
Interested in doing a Ph.D. to work on building models of the brain/behavior? Consider applying to graduate schools at CU Anschutz:
1. Neuroscience www.cuanschutz.edu/graduate-pro...
2. Bioengineering engineering.ucdenver.edu/bioengineeri...
You could work with several comp neuro PIs, including me.
27.09.2025 20:30 — 👍 52 🔁 30 💬 1 📌 4

We have one poster in this afternoon's session at #ICML2025 (West Exhibition Hall B2-B3, W-414).
Unfortunately, none of the authors could attend the conference, but feel free to contact me if you have any questions!
icml.cc/virtual/2025...
16.07.2025 13:16 — 👍 1 🔁 0 💬 0 📌 0
10/10 This work was a wonderful collaboration with Kumar Tanmay, Seok-Jin Lee, Ayush Agrawal, Hamid Palangi, Kumar Ayush, Ila Fiete, and Paul Pu Liang.
📘 Paper: arxiv.org/pdf/2507.05418
🌐 Project: jd730.github.io/projects/Geo...
#LLM #MultilingualAI #Reasoning #NLP #AI #LanguageModels
15.07.2025 15:46 — 👍 1 🔁 1 💬 0 📌 0
9/10
This matters:
✔️ For global inclusivity
✔️ For users who expect interpretable reasoning in their native language
✔️ For fair multilingual evaluation
🧠 LLMs shouldn’t just give the right answer—they should think in your language.
15.07.2025 15:44 — 👍 0 🔁 0 💬 1 📌 0

8/10
📊 On MGSM, BRIDGE improves both math and language accuracy in medium- and low-resource languages.
Even better:
• It maintains performance in English
• It succeeds where naive post-training and SFT or GRPO alone fail (especially in math).
15.07.2025 15:43 — 👍 0 🔁 0 💬 1 📌 0

7/10
We also propose BRIDGE, a method that balances:
• Supervised fine-tuning for task-solving
• GRPO with a language consistency reward in reasoning.
This decouples multilingual ability from reasoning ability.
15.07.2025 15:43 — 👍 0 🔁 0 💬 1 📌 0

6/10
GeoFact-X lets us evaluate not just what models predict, but how they think.
We measure:
• Answer correctness
• Reasoning quality
• Language consistency
Models do better on region-language aligned pairs vs. mismatched ones.
15.07.2025 15:41 — 👍 0 🔁 0 💬 1 📌 0

5/10
We introduce GeoFact-X, the first benchmark to evaluate language-consistent reasoning.
🌍 It includes multilingual CoT QA across 5 regions × 5 languages (EN, JA, SW, HI, TH)=25 region-language pairs.
Questions are grounded in regional facts, each with step-by-step reasoning.
15.07.2025 15:40 — 👍 1 🔁 0 💬 1 📌 0

4/10
We evaluate leading LLMs (e.g., Qwen2.5, LLaMA-3, Gemma-3, DeepSeek-R1) on MGSM with native-language CoT.
🔍 Result:
Many models get the correct answer but default to English for reasoning, even when prompted otherwise.
That’s a serious misalignment.
15.07.2025 15:40 — 👍 3 🔁 0 💬 1 📌 0
3/10
Existing multilingual benchmarks (e.g., MGSM, MMLU-ProX) only evaluate if the final answer is correct in the target language.
They don’t measure if the reasoning process (CoT) is in the same language.
That gap matters for transparency, fairness, and inclusivity.
15.07.2025 15:39 — 👍 1 🔁 0 💬 1 📌 0
2/10
Today’s LLMs are multilingual-ish.
They often generate answers in the input language, but their reasoning steps (chain-of-thought) default to English, especially after post-training on English data.
15.07.2025 15:39 — 👍 1 🔁 0 💬 1 📌 0

🧵1/10
LLMs can answer in many languages.
But do they think in them?
Even when prompted in Swahili or Thai, models often switch to English for reasoning.
This breaks interpretability and trust.
So we ask: Can LLMs reason in the input language?
15.07.2025 15:39 — 👍 2 🔁 0 💬 1 📌 0

If I remember correctly, that was also the first CV conference with over 1000 papers, and people already felt overwhelmed. Now, CVPR 2025 has 2800+ papers, and #NeurIPS2024 had 4497. It’s becoming nearly impossible to discover hidden gems while wandering poster sessions. 2/2
12.06.2025 00:26 — 👍 1 🔁 0 💬 0 📌 0

We learned the bitter lession that a poster should be checked before the poster session #ICLR2025.
Thank you all for coming and we are delight that you enjoyed our mistakes.
We are also highly appeciate authors of MMSearch allowing us to use their panel.
26.04.2025 10:32 — 👍 2 🔁 0 💬 0 📌 0

📢 Excited to share that I will be presenting our paper on Neuro-Inspired SLAM at #ICLR2025 TOMORROW!
🗓 Saturday, April 26th 10:00 - 12:30 pm
📍 Hall 3 (Poster #55)
jd730.github.io/projects/FAR...
25.04.2025 13:31 — 👍 1 🔁 0 💬 0 📌 0
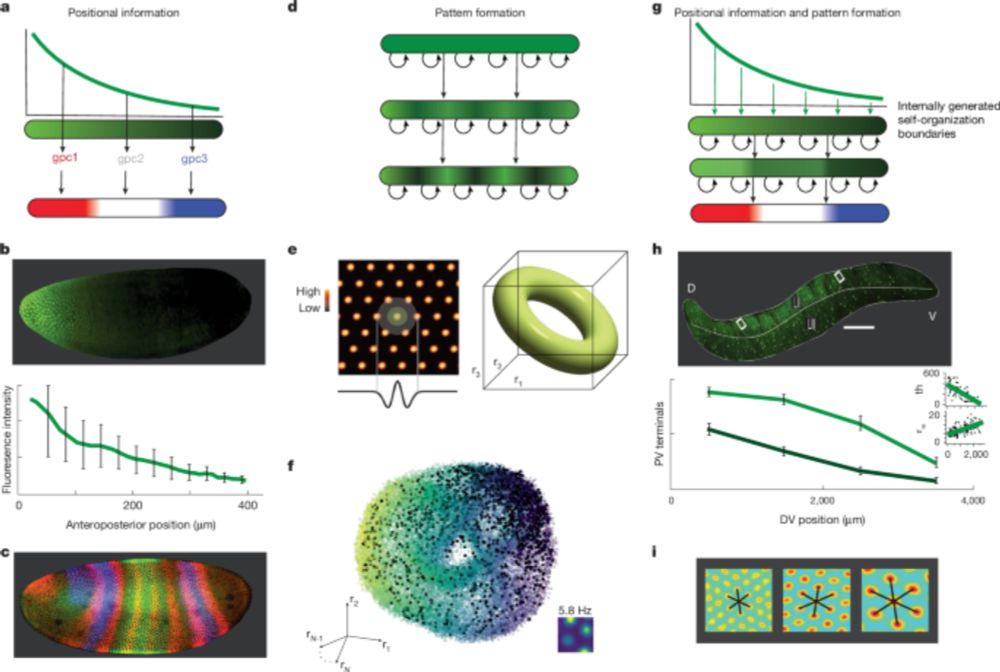
Global modules robustly emerge from local interactions and smooth gradients - Nature
The principle of peak selection is described, by which local interactions and smooth gradients drive self-organization of discrete global modules.
1/ Our paper appeared in @Nature today! www.nature.com/articles/s41... w/ Fiete Lab and @khonamikail.bsky.social .
Explains emergence of multiple grid cell modules, w/ excellent match to data! Novel mechanism for applying across vast systems from development to ecosystems. 🧵👇
19.02.2025 23:20 — 👍 97 🔁 32 💬 2 📌 2
Researcher at Google and CIFAR Fellow, working on the intersection of machine learning and neuroscience in Montréal (academic affiliations: @mcgill.ca and @mila-quebec.bsky.social).
Computational Neuroscientist + ML Researcher | Control theory + deep learning to understand the brain | PhD Candidate @ MIT | (he) 🍁
Doing cybernetics (without being allowed to call it that). Assistant Professor @ Brown. Previously: IBM Research, MIT, Rutgers. https://kozleo.github.io/
PhD Student at MIT Brain and Cognitive Sciences studying Computational Neuroscience / ML. Prev Yale Neuro/Stats, Meta Neuromotor Interfaces
PhD student @csail.mit.edu 🤖 & 🧠
The Department of Imaging Neuroscience, home of the Functional Imaging Laboratory (The FIL), is part of the Institute of Neurology, UCL
Principal Researcher @ Microsoft Research.
AI, RL, cog neuro, philosophy.
www.momen-nejad.org
asst prof @Stanford linguistics | director of social interaction lab 🌱 | bluskies about computational cognitive science & language
Cognitive scientist studying play & problem solving
jchu10.github.io
ELLIS PhD Fellow @belongielab.org | @aicentre.dk | University of Copenhagen | @amsterdamnlp.bsky.social | @ellis.eu
Multi-modal ML | Alignment | Culture | Evaluations & Safety| AI & Society
Web: https://www.srishti.dev/
https://unireps.org
Discover why, when and how distinct learning processes yield similar representations, and the degree to which these can be unified.
Social Reasoning/Cognition + AI, Postdoc at NVIDIA | Previously @ai2.bsky.social | PhD from Seoul Natl Univ.
http://hyunwookim.com
Incoming assistant professor at JHU CS & Young Investigator at AI2
PhD at UNC
https://j-min.io
#multimodal #nlp
Linguist in AI & CogSci 🧠👩💻🤖 PhD student @ ILLC, University of Amsterdam
🌐 https://mdhk.net/
🐘 https://scholar.social/@mdhk
🐦 https://twitter.com/mariannedhk
CS PhD @UCLAComSci 🧸 | Prev @AIatMeta @MSFTResearch @AmazonScience @uclamath | Improving data for efficiency, robustness and performance
@San Francisco
https://sites.google.com/g.ucla.edu/yuyang/home
Professor for CS at the Tuebingen AI Center and affiliated Professor at MIT-IBM Watson AI lab - Multimodal learning and video understanding - GC for ICCV 2025 - https://hildekuehne.github.io/
Strengthening Europe's Leadership in AI through Research Excellence | ellis.eu
Professor at Michigan | Voxel51 Co-Founder and Chief Scientist | Creator, Builder, Writer, Coder, Human
Computer Vision research group @ox.ac.uk























