
Hello all! 👋
I’m delighted to share a 🚨 new preprint 🚨:
“Active Evaluation of General Agents: Problem Definition and Comparison of Baseline Algorithms”.
A paper thread! 🤩📄🧵 1/N

@lukemarris.bsky.social
Research Engineer at Google DeepMind. Interests in game theory, reinforcement learning, and deep learning. Website: https://www.lukemarris.info/ Google Scholar: https://scholar.google.com/citations?user=dvTeSX4AAAAJ
Hello all! 👋
I’m delighted to share a 🚨 new preprint 🚨:
“Active Evaluation of General Agents: Problem Definition and Comparison of Baseline Algorithms”.
A paper thread! 🤩📄🧵 1/N
Hello everyone 👋 Good news!
🚨 Our Game Theory & Multiagent Systems team at Google DeepMind is hiring! 🚨
.. and we have not one, but two open positions! One Research Scientist role and one Research Engineer role. 😁
Please repost and tell anyone who might be interested!
Details in thread below 👇
Our team is hiring REs (job-boards.greenhouse.io/deepmind/job...) and RSs (job-boards.greenhouse.io/deepmind/job...). Please apply if you are interested in game theory / multiagent.
29.09.2025 08:29 — 👍 6 🔁 0 💬 1 📌 0
[🧵9/N] And, an interactive demo is available here: siqi.fr/public/re-ev...
22.04.2025 15:48 — 👍 3 🔁 1 💬 0 📌 0
Frontier models are often compared on crowdsourced user prompts - user prompts can be low-quality, biased and redundant, making "performance on average" hard to trust.
Come find us at #ICLR2025 to discuss game-theoretic evaluation (shorturl.at/0QtBj)! See you in Singapore!
😅😂 Called out!
17.04.2025 17:37 — 👍 3 🔁 0 💬 0 📌 0
[🧵8/N] Come see our poster on 2025/04/24 at Poster Location: Hall 3 + Hall 2B #440.
iclr.cc/virtual/2025... #IRL
[🧵7/N] Big thanks to the team @GoogleDeepMind! Siqi Liu (@liusiqi.bsky.social), Ian Gemp (@drimgemp.bsky.social), Luke Marris, Georgios Piliouras, Nicolas Heess, Marc Lanctot (@sharky6000.bsky.social)
17.04.2025 16:12 — 👍 2 🔁 0 💬 1 📌 1
[🧵6/N] In summary: Current open-ended LLM evals risk being brittle. Our game-theoretic framework w/ affinity entropy provides more robust, intuitive, and interpretable rankings, crucial for guiding real progress! 🧠 Check it out & let us know your thoughts! 🙏
arxiv.org/abs/2502.20170

[🧵5/N] Does it work? YES! ✅On real data (arena-hard-v0.1), our method provides intuitive rankings robust to redundancy. We added 500 adversarial prompts targeting the top model – Elo rankings tanked, ours stayed stable! (See Fig 3 👇). Scales & gives interpretable insights!
17.04.2025 16:12 — 👍 3 🔁 0 💬 1 📌 0[🧵4/N] But game theory isn't magic - standard methods often yield multiple equilibria & aren't robust to redundancy. Key innovation: We introduce novel solution concepts + 'Affinity Entropy' to find unique, CLONE-INVARIANT equilibria! ✨(No more rank shifts just bc you added copies!)
17.04.2025 16:12 — 👍 3 🔁 0 💬 1 📌 0[🧵3/N] So, what's our fix? GAME THEORY! 🎲 We reframe LLM evaluation as a 3-player game: a 'King' model 👑 vs. a 'Rebel' model 😈, with a 'Prompt' player selecting tasks that best differentiate them. This shifts focus from 'average' performance to strategic interaction. #GameTheory #Evaluation
17.04.2025 16:12 — 👍 2 🔁 0 💬 1 📌 0[🧵2/N] Why the concern? Elo averages performance. If prompt sets are biased or redundant (intentionally or not!), rankings can be skewed. 😟 Our simulations show this can even reinforce biases, pushing models to specialize narrowly instead of improving broadly (see skill entropy drop!). 📉 #EloRating
17.04.2025 16:12 — 👍 2 🔁 0 💬 1 📌 0
[🧵1/N] Thrilled to share our work "Re-evaluating Open-Ended Evaluation of Large Language Models"! 🚀 Popular LLM leaderboards (think Elo/Chatbot Arena) are useful, but are they telling the whole story? We find issues w/ redundancy & bias. 🤔
Paper @ ICLR 2025: arxiv.org/abs/2502.20170 #LLM #ICLR2025
Working at the intersection of social choice and learning algorithms?
Check out the 2nd Workshop on Social Choice and Learning Algorithms (SCaLA) at @ijcai.bsky.social this summer.
Submission deadline: May 9th.
I attended last year at AAMAS and loved it! 👍
sites.google.com/corp/view/sc...
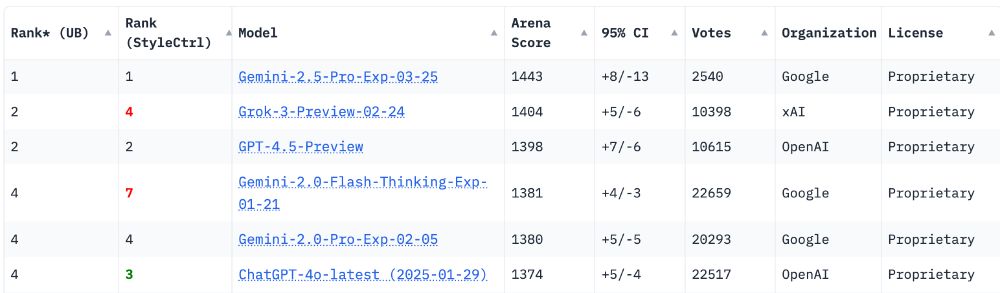

🥁Introducing Gemini 2.5, our most intelligent model with impressive capabilities in advanced reasoning and coding.
Now integrating thinking capabilities, 2.5 Pro Experimental is our most performant Gemini model yet. It’s #1 on the LM Arena leaderboard. 🥇
Looking for a principled evaluation method for ranking of *general* agents or models, i.e. that get evaluated across a myriad of different tasks?
I’m delighted to tell you about our new paper, Soft Condorcet Optimization (SCO) for Ranking of General Agents, to be presented at AAMAS 2025! 🧵 1/N

[🧵13/N] It is also possible to plot each task's contribution to the deviation rating, enabling to quickly see the trade-offs between the models. Negative bars mean worse than equilibrium at that task. So Sonnet is relatively weaker at "summarize" and Llama is relatively weaker at "LCB generation".
24.02.2025 14:00 — 👍 1 🔁 0 💬 0 📌 0[🧵12/N] We are convinced this is a better approach than Elo or simple averaging. Please read the paper for more details! 🤓
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0[🧵11/N] Our work proposes the first rating method, “Deviation Ratings”, that is both dominant- and clone-invariant in fully general N-player, general-sum interactions, allowing us to evaluate general models in a theoretically grounded way. 👏
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0[🧵10/N] A three-player game with two-symmetric models players try to beat each other (by playing strong models) on a task selected by task player incentivised to separate models is an improved formulation. 👍 However Nash Averaging is only defined for two-player zero-sum games. 😭
18.02.2025 10:49 — 👍 3 🔁 0 💬 1 📌 0[🧵9/N] Unfortunately, a two-player zero-sum interaction is limiting. For example, if no model can solve a task, the task player would only play that impossible task, resulting in uninteresting ratings. 🙁
18.02.2025 10:49 — 👍 1 🔁 0 💬 1 📌 0[🧵8/N] This is hugely powerful for two reasons. 1) When including tasks in the evaluation set one can be maximally inclusive: redundancies are axiomatically ignored which simplifies curation for evaluation. 2) Salient strategies are automatically reweighted according to their significance. 💪
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0[🧵7/N] This approach is provably clone- and dominant-invariant: adding copies of tasks and models, or adding dominated tasks and models, does not influence the rating *at all*. The rating is invariant to two types of redundancies! 🤩 Notably, neither an average nor Elo have these properties.
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0
[🧵6/N] A previous approach, called Nash Averaging (arxiv.org/abs/1806.02643), formulated the problem as a two-player zero-sum game where a model player maximizes performance on tasks by playing strong models and a task player minimises performance by selecting difficult tasks. ♟️
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0[🧵5/N] Therefore, there is a strategic decision on which tasks are important, and which model is the best. Where there is a strategic interaction, it can be modeled as a game! Model players select models, and task players select tasks. The players may play distributions to avoid being exploited.
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0[🧵4/N] The tasks may be samples from an infinite space of tasks. Is the distribution of prompts submitted to LMSYS representative of the diversity and utility of skills we wish to evaluate LLMs on? Can we even agree on such a distribution, if one even exists? 🤔
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0[🧵3/N] Furthermore, the set of tasks a model is evaluated on may not be curated. For example, the frequency of tasks may not be proportional to their importance. Tasks may also differ in difficulty and breadth of underlying skills measured. 📏
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0[🧵2/N] Game-theoretic ratings are useful for evaluating generalist models (including LLMs), where there are many underlying skills/tasks to be mastered. Usually no single model is dominant on all metrics. 🥇
18.02.2025 10:49 — 👍 2 🔁 0 💬 1 📌 0
[🧵1/N] Please check out our new paper (arxiv.org/abs/2502.11645) on game-theoretic evaluation. It is the first method that results in clone-invariant ratings in N-player, general-sum interactions. Co-authors: @liusiqi.bsky.social , Ian Gemp, Georgios Piliouras, @sharky6000.bsky.social 🎉
18.02.2025 10:49 — 👍 15 🔁 2 💬 2 📌 3