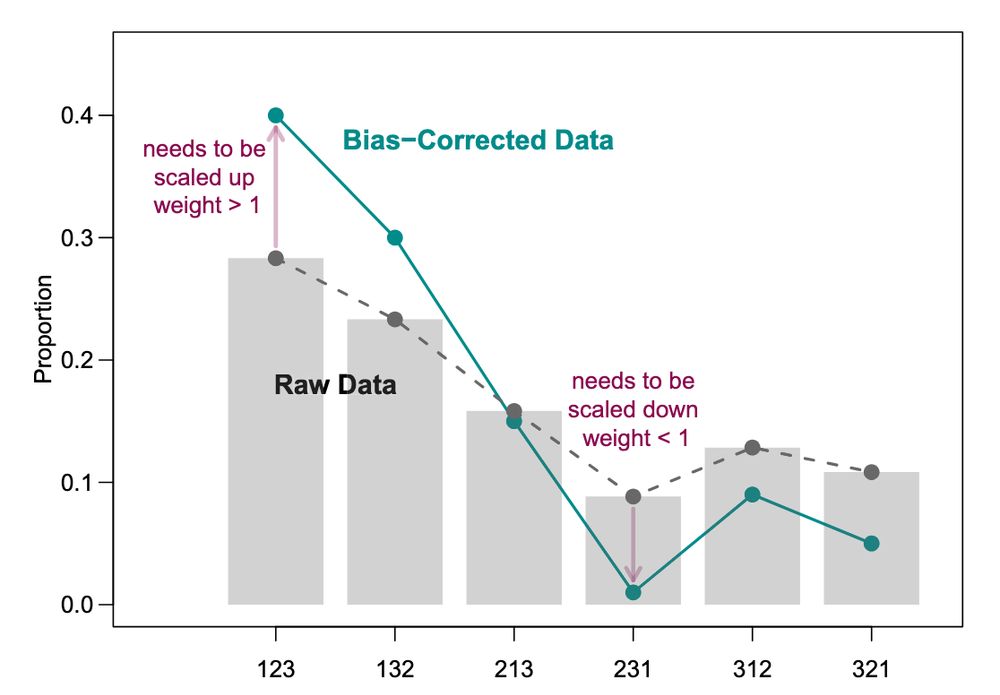
Currently in FirstView: In “Addressing Measurement Errors in Ranking Questions for the Social Sciences,” Yuki Atsusaka and @sysilviakim.bsky.social examine the statistical consequences of measurement error and introduce a framework for improving ranking data analysis.
17.07.2025 17:45 — 👍 10 🔁 5 💬 1 📌 0
Added the 2025 models using data as of yesterday's games:
blog.damoncroberts.io/posts/baseba...
30.07.2025 01:31 — 👍 0 🔁 0 💬 0 📌 0
That’s great, thank you!
28.07.2025 23:48 — 👍 1 🔁 0 💬 0 📌 0
It’s not the Rockies.
28.07.2025 23:18 — 👍 3 🔁 0 💬 1 📌 0
Hopefully the post will be ready tomorrow!
28.07.2025 23:18 — 👍 0 🔁 0 💬 1 📌 0
Bayesian modeling in Julia: Turing and Stan – A neglected blog
A quick blog post of me comparing the benchmarks and syntax of Bradley-Terry models to compute power rankings of MLB teams in Turing.jl and cmdstanr:
blog.damoncroberts.io/posts/julia_...
28.07.2025 22:55 — 👍 16 🔁 1 💬 4 📌 1
sure! could be cool.
27.07.2025 21:20 — 👍 0 🔁 0 💬 1 📌 0
Benchmarks?
27.07.2025 21:13 — 👍 0 🔁 0 💬 1 📌 0
2025 MLB model
27.07.2025 21:05 — 👍 2 🔁 0 💬 1 📌 1
Still not as bad as Microsoft Teams
26.07.2025 21:24 — 👍 746 🔁 176 💬 12 📌 5
The pipe is very very nice.
25.07.2025 17:30 — 👍 0 🔁 0 💬 0 📌 0
Maybe the tidyverse is a little bloated
22.04.2025 15:18 — 👍 34 🔁 2 💬 6 📌 0
The tidyversification of R honestly is the biggest reason I don’t touch the language since leaving academia. Even if I were still there, I’d be really annoying about it and say we shouldn’t do it if we care about replication. data tables exists and is great, but everything is built on tidyverse now
25.07.2025 17:19 — 👍 1 🔁 0 💬 1 📌 0
For ultimate performance: time to learn binary baayybee!
25.07.2025 16:29 — 👍 2 🔁 0 💬 1 📌 0
Im not gonna write assembly. But, dplyr built on a ton of dependencies built on base R built on an interpreter for C just to change a string to an integer.
25.07.2025 15:14 — 👍 2 🔁 1 💬 2 📌 0
All I’m saying is: the Kalman filter was used for the Apollo missions, we should be capable of running some models locally. If not, it’s not because the data is too large or the hardware sucks. It might be the endless appetite for extra layers of abstraction away from the code doing the actual work
25.07.2025 15:11 — 👍 6 🔁 1 💬 1 📌 0
YouTube video by ThePrimeTime
Why Performance Actually Matters (The Standup)
youtu.be/RlTVMi4JzZA?...
21.07.2025 18:04 — 👍 0 🔁 0 💬 0 📌 0
YouTube video by ThePrimeTime
Why Performance Actually Matters (The Standup)
“I should just stick with a coding language because it works, but to not move with my feet or demand it be more performant because a little bit more latency doesn’t matter enough to justify the effort.“
A great articulation of why this perspective is something we should push back on:
21.07.2025 18:04 — 👍 0 🔁 0 💬 1 📌 0
Senior Lecturer in Comparative Politics, University of Bath, author of Making Gender Salient: From Gender Quota Laws to Policy bit.ly/3wzcTGM. Editor, LSQ. gender quotas, parties, gender & far right, mental load #academicmama https://anacweeks.github.io/
http://theverge.com covers life in the future.
networks, contagion, causality
faculty at MIT
Computational Social Scientist, YIMBY, Crank
Tired but hydrated. Senior Data Analyst for the Boston Red Sox. Recovering physicist. Formerly: Argonne, CERN (ATLAS), NIU, Murray State, St. Louis-ish
Data Scientist. Poli sci PhD. Cyclist (Gravel, MTB, road). Bayes, causal inference, etc. Also: cats, food opinions. Views & opinions my own. Not investment advice. He/him
Computational social science prof at LSE @lsemethodology.bsky.social
Research on US law & courts, public policy, political economy
Anthropologist - Bayesian modeling - organic modem converting poetry into code - cat and cooking content too - Director @ MPI for evolutionary anthropology https://www.eva.mpg.de/ecology/staff/richard-mcelreath/
Probabilistic modeling and machine learning nerd
Social Psych PhD, quantitative methods
Data Scientist Manager, Comscore - Innovation Research Team.
Sworn in Data Janitor
blog: http://brodrigues.co
youtube: http://is.gd/NjybjH
mastodon: http://is.gd/nOyGht
twitter: @brodriguesco
"nix solves this"
Poli Sci PhD blogging about Bayes and data:
www.bwilden.com
Runner, biker, hiker. Software engineer @DeepMind, and open source enthusiast. Sometimes crafts things out of wood. he/his.
Doing Bayesian stuff in #rustlang and #julialang. Seattle
Full Professor of Computational Statistics at TU Dortmund University
Scientist | Statistician | Bayesian | Author of brms | Member of the Stan and BayesFlow development teams
Website: https://paulbuerkner.com
Opinions are my own
Professor of Statistics, Bayesian, computational systems biologist and functional programmer, https://darrenjw.github.io/
Building Astral: Ruff, uv, and other high-performance Python tools, written in Rust.
Statistics, machine learning, causal inference, health